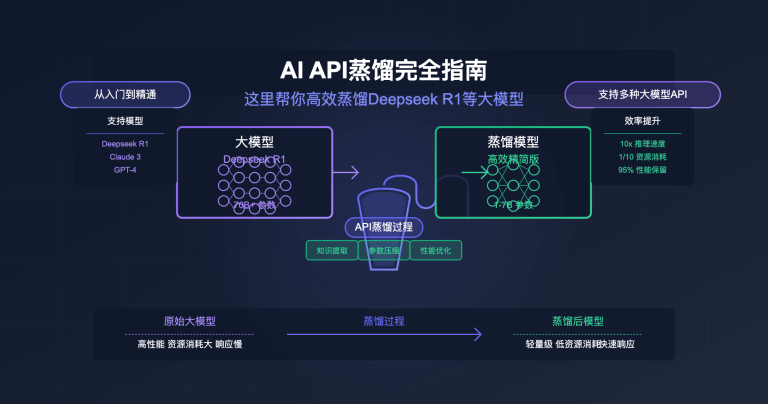
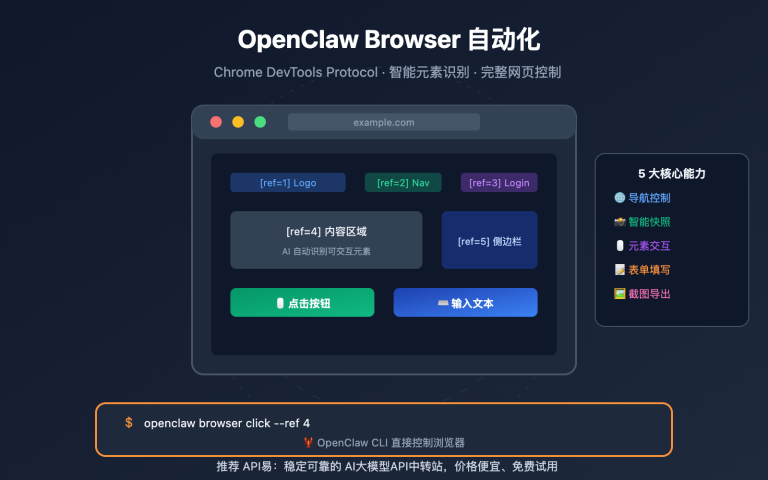
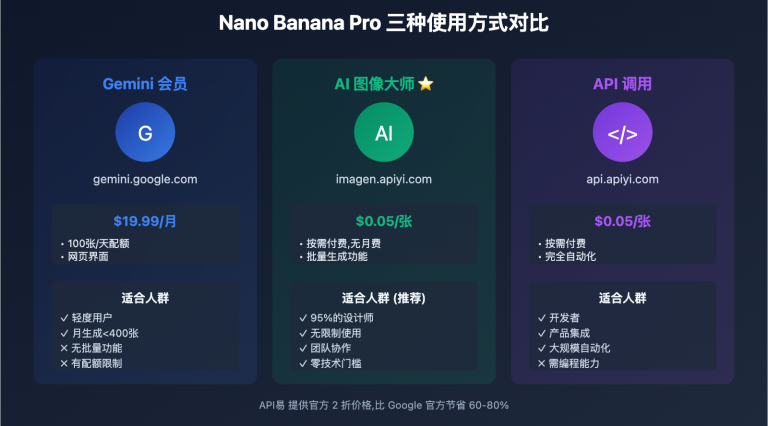
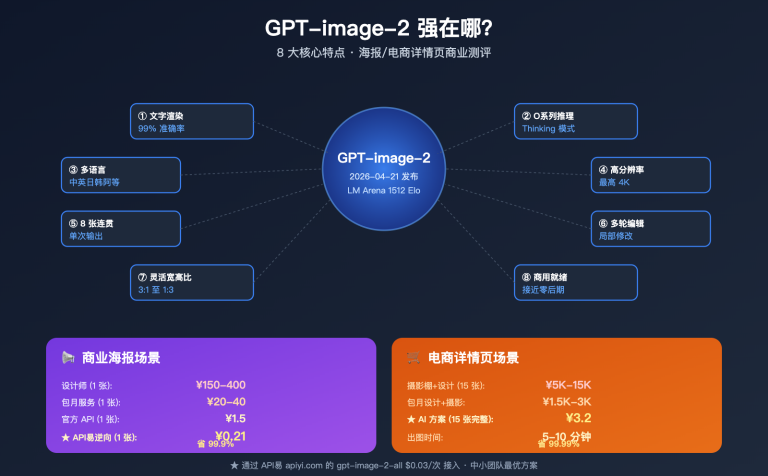
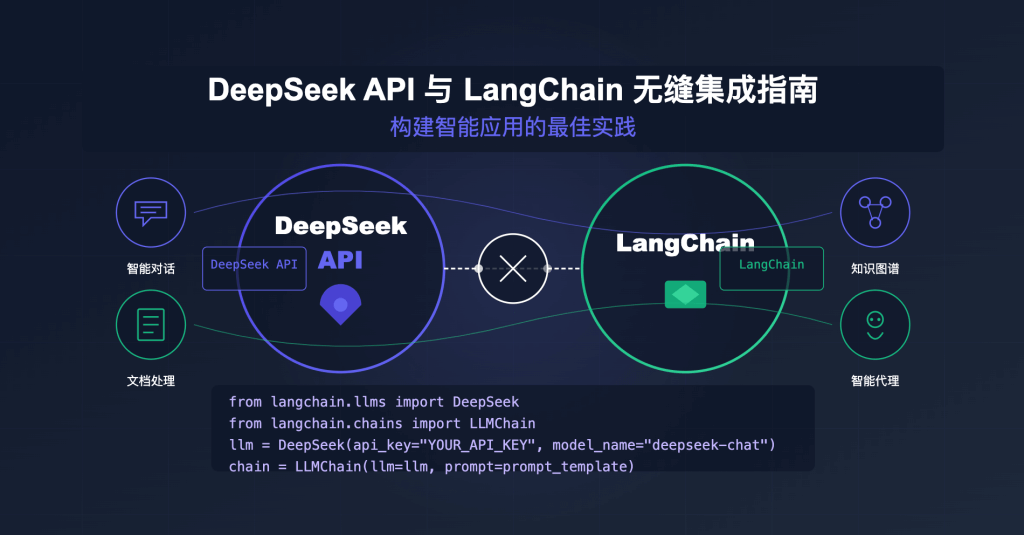
站长注:这篇我详细介绍如何在LangChain框架中使用DeepSeek API,包含完整代码示例和多种应用场景,帮助开发者快速构建智能应用。
在开发大模型应用时,很多开发者会选择LangChain这个强大的框架来简化应用构建过程。然而,当你希望使用DeepSeek这样的优质模型时,可能会遇到集成的问题——DeepSeek API能否与LangChain无缝协作?答案是肯定的!本文将详细介绍如何通过API易平台在LangChain中顺利调用DeepSeek模型,让你的应用开发事半功倍。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持DeepSeek、Claude、Gemini等全系列模型,让开发更简单
注册可送 1.1 美金额度起,约 300万 Tokens 额度体验。立即免费注册
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。
LangChain背景介绍
什么是LangChain?
