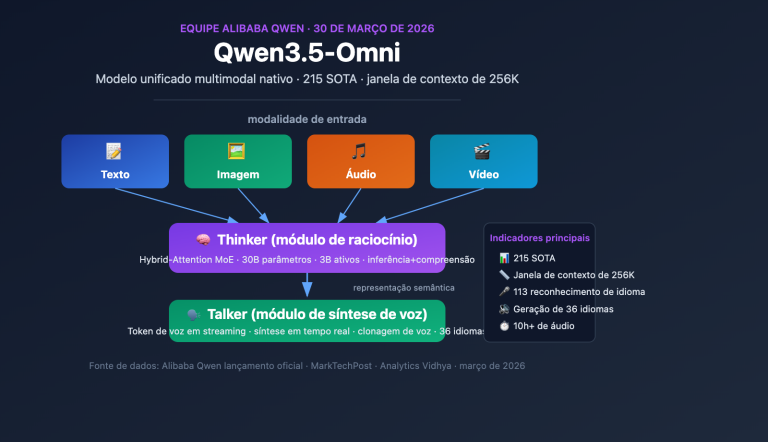
Interpretando o modelo multimodal nativo Qwen3.5-Omni: arquitetura Thinker-Talker implementa processamento unificado de 4 modalidades e reconhecimento de voz em 113 idiomas
Nota do autor: Detalhamento da arquitetura Thinker-Talker MoE, janela de contexto de 256K, capacidades de codificação de áudio e vídeo e a habilidade emergente de Audio-Visual Vibe Coding do modelo multimodal nativo Qwen3.5-Omni da Alibaba. A equipe do Qwen da Alibaba lançou oficialmente o Qwen3.5-Omni em 30 de março de 2026, um modelo multimodal nativo…