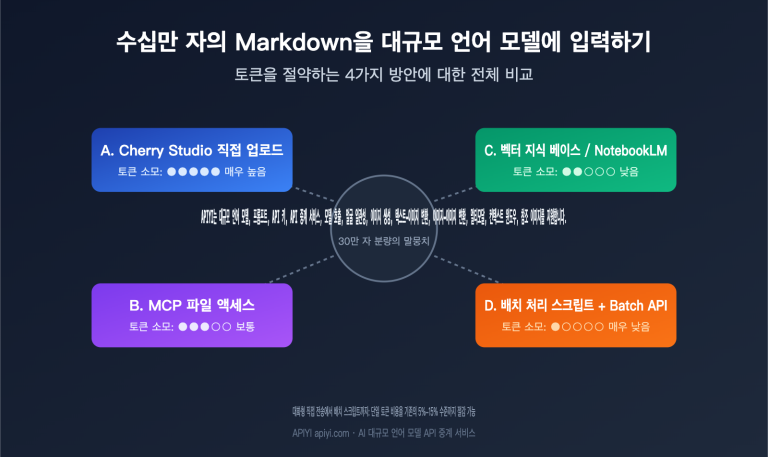
대규모 언어 모델로 수십만 자의 마크다운 말뭉치를 처리할 때 토큰을 절약하는 4가지 방안 완벽 비교
최근 아주 전형적인 상담을 하나 받았습니다. 한 작가의 수십만 자에 달하는 글을 대규모 언어 모델에 '증류(Distillation)'하여 스타일을 학습시키고 싶은데, Markdown 자료를 어떻게 넣어야 가장 경제적인지 모르겠다는 내용이었죠. 흔히 떠올리는 세 가지 방법은 Cherry Studio 같은 대화형 도구에 파일을 하나씩 업로드하기, MCP(Model Context Protocol)를 사용해 모델이 하드디스크의 파일을 직접 호출하게 하기, 혹은 지식베이스에 모두 넣어 RAG(검색…