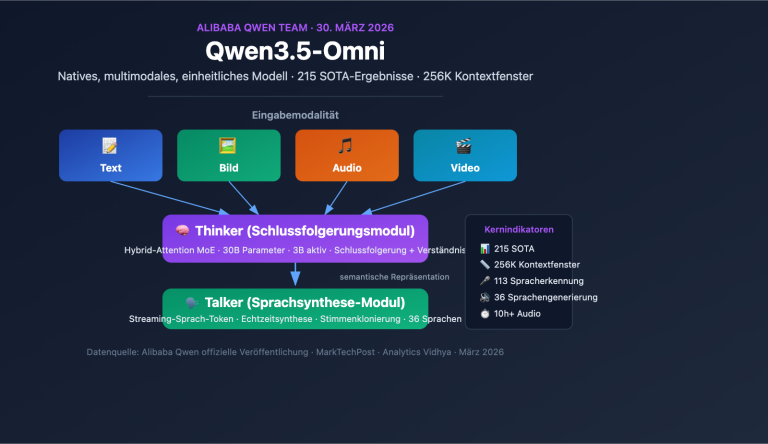
Interpretation des nativen multimodalen Modells Qwen3.5-Omni: Thinker-Talker-Architektur zur einheitlichen Verarbeitung von 4 Modalitäten und Spracherkennung in 113 Sprachen
Anmerkung des Autors: Detaillierte Analyse der nativen, multimodalen Thinker-Talker MoE-Architektur des Qwen3.5-Omni-Modells von Alibaba, inklusive 256K-Kontextfenster, Audio-Video-Kodierung und der Audio-Visual Vibe Coding-Emergenz. Das Team von Alibaba Qwen hat am 30. März 2026 offiziell Qwen3.5-Omni veröffentlicht. Dies ist ein natives, multimodales, einheitliches Modell, das Text, Bild, Audio und Video in einem einzigen Rechenpfad verarbeitet. Als Teil…