站长注:详解如何突破ChatGPT Plus对o4-mini模型的使用限制,通过API易平台实现无限次数使用和按量计费,充分发挥多模态能力。
OpenAI的o4-mini模型凭借其强大的推理能力和多模态处理能力,成为许多专业用户的首选工具。然而,ChatGPT Plus会员对该模型的使用有严格限制,无法满足需要频繁使用该模型的用户需求。本文将详细介绍如何通过API调用方式,不受限制地使用o4-mini模型,并按实际用量计费,让您充分发挥这一强大模型的潜力。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持OpenAI o4-mini模型无限次数调用,多模态能力助力视觉理解与复杂推理
注册可送 1.1 美金额度起,约 300万 Tokens 额度体验。立即免费注册
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。
o4-mini模型使用限制背景介绍
ChatGPT Plus会员在使用o4-mini模型时面临严格的使用限制,这对需要频繁使用该模型的专业用户造成了不小的困扰。OpenAI实施这些限制的主要原因包括:
-
资源分配管理:o4-mini虽然是轻量版模型,但仍需要较多计算资源,特别是处理图像等多模态内容时。限制使用频率可以更均衡地分配计算资源。
-
服务质量保障:通过限制单个用户的使用频率,确保所有用户都能获得稳定的服务体验,避免系统过载。
-
商业模式考量:引导高频率使用者转向API付费方式,支持OpenAI的持续研发投入。
这些限制虽然合理,但对于以下用户群体来说,ChatGPT Plus的使用限制可能成为严重的生产力障碍:
- 需要处理大量图文内容的创作者:如设计师、内容营销专家等
- 依赖视觉分析的研究人员:如医疗影像分析、遥感数据处理等领域
- 开发多模态应用的程序员:需要频繁测试图像识别和理解功能
- 进行大规模数据分析的企业用户:需要批量处理包含图表和可视化数据的报告
对于这些用户,API接口提供了不受ChatGPT Plus使用限制的理想解决方案,让您能够真正按需使用o4-mini模型的全部能力。
o4-mini模型核心优势与应用价值
