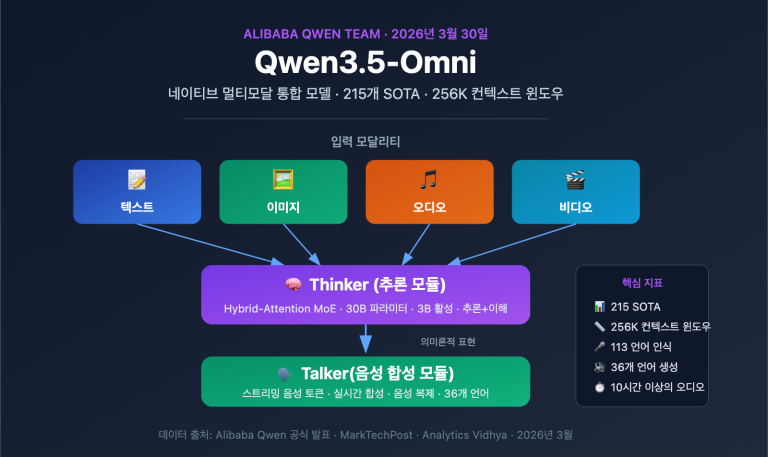
Qwen3.5-Omni 네이티브 멀티모달 모델 해석: Thinker-Talker 아키텍처를 통한 4가지 모달리티 통합 처리 및 113개 언어 음성 인식 구현
작성자 주: 알리바바의 Qwen3.5-Omni 네이티브 멀티모달 모델에 적용된 Thinker-Talker MoE 아키텍처, 256K 컨텍스트 윈도우, 오디오·비디오 인코딩 능력 및 오디오-비주얼 바이브 코딩(Audio-Visual Vibe Coding) 발현 능력을 상세히 분석합니다. 알리바바 통의천문(Qwen) 팀은 2026년 3월 30일, Qwen3.5-Omni를 공식 발표했습니다. 이 모델은 단일 계산 파이프라인 내에서 텍스트, 이미지, 오디오, 비디오 네 가지 모달리티를 동시에 처리하는 네이티브 멀티모달 통합 모델입니다….