LangChain是一个用于开发由大型语言模型(LLM)驱动的应用程序的框架。它提供了一套完整的工具和组件,使开发者能够轻松构建基于大模型的复杂应用,如问答系统、聊天机器人、代理系统等。
LangChain的核心理念是将大模型与其他计算和知识源连接起来,实现更强大的功能。它不仅仅是对API的简单封装,而是提供了一套完整的开发工具链:
- 链式调用:将多个组件串联起来执行复杂任务
- 代理系统:让模型能够使用工具并执行多步推理
- 记忆管理:管理对话历史和上下文信息
- 数据连接:连接文档、数据库和其他数据源
- 评估框架:测试和评估模型输出质量
LangChain的主要应用场景
LangChain框架适用于各种大模型应用场景,特别是:
- 文档问答系统:结合文档加载器、文本分块和向量数据库,构建能够回答特定文档相关问题的系统
- 个性化助手:创建能记住用户偏好和历史交互的聊天助手
- 自主代理:开发能够基于目标自主规划和执行任务的AI代理
- 数据分析助手:连接数据库和分析工具,提供数据分析支持
- 内容生成器:生成文章、摘要、翻译和其他创意内容
- 多模态应用:处理和生成图像、音频等多种类型的内容
DeepSeek API与LangChain集成原理
DeepSeek与OpenAI API兼容性
DeepSeek是一款强大的大语言模型,擅长理解和生成复杂内容,特别是在中文理解方面表现出色。在API易平台上,DeepSeek API被设计为与OpenAI API完全兼容,这意味着只需要简单地更改API端点和密钥,就可以在原本使用OpenAI的代码中无缝切换到DeepSeek模型。
这种兼容性为LangChain集成提供了便捷途径,因为LangChain对OpenAI API有着完善的支持。
通过API易调用DeepSeek的优势
使用API易平台作为DeepSeek API的接入点,相比直接使用官方API有以下优势:
- 统一接口:无论使用DeepSeek、Claude、Gemini还是其他模型,都可以使用统一的接口格式
- 稳定性保障:API易提供多节点部署,确保API调用稳定可靠
- 灵活切换:可以在不修改大部分代码的情况下快速切换不同模型
- 成本控制:提供透明的计费和使用统计,帮助控制API调用成本
- 额外功能:提供额外的安全保障、使用分析等增值服务
LangChain集成 开发指南
基础集成方法
将DeepSeek与LangChain集成有两种主要方式:使用专用的LangChain集成类或修改OpenAI配置。下面分别介绍这两种方法。
方法一:使用LangChain的OpenAI包装类
这是最简单的方法,只需安装必要的包并配置正确的API端点:
# 安装必要的包
# pip install langchain-openai
from langchain_openai.chat_models.base import BaseChatOpenAI
# 初始化LLM
llm = BaseChatOpenAI(
model='deepseek-chat', # 使用DeepSeek聊天模型
openai_api_key='YOUR_APIYI_API_KEY', # 替换为你的API易API密钥
openai_api_base='https://vip.apiyi.com/v1', # API易的端点
max_tokens=1024 # 设置最大生成token数
)
# 简单调用
response = llm.invoke("请介绍一下中国的人工智能发展现状")
print(response.content)
方法二:修改OpenAI包的配置
另一种方法是直接修改OpenAI包的配置:
# 安装必要的包
# pip install langchain-openai openai
import openai from 'OpenAI'
from langchain_openai import ChatOpenAI
# 配置OpenAI客户端
openai.api_base = "https://vip.apiyi.com/v1"
openai.api_key = "YOUR_APIYI_API_KEY"
# 初始化LLM
llm = ChatOpenAI(model_name="deepseek-chat", max_tokens=1024)
# 简单调用
response = llm.invoke("请介绍一下中国的人工智能发展现状")
print(response.content)
链式调用示例
LangChain的强大之处在于它的链式调用功能,下面是一个使用DeepSeek模型构建简单链的示例:
from langchain_openai.chat_models.base import BaseChatOpenAI
from langchain.chains import LLMChain
from langchain.prompts import PromptTemplate
# 初始化LLM
llm = BaseChatOpenAI(
model='deepseek-chat',
openai_api_key='YOUR_APIYI_API_KEY',
openai_api_base='https://vip.apiyi.com/v1',
max_tokens=1024
)
# 定义提示模板
template = """
你是一个专业的{profession}。
请针对以下问题提供专业的解答:
{question}
请以{tone}的语气回答。
"""
prompt = PromptTemplate(
input_variables=["profession", "question", "tone"],
template=template,
)
# 创建链
chain = LLMChain(llm=llm, prompt=prompt)
# 执行链
result = chain.invoke({
"profession": "人工智能专家",
"question": "机器学习和深度学习有什么区别?",
"tone": "通俗易懂"
})
print(result["text"])
构建文档问答系统
下面是一个使用DeepSeek模型构建文档问答系统的完整示例:
# 安装必要的包
# pip install langchain-openai langchain-community faiss-cpu
from langchain_openai.chat_models.base import BaseChatOpenAI
from langchain_openai.embeddings import OpenAIEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQA
from langchain.document_loaders import TextLoader
# 初始化模型
llm = BaseChatOpenAI(
model='deepseek-chat',
openai_api_key='YOUR_APIYI_API_KEY',
openai_api_base='https://vip.apiyi.com/v1',
max_tokens=1024
)
embeddings = OpenAIEmbeddings(
model="text-embedding-ada-002",
openai_api_key='YOUR_APIYI_API_KEY',
openai_api_base='https://vip.apiyi.com/v1'
)
# 加载文档
loader = TextLoader('path/to/your/document.txt')
documents = loader.load()
# 分割文档
text_splitter = CharacterTextSplitter(chunk_size=1000, chunk_overlap=0)
docs = text_splitter.split_documents(documents)
# 创建向量数据库
vectorstore = FAISS.from_documents(docs, embeddings)
# 创建问答链
qa = RetrievalQA.from_chain_type(
llm=llm,
chain_type="stuff",
retriever=vectorstore.as_retriever()
)
# 执行问答
query = "文档中提到了哪些关键技术?"