o4-mini作为OpenAI的轻量级多模态模型,具有一系列令人印象深刻的核心优势,这些优势使其成为许多应用场景的理想选择:
卓越的多模态处理能力
与仅支持文本的o3-mini不同,o4-mini具备强大的多模态能力:
- 图像理解与分析:能够识别、描述和分析图像中的内容和细节
- 视觉推理:可以回答关于图像中的问题,理解图像上下文
- 图文结合处理:无缝整合文本和图像信息,提供综合分析
- 图表与数据可视化解读:能够解读科学图表、统计图形和商业数据可视化
这种多模态能力使o4-mini在处理现实世界的复杂信息时具有显著优势,特别是在需要视觉理解的场景中。
增强的推理性能
o4-mini在推理能力方面取得了显著进步:
- 思维链架构:将复杂问题分解为逻辑步骤,提高透明度并减少推理错误35%
- 基准测试表现:使用Python的AIME 2025通过率达99.5%,不使用工具的AIME 2025准确率达92.7%
- 逻辑推理:在复杂逻辑问题上表现出色,能够追踪多步骤推理过程
- 科学与数学:在科学和数学领域的问题解决上显著优于前代模型
工具集成与使用
o4-mini支持多种工具的智能集成:
- 网页浏览:可以访问和理解网页内容
- Python代码执行:能够编写和执行Python代码解决问题
- 文件分析:处理和分析各种格式的文件
- 图像生成:创建符合描述的视觉内容
性能与效率优化
o4-mini在保持强大功能的同时,实现了显著的效率提升:
- 处理速度:比o3-mini快25%,响应时间更短
- 能源效率:同等或更优性能下能源消耗减少40%
- 成本优化:token消耗减少30%,使开发者更容易控制成本
- 技术规格:200,000个tokens的上下文窗口,每次请求支持最多100,000个tokens的输出
这些性能优势使o4-mini成为一个既强大又经济的选择,特别适合需要平衡性能和成本的应用场景。
通过API实现o4-mini模型无限制使用的解决方案
想要突破ChatGPT Plus对o4-mini的使用限制,API调用是最理想的解决方案。通过API易平台,您可以简单高效地实现这一目标。
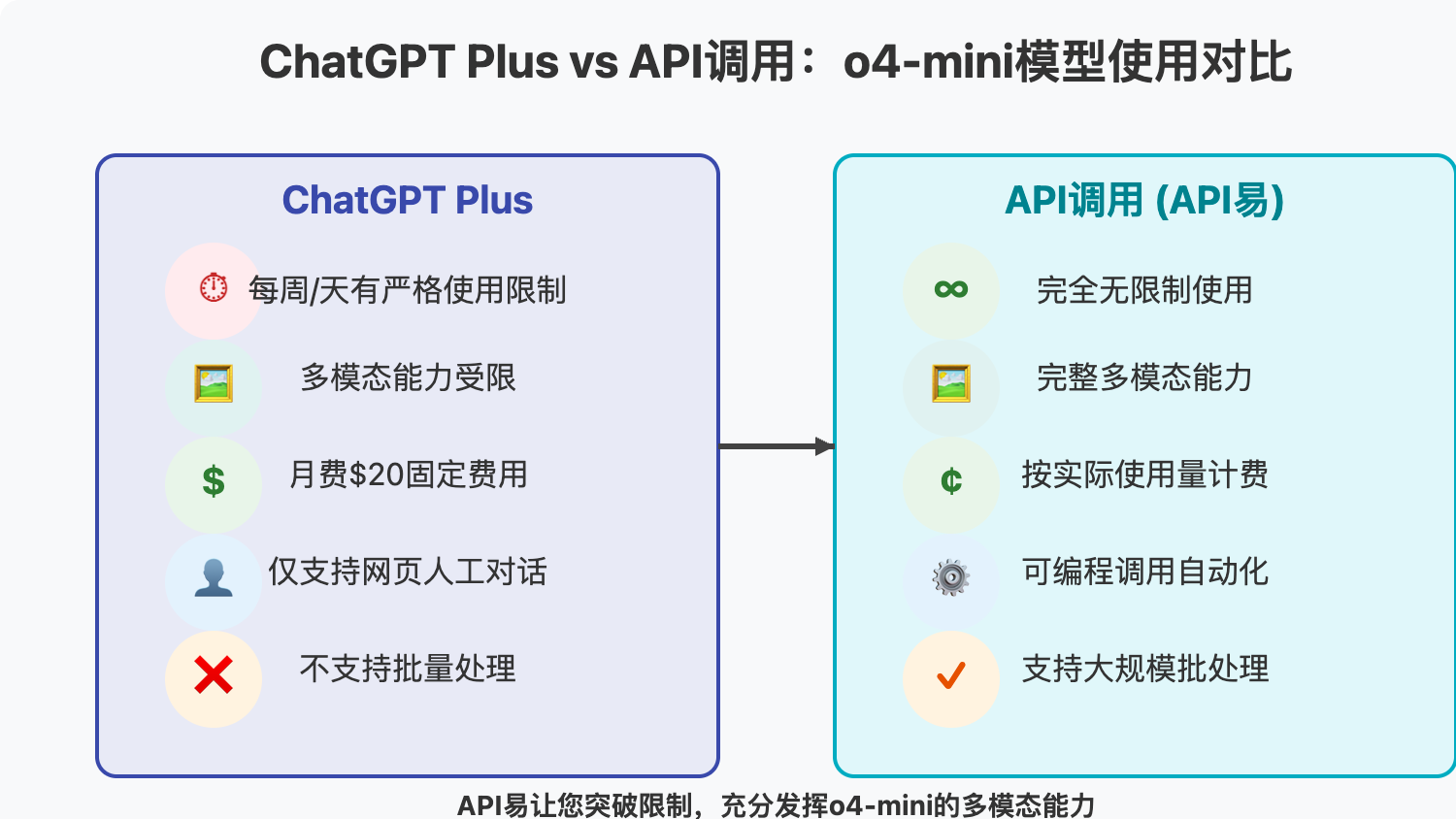
API调用vs ChatGPT Plus对比
| 特性 | ChatGPT Plus | API调用(通过API易) |
