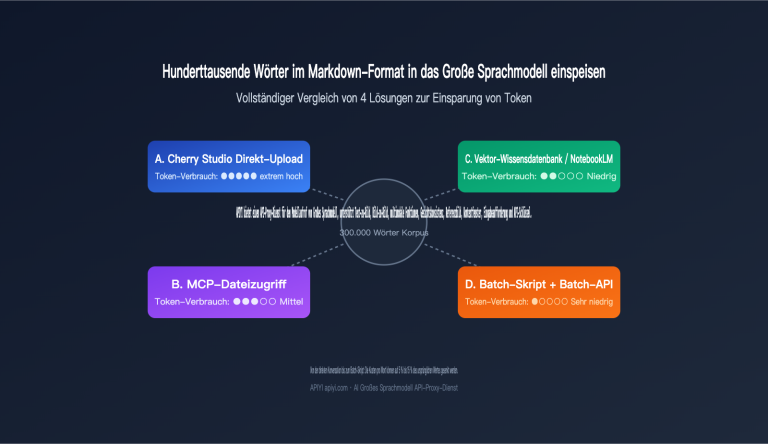
Vollständiger Vergleich von 4 Methoden zur Token-Einsparung bei der Verarbeitung von hunderttausenden Wörtern an Markdown-Korpora durch ein Großes Sprachmodell
Kürzlich erreichte uns eine typische Anfrage: Ein Nutzer möchte die Texte eines versierten Autors (mehrere hunderttausend Wörter) als „Stil-Grundlage“ an ein Großes Sprachmodell „destillieren“, weiß aber nicht, wie er das Markdown-Korpus am kosteneffizientesten einspeisen soll. Die drei gängigen Ansätze sind: Dateien einzeln in Dialog-Tools wie Cherry Studio hochladen, per MCP das Modell direkt auf Dateien…