result = qa.invoke({"query": query})
print(result["result"])
实现多轮对话助手
使用DeepSeek模型创建具有记忆功能的多轮对话助手:
from langchain_openai.chat_models.base import BaseChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferMemory
# 初始化模型
llm = BaseChatOpenAI(
model='deepseek-chat',
openai_api_key='YOUR_APIYI_API_KEY',
openai_api_base='https://vip.apiyi.com/v1',
max_tokens=1024
)
# 创建记忆
memory = ConversationBufferMemory()
# 创建对话链
conversation = ConversationChain(
llm=llm,
memory=memory,
verbose=True
)
# 多轮对话
print(conversation.invoke("你好,我叫小明,我想学习Python编程")["response"])
print(conversation.invoke("你能给我推荐一些入门资源吗?")["response"])
print(conversation.invoke("对了,我之前说我叫什么名字?")["response"])
DeepSeek API集成 应用场景
场景一:智能客服系统
使用DeepSeek的强大理解能力和LangChain的工具链功能,可以构建高效的智能客服系统:
from langchain_openai.chat_models.base import BaseChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationBufferWindowMemory
from langchain.tools import Tool
from langchain.agents import AgentType, initialize_agent
# 初始化模型
llm = BaseChatOpenAI(
model='deepseek-chat',
openai_api_key='YOUR_APIYI_API_KEY',
openai_api_base='https://vip.apiyi.com/v1',
temperature=0.7,
max_tokens=1024
)
# 模拟查询订单工具
def query_order(order_id):
# 实际应用中,这里会连接到订单数据库
orders = {
"ORD001": {"status": "已发货", "estimated_delivery": "2023-05-15"},
"ORD002": {"status": "处理中", "estimated_delivery": "2023-05-18"},
"ORD003": {"status": "已完成", "estimated_delivery": "2023-05-10"}
}
return orders.get(order_id, {"status": "未找到", "estimated_delivery": "未知"})
# 定义工具
tools = [
Tool(
name="查询订单",
func=query_order,
description="当用户询问订单状态时使用。输入订单号,返回订单状态信息。"
)
]
# 创建代理
memory = ConversationBufferWindowMemory(k=5)
agent = initialize_agent(
tools,
llm,
agent=AgentType.CONVERSATIONAL_REACT_DESCRIPTION,
memory=memory,
verbose=True
)
# 使用代理
response = agent.run("我的订单ORD001现在是什么状态?")