|---|---|---|
| 使用次数 | 每周/每天有限制 | 完全无限制,按需使用 |
| 多模态能力 | 受限使用 | 完全开放,无限制处理图像 |
| 计费方式 | 月费$20,固定费用 | 按token使用量计费,更经济 |
| 使用方式 | 网页界面,人工对话 | 可编程调用,支持自动化 |
| 批量处理 | 不支持 | 完全支持,可大规模处理 |
| 集成能力 | 不支持应用集成 | 完全支持API集成到任何应用 |
| 图像处理量 | 有限制 | 可处理无限数量的图像输入 |
通过API易访问o4-mini模型的步骤
-
注册API易账户:
- 访问API易注册页面
- 完成简单注册流程(约需1分钟)
- 新用户赠送1.1美金初始额度(约300万tokens体验)
-
获取API密钥:
- 登录账户后台,进入API密钥管理
- 创建新的API密钥
- 妥善保存生成的密钥,它将用于认证API请求
-
了解API参数和格式:
- o4-mini支持多模态输入,需要使用特定格式
- 熟悉图像输入的参数设置
- 了解上下文长度和输出限制
-
集成API到您的应用:
- API易提供OpenAI兼容接口,可使用任何支持OpenAI的库
- 修改API端点为API易的地址
- 支持多种编程语言:Python、JavaScript、Java、Go等
-
测试多模态功能:
- 使用提供的示例代码测试图像处理能力
- 验证API连接和认证是否正常工作
- 测试o4-mini模型的响应是否符合预期
通过这种方式,您可以完全摆脱ChatGPT Plus的使用限制,充分发挥o4-mini的多模态能力和推理优势。

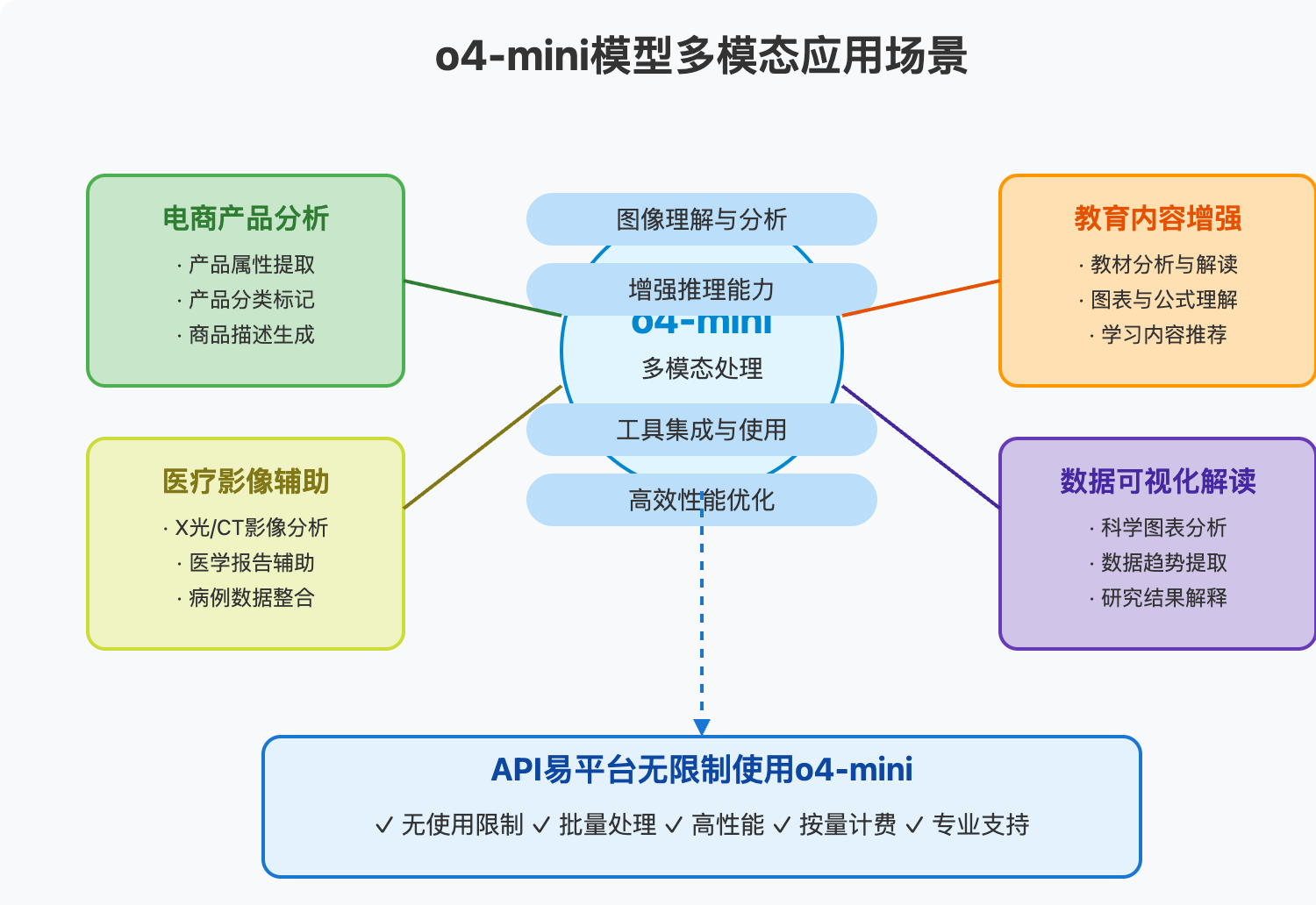
实战案例:o4-mini模型在多模态场景中的应用
o4-mini的多模态能力和增强推理使其在多种应用场景中表现出色。通过API调用,这些能力可以被充分释放。以下是几个实战案例:
案例一:电商产品图像分析系统
某电商平台利用o4-mini模型构建了产品图像分析系统,自动化产品分类和属性提取:
import requests
import base64
import json
from io import BytesIO
from PIL import Image
url = "https://vip.apiyi.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer your-api-key" # 替换为您的API易API密钥
}
def analyze_product_image(image_path):
# 读取图像并转换为base64
with open(image_path, "rb") as image_file:
image_data = base64.b64encode(image_file.read()).decode('utf-8')
# 构建请求
data = {
"model": "o4-mini",
"messages": [
{"role": "system", "content": "你是一位专业的电商产品分析专家。请详细分析图像中的产品,提取关键属性,包括产品类别、品牌、颜色、材质、设计特点等。"},
{"role": "user", "content": [
{"type": "text", "text": "请分析这张产品图片,提取所有可见的产品属性,并建议合适的分类和标签:"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}}
]}
],
"temperature": 0.2
}
# 发送请求
response = requests.post(url, headers=headers, json=data)
return response.json()["choices"][0]["message"]["content"]
# 批量处理产品图片
import os
product_dir = "./product_images"
results = {}
for filename in os.listdir(product_dir):
if filename.endswith((".jpg", ".png", ".jpeg")):
image_path = os.path.join(product_dir, filename)
print(f"Analyzing {filename}...")
