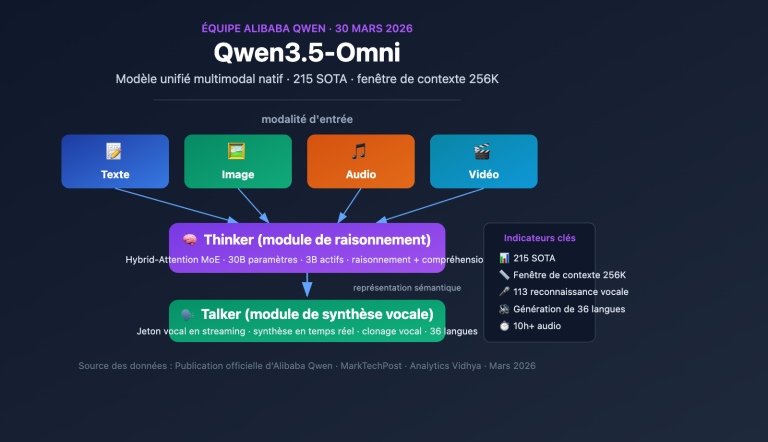
Interprétation du modèle multimodal natif Qwen3.5-Omni : l’architecture Thinker-Talker permet le traitement unifié de 4 modalités et la reconnaissance vocale de 113 langues
Note de l'auteur : Analyse détaillée de l'architecture Thinker-Talker MoE, de la fenêtre de contexte de 256K, des capacités d'encodage audio-vidéo et de la capacité émergente "Audio-Visual Vibe Coding" du modèle multimodal natif Qwen3.5-Omni d'Alibaba. L'équipe Qwen d'Alibaba a officiellement lancé Qwen3.5-Omni le 30 mars 2026. Il s'agit d'un modèle multimodal natif capable de traiter…