print(response)
场景二:内容创作助手
结合DeepSeek的创意写作能力和LangChain的工具集,构建功能强大的内容创作助手:
from langchain_openai.chat_models.base import BaseChatOpenAI
from langchain.chains import SequentialChain
from langchain.chains.llm import LLMChain
from langchain.prompts import PromptTemplate
# 初始化模型
llm = BaseChatOpenAI(
model='deepseek-chat',
openai_api_key='YOUR_APIYI_API_KEY',
openai_api_base='https://vip.apiyi.com/v1',
temperature=0.8,
max_tokens=2048
)
# 创建大纲生成器
outline_template = """
你是一位内容策划专家。请针对主题"{topic}"创建一个详细的文章大纲,包括引言、正文(至少3个主要部分)和结论。
"""
outline_prompt = PromptTemplate(input_variables=["topic"], template=outline_template)
outline_chain = LLMChain(llm=llm, prompt=outline_prompt, output_key="outline")
# 创建内容生成器
content_template = """
你是一位专业内容创作者。请使用以下大纲,撰写一篇关于"{topic}"的完整文章。
大纲:
{outline}
请确保内容丰富、逻辑清晰,并使用吸引人的语言。
"""
content_prompt = PromptTemplate(input_variables=["topic", "outline"], template=content_template)
content_chain = LLMChain(llm=llm, prompt=content_prompt, output_key="article")
# 创建序列链
sequential_chain = SequentialChain(
chains=[outline_chain, content_chain],
input_variables=["topic"],
output_variables=["outline", "article"],
verbose=True
)
# 执行链
result = sequential_chain.invoke({"topic": "人工智能在医疗领域的应用"})
print("大纲:")
print(result["outline"])
print("\n完整文章:")
print(result["article"])
场景三:个性化学习助手
利用DeepSeek的强大知识库和LangChain的记忆功能,构建能够适应学习者风格和进度的教育助手:
from langchain_openai.chat_models.base import BaseChatOpenAI
from langchain.chains import ConversationChain
from langchain.memory import ConversationEntityMemory
from langchain.memory.entity import InMemoryEntityStore
from langchain.prompts import PromptTemplate
# 初始化模型
llm = BaseChatOpenAI(
model='deepseek-chat',
openai_api_key='YOUR_APIYI_API_KEY',
openai_api_base='https://vip.apiyi.com/v1',
temperature=0.7,
max_tokens=1024
)
# 创建实体记忆
entity_store = InMemoryEntityStore()
memory = ConversationEntityMemory(llm=llm, entity_store=entity_store)
# 定义提示模板
template = """
你是一位个性化学习助手,名为"知识伙伴"。你的目标是帮助用户学习新知识和技能。
当前对话:
{history}
实体信息:
{entities}
人类: {input}
AI: """
prompt = PromptTemplate(
input_variables=["history", "entities", "input"],
template=template
)
# 创建对话链
conversation = ConversationChain(
llm=llm,
memory=memory,
prompt=prompt,
verbose=True
)
# 多轮对话示例
print(conversation.invoke("你好,我想学习Python编程,但我只有很基础的编程知识")["response"])
print(conversation.invoke("我特别感兴趣的是数据分析,你能给我一个学习路径吗?")["response"])
print(conversation.invoke("我每天只有2小时的学习时间,应该如何规划?")["response"])
Token计算 最佳实践
在使用LangChain和DeepSeek API时,合理管理Token使用对于控制成本至关重要。以下是一些建议:
优化提示模板
良好的提示模板设计可以减少不必要的Token消耗:
# 低效的提示模板(过多的修饰和冗余)
bad_template = """
你是一个非常非常专业的助手,拥有极其丰富的知识和经验,可以解答用户提出的各种问题。
不管问题多么困难,你都会尽力给出最完整、最详细、最准确的回答。
无论如何,你都不应该拒绝回答问题,而应该尽可能提供帮助。
现在,请回答用户的问题:{question}
"""
# 优化后的提示模板(简洁明了)
good_template = """
你是专业助手。请回答:{question}
"""
合理设置记忆长度
在使用对话记忆时,可以限制保存的消息数量,避免不必要的Token消耗:
# 使用窗口记忆,只保存最近5轮对话
from langchain.memory import ConversationBufferWindowMemory
memory = ConversationBufferWindowMemory(k=5)
# 使用摘要记忆,定期总结历史对话
from langchain.memory import ConversationSummaryMemory
memory = ConversationSummaryMemory(llm=llm)
分块处理大型文档
当处理大型文档时,适当的分块策略可以有效控制Token使用:
from langchain.text_splitter import CharacterTextSplitter
# 设置合理的分块大小和重叠
text_splitter = CharacterTextSplitter(
chunk_size=1000, # 每块约1000个字符
chunk_overlap=100, # 100个字符的重叠,确保上下文连贯
separator="\n" # 尽量在段落边界分割
)
DeepSeek API集成 常见问题
Q1: DeepSeek的模型在LangChain中是否支持所有功能?
A: 通过API易平台,DeepSeek模型支持LangChain的大部分核心功能,包括链式调用、记忆管理、代理系统等。但是一些依赖于特定OpenAI功能的高级特性(如函数调用、DALL-E图像生成)可能需要额外适配。
Q2: 使用DeepSeek模型时,需要对提示词做哪些调整?