analysis = analyze_product_image(image_path)
results[filename] = analysis
# 保存分析结果
with open("product_analysis.json", "w") as f:
json.dump(results, f, indent=2)
该公司每天分析数千张产品图片,帮助自动化产品上架流程。通过API易平台调用o4-mini,他们能够以经济高效的方式处理无限量的图片,而ChatGPT Plus的限制将使这种大规模应用变得不可能。
案例二:医疗影像辅助分析
一家医疗科技公司利用o4-mini辅助放射科医生分析X光和CT影像:
import requests
import base64
import pandas as pd
from datetime import datetime
url = "https://vip.apiyi.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer your-api-key" # 替换为您的API易API密钥
}
def analyze_medical_image(image_path, patient_info):
# 读取图像并转换为base64
with open(image_path, "rb") as image_file:
image_data = base64.b64encode(image_file.read()).decode('utf-8')
# 构建医学专业提示词
prompt = f"""
患者信息:
- 年龄: {patient_info['age']}
- 性别: {patient_info['gender']}
- 主诉: {patient_info['chief_complaint']}
- 既往病史: {patient_info['medical_history']}
请作为放射科专家,分析这张医学影像。提供以下内容:
1. 影像观察所见
2. 可能的异常或病变
3. 鉴别诊断建议
4. 是否建议进一步检查
请注意,你的分析将辅助医生决策,但不应替代专业医生的判断。
"""
# 构建请求
data = {
"model": "o4-mini",
"messages": [
{"role": "system", "content": "你是一位经验丰富的放射科医学专家,擅长分析X光、CT和MRI等医学影像。请提供专业、详细且谨慎的分析。"},
{"role": "user", "content": [
{"type": "text", "text": prompt},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}}
]}
],
"temperature": 0.1
}
# 发送请求
response = requests.post(url, headers=headers, json=data)
return response.json()["choices"][0]["message"]["content"]
# 处理一批医学影像
cases_df = pd.read_csv("patient_cases.csv")
results = []
for index, row in cases_df.iterrows():
image_path = f"./medical_images/{row['image_id']}.jpg"
patient_info = {
'age': row['age'],
'gender': row['gender'],
'chief_complaint': row['chief_complaint'],
'medical_history': row['medical_history']
}
print(f"Processing case {row['case_id']}...")
analysis = analyze_medical_image(image_path, patient_info)
results.append({
'case_id': row['case_id'],
'image_id': row['image_id'],
'analysis_timestamp': datetime.now().strftime("%Y-%m-%d %H:%M:%S"),
'analysis_result': analysis
})
# 保存分析结果
results_df = pd.DataFrame(results)
results_df.to_csv("image_analysis_results.csv", index=False)
医疗团队每天需要处理上百个病例,o4-mini模型的多模态能力为医生提供了宝贵的辅助判断,加快了诊断过程。通过API调用方式,他们能够随时使用模型,不受ChatGPT Plus使用限制的影响。
案例三:教育内容的多模态理解
一家教育科技公司使用o4-mini模型自动分析和丰富教育材料:
import requests
import base64
import os
import json
url = "https://vip.apiyi.com/v1/chat/completions"
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer your-api-key" # 替换为您的API易API密钥
}
def analyze_educational_content(text_content, image_path=None):
messages = [
{"role": "system", "content": "你是一位教育内容专家,擅长分析教育材料,识别关键概念,提供额外的解释和学习资源建议。"}
]
if image_path:
# 包含图像的内容分析
with open(image_path, "rb") as image_file:
image_data = base64.b64encode(image_file.read()).decode('utf-8')
messages.append({
"role": "user",
"content": [
{"type": "text", "text": f"请分析以下教育内容和图表,识别关键概念,提供进一步的解释,以及如何将这些内容整合到课程中:\n\n{text_content}"},
{"type": "image_url", "image_url": {"url": f"data:image/jpeg;base64,{image_data}"}}
]
})
else:
# 纯文本内容分析
messages.append({
"role": "user",
"content": f"请分析以下教育内容,识别关键概念,提供进一步的解释,以及如何将这些内容整合到课程中:\n\n{text_content}"
})
# 构建请求
data = {
"model": "o4-mini",
"messages": messages,
"temperature": 0.3
}
# 发送请求
response = requests.post(url, headers=headers, json=data)
return response.json()["choices"][0]["message"]["content"]
# 处理教育材料目录
education_dir = "./educational_materials"
results = {}
for subject_folder in os.listdir(education_dir):
subject_path = os.path.join(education_dir, subject_folder)
if os.path.isdir(subject_path):
results[subject_folder] = []
for filename in os.listdir(subject_path):
file_path = os.path.join(subject_path, filename)
if filename.endswith(".txt"):
# 读取文本内容
with open(file_path, 'r') as file:
text_content = file.read()
# 检查是否有配套图像
image_path = None
image_name = filename.replace(".txt", ".jpg")
potential_image_path = os.path.join(subject_path, image_name)
if os.path.exists(potential_image_path):
image_path = potential_image_path
print(f"Analyzing {subject_folder}/{filename}...")
analysis = analyze_educational_content(text_content, image_path)
results[subject_folder].append({
'filename': filename,
'has_image': image_path is not None,
'analysis': analysis
})
# 保存分析结果
with open("educational_content_analysis.json", "w") as f:
json.dump(results, f, indent=2)
教育公司通过这种方式每月处理数千份教育材料,使教师能够更有效地准备课程和理解复杂概念。o4-mini的多模态能力使其能够同时理解文本和图表,提供全面的教育内容分析。
o4-mini模型API调用最佳实践
要充分利用o4-mini的多模态能力和推理性能,同时优化API使用成本,以下是一些最佳实践:
1. 多模态提示词优化
o4-mini处理图像和文本的能力需要特定的提示词策略:
- 具体的图像指令:明确指示模型应关注图像的哪些方面,例如"描述图中的主要对象"、"分析图表中的数据趋势"
- 结构化查询:对于复杂任务,将问题分解为多个小步骤,引导模型逐步分析
- 多维度分析请求:要求模型从多个角度分析图像,如"分析图像的视觉元素、情感表达和潜在含义"
# 优化的多模态提示词示例
messages = [
{"role": "system", "content": "你是一位专业的视觉分析专家,擅长解读图像中的详细信息和隐含含义。请系统地分析图像内容,先描述客观事实,再提供深入解读。"},
{"role": "user", "content": [
{"type": "text", "text": "请分析这张图片,按以下步骤进行:\n1. 描述主要可见元素和构图\n2. 分析色彩运用和视觉焦点\n3. 解读可能的主题和情感表达\n4. 评估这张图片在专业设计或营销中的潜在应用"},
{"type": "image_url", "image_url": {"url": "https://example.com/image.jpg"}}
]}
]
2. 图像处理参数优化
处理图像时的特殊考虑:
- 图像质量与大小:优化上传图像的分辨率和文件大小,平衡清晰度和API调用成本
- 批量处理策略:将多张相关图像组合在单次请求中,提高处理效率
- 图像格式选择:优先使用JPEG或WebP等高压缩比格式,减少传输数据量
- 图像预处理:在必要时对图像进行预处理,如裁剪、调整对比度,以突出重要信息
3. 参数调优
根据不同任务类型调整API参数:
| 参数 | 图像分析任务 | 创意生成任务 | 编程任务 |
|---|---|---|---|
| temperature | 0.1-0.3 | 0.6-0.8 | 0.2-0.4 |
| top_p | 0.1-0.5 | 0.8-1.0 | 0.5-0.7 |
| max_tokens | 中等 | 较高 | 根据代码复杂度定 |
# 图像分析任务的参数设置
data = {
"model": "o4-mini",
"messages": messages,
"temperature": 0.2,
"top_p": 0.3,
"max_tokens": 1500
}
# 创意生成任务的参数设置
data = {
"model": "o4-mini",
"messages": messages,
"temperature": 0.7,
"top_p": 0.9,
"max_tokens": 2000
}
4. 成本控制与并发优化
优化API使用成本和效率的策略:
- 缓存图像分析结果:对于反复使用的相同图像,缓存分析结果避免重复请求
- 分批处理大量图像:设计合理的批处理策略,避免系统过载
- 并发请求管理:实施请求排队和流控机制,优化大规模处理
- 响应长度控制:通过明确的提示词和参数设置,控制输出token数量
# 实现简单缓存机制
import hashlib
import pickle
import os
def get_image_hash(image_path):
"""生成图像的唯一哈希值"""
with open(image_path, "rb") as f:
return hashlib.md5(f.read()).hexdigest()
def cached_image_analysis(image_path, prompt, cache_dir="./cache"):
"""带缓存的图像分析"""
# 创建缓存目录
os.makedirs(cache_dir, exist_ok=True)
# 生成唯一缓存键
image_hash = get_image_hash(image_path)