A: DeepSeek模型对中文的理解能力非常出色,因此在处理中文内容时,可以直接使用自然的中文提示词。对于专业领域,DeepSeek同样表现出色,但可能需要根据具体任务微调提示词以获得最佳效果。
Q3: 如何在同一个LangChain应用中同时使用多个不同的模型?
A: 使用API易平台的一大优势是可以轻松切换模型。以下是一个同时使用多个模型的示例:
from langchain_openai.chat_models.base import BaseChatOpenAI
# 初始化多个模型
deepseek_llm = BaseChatOpenAI(
model='deepseek-chat',
openai_api_key='YOUR_APIYI_API_KEY',
openai_api_base='https://vip.apiyi.com/v1',
max_tokens=1024
)
gpt_llm = BaseChatOpenAI(
model='gpt-3.5-turbo',
openai_api_key='YOUR_APIYI_API_KEY',
openai_api_base='https://vip.apiyi.com/v1',
max_tokens=1024
)
claude_llm = BaseChatOpenAI(
model='claude-3-5-sonnet',
openai_api_key='YOUR_APIYI_API_KEY',
openai_api_base='https://vip.apiyi.com/v1',
max_tokens=1024
)
# 根据任务选择不同模型
def get_response(query, task_type):
if "创意" in task_type:
return claude_llm.invoke(query).content
elif "中文" in task_type:
return deepseek_llm.invoke(query).content
else:
return gpt_llm.invoke(query).content
Q4: 在使用API易调用DeepSeek时,如何排查集成问题?
A: 常见问题排查步骤:
- 检查API密钥是否正确
- 确认API端点URL是否正确设置为
https://vip.apiyi.com/v1 - 检查模型名称是否正确,如使用
deepseek-chat而非其他变体 - 查看完整的错误信息,API易会返回详细的错误说明
- 尝试使用基本的HTTP请求工具(如curl或Postman)直接调用API,验证凭证是否有效
Q5: 如何优化DeepSeek在LangChain中的性能?
A: 性能优化建议:
- 对于频繁使用的相似请求,考虑使用缓存
- 合理设置
max_tokens和temperature参数,避免生成过长或不必要的回复 - 在处理大量请求时,实现请求队列和限速机制
- 对于复杂任务,将其分解为多个小步骤,逐步处理
- 对于需要知识库的应用,确保向量存储使用适当的相似度搜索参数
为什么选择 API易平台
- 多模型统一接口
- 一个API密钥访问所有主流大模型
- OpenAI兼容接口,减少学习和迁移成本
- 在不修改代码的情况下轻松切换模型
- 高性能保障
- 多节点部署,确保API调用稳定可靠
- 智能路由技术,自动选择最佳请求路径
- 支持高并发请求,满足商业应用需求
- 成本优势
- 透明的按量计费方式
- 部分模型提供更具竞争力的价格
- 新用户赠送试用额度,无需信用卡即可开始使用
- 开发便利性
- 完整的开发文档和示例代码
- 多种编程语言的SDK支持
- 专业的技术支持和咨询服务
- 额外功能
- 详细的API调用分析和统计
- 支持流式输出(Streaming)
- 内容安全过滤和审核功能
提示:使用API易平台,你可以:
- 轻松实现DeepSeek与LangChain的集成
- 灵活切换不同模型,如从DeepSeek切换到Claude或GPT
- 避免单一模型依赖,提高应用的稳定性
- 获得专业的技术支持和解决方案建议
总结
DeepSeek API通过API易平台与LangChain的集成为开发者提供了构建智能应用的强大工具组合。这种集成利用了DeepSeek模型的卓越能力,特别是在中文理解和生成方面的优势,同时借助LangChain的丰富功能和组件,简化了复杂应用的开发流程。
通过本文提供的指南和示例代码,你可以快速上手DeepSeek与LangChain的集成,构建从简单的聊天机器人到复杂的智能代理系统的各类应用。API易平台的多模型支持和统一接口进一步增强了开发灵活性,让你能够轻松尝试和比较不同模型的表现。
立即开始尝试DeepSeek与LangChain的强大组合,探索更多AI应用的可能性!
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持DeepSeek、Claude、Gemini等全系列模型,以统一接口实现多模型开发
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。

本文作者:API易团队
欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。