prompt_hash = hashlib.md5(prompt.encode()).hexdigest()
cache_key = f"{image_hash}_{prompt_hash}"
cache_path = os.path.join(cache_dir, f"{cache_key}.pkl")
# 检查缓存
if os.path.exists(cache_path):
with open(cache_path, "rb") as f:
return pickle.load(f)
# 缓存未命中,调用API
result = call_image_analysis_api(image_path, prompt) # 实际API调用函数
# 保存到缓存
with open(cache_path, "wb") as f:
pickle.dump(result, f)
return result
为什么选择「API易」o4-mini模型API服务
在众多OpenAI API提供商中,API易平台具有独特的优势,特别适合需要大量使用o4-mini模型的用户:
1. 稳定可靠的多模态服务
- 官方同源转发:直接对接OpenAI官方API,确保多模态能力与官方一致
- 高性能图像处理:优化的图像传输和处理链路,确保多模态请求的高效处理
- 不限速、不限并发:无论请求量多大,始终保持稳定的响应速度
- 全球加速:多节点部署,确保全球范围内的低延迟访问
2. 经济实惠的定价
- 透明计费:完全按实际使用量计费,无隐藏费用
- 免费体验额度:新用户赠送1.1美金起始额度,低成本测试多模态功能
- 批量优惠:大额充值享受额外赠送,降低长期使用成本
- 无固定费用:不需要预付费或月费,真正的按需付费模式
3. 专业的多模态支持
- 多模态接入指南:提供详细的图像处理和多模态调用文档
- 示例代码库:涵盖各种多模态应用场景的代码示例
- 技术咨询:专业团队提供多模态应用开发建议
- 问题排查:快速响应并解决图像处理相关的调用问题
4. 便捷的开发体验
- OpenAI兼容接口:与OpenAI官方API完全兼容,零代码迁移
- 多语言SDK支持:提供Python、JavaScript等多种语言的开发工具
- 简洁控制台:直观监控多模态API调用情况和成本
- 快速集成:3分钟内完成注册和API密钥获取,立即开始使用
o4-mini模型适用场景推荐
根据o4-mini的特性,以下是一些特别适合的应用场景:
1. 内容创作与媒体
- 图文内容创作:分析图像并生成相关描述和文案
- 社交媒体管理:处理和分析图像内容,生成适合不同平台的描述
- 视觉故事讲述:结合图像和文本创建引人入胜的叙事
2. 教育与培训
- 教学材料增强:分析教学图表和图像,提供额外解释
- 学生作业评估:评估含有图表和视觉元素的学生提交内容
- 交互式学习内容:为教育内容创建智能的视觉响应
3. 商业与营销
- 产品图像分析:自动分类和标记产品图像
- 市场研究:分析视觉趋势和消费者偏好
- 广告创意评估:评估广告视觉元素的有效性
4. 专业应用
- 医疗辅助判读:辅助分析医学影像(非诊断用途)
- 法律文档分析:处理包含图表和图像的法律文件
- 科研数据可视化解读:理解和解释复杂的科学图表
以上场景中,o4-mini的多模态能力、强化推理性能和成本效率使其成为理想选择,而通过API易平台的无限制访问,可以在任何规模的应用中部署这些功能。
总结
o4-mini模型凭借其多模态处理能力、增强的推理性能和出色的效率,成为了需要处理图像和文本组合内容的用户的理想选择。然而,ChatGPT Plus对该模型的使用限制严重阻碍了对这些强大功能的充分利用。
通过API易平台接入o4-mini模型的API,用户可以:
- 完全突破使用次数限制,按需不限次数使用
- 充分发挥多模态能力,处理无限量的图像和文本组合
- 通过编程方式自动化处理大量内容
- 根据实际使用量支付费用,控制成本
- 享受专业的技术支持和稳定可靠的服务
无论是处理大量产品图像、分析教育内容,还是构建复杂的多模态应用,API调用方式都能让您充分释放o4-mini模型的潜力,显著提升工作效率和结果质量。
通过API易平台,个人开发者、创意团队和企业用户都能以简单、经济的方式获取无限制的o4-mini模型访问能力,为创新和专业工作提供强大的多模态AI支持。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持OpenAI o4-mini模型无限次数调用,多模态能力助力视觉理解与复杂推理
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。

本文作者:API易团队
欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。