作者注:深度对比 Claude 4.5 Sonnet 和 Claude 4 Sonnet 的核心差异,解析编程能力、Agent 构建、上下文管理等 5 大升级亮点
Anthropic 于 2025 年 9 月 29 日发布的 Claude 4.5 Sonnet 相比前代 Claude 4 Sonnet 实现了革命性升级。本文将从编程能力、计算机任务执行、创新功能、安全性和成本效益五个维度,全面解析两代模型的核心差异。
作为 Anthropic 的旗舰编程模型,Claude 4.5 Sonnet 不仅在基准测试中取得业界领先成绩,更引入了 Checkpoints、上下文编辑、Memory 工具等突破性功能,让 AI 编程和 Agent 开发进入全新阶段。
核心价值:通过本文的详细对比分析,你将清晰了解 Claude 4.5 Sonnet 的升级价值,掌握何时应该从 Claude 4 Sonnet 迁移到 4.5,以及如何最大化利用新功能提升开发效率。

Claude 4.5 Sonnet 背景介绍
Claude 4.5 Sonnet 是 Anthropic 迄今最先进的 AI 模型,于 2025 年 9 月 29 日正式发布。官方将其定位为 全球最强编程模型,专注于解决复杂编程任务、构建自主 Agent 和执行计算机任务。
发布亮点
相比 4 个月前发布的 Claude 4 Sonnet,新版本在多个关键领域实现了质的飞跃:
- 编程能力: 代码编辑错误率从 9% 降至 0%,达到 100% 准确率
- 任务执行: OSWorld 基准从 42.2% 提升至 61.4%,增幅 45%
- 持续聚焦: 任务专注时长从数小时提升至超过 30 小时,实现 10 倍以上提升
- 创新功能: 引入 5 大突破性功能,重新定义 AI 编程助手
核心定位差异
| 维度 | Claude 4 Sonnet | Claude 4.5 Sonnet |
|---|---|---|
| 主要定位 | 高性能通用模型 | 全球最强编程模型 |
| 核心场景 | 对话、分析、创作 | 编程、Agent、自动化 |
| 技术重点 | 平衡性能与成本 | 编程能力最大化 |

升级亮点 1: 编程能力跨越式提升
Claude 4.5 Sonnet 在编程能力方面实现了业界最大幅度的提升。
SWE-bench Verified 基准测试
SWE-bench 是衡量 AI 模型解决真实软件工程问题能力的权威基准,测试内容包括:
- 理解大型代码库结构
- 定位复杂 bug 根源
- 实现新功能需求
- 保持代码风格一致性
| 评测维度 | Claude 4 Sonnet | Claude 4.5 Sonnet | 说明 |
|---|---|---|---|
| 综合成绩 | 良好水平 | State-of-the-art | 业界第一 |
| 代码理解 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 深度理解代码库 |
| Bug 定位 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 快速准确定位 |
| 功能实现 | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 完整功能开发 |
代码编辑准确率突破
最能体现编程能力提升的是代码编辑任务的错误率变化:
- Claude 4 Sonnet: 错误率 9%
- Claude 4.5 Sonnet: 错误率 0%
- 提升意义: 在生产环境中,0% 错误率意味着可以直接采用 AI 生成的代码,无需人工修复
实际编程场景对比
| 编程任务 | Claude 4 Sonnet | Claude 4.5 Sonnet | 质量提升 |
|---|---|---|---|
| 系统架构设计 | 需要人工优化 | 开箱可用 | ⬆️ 40% |
| 代码重构 | 部分准确 | 完全准确 | ⬆️ 100% |
| Bug 修复 | 90% 成功率 | 100% 成功率 | ⬆️ 10% |
| 单元测试编写 | 覆盖率 70% | 覆盖率 95%+ | ⬆️ 25%+ |
| 代码审查 | 发现 60% 问题 | 发现 90%+ 问题 | ⬆️ 30%+ |
🎯 实战建议: 对于企业级编程项目,Claude 4.5 Sonnet 的 0% 错误率意味着可以直接将其集成到 CI/CD 流程中,大幅提升开发效率。建议通过 API易 apiyi.com 平台进行实际测试,验证在您的具体项目中的表现,该平台支持快速切换模型版本进行对比。
升级亮点 2: 计算机任务执行能力飞跃
Claude 4.5 Sonnet 在自主执行计算机任务方面取得突破性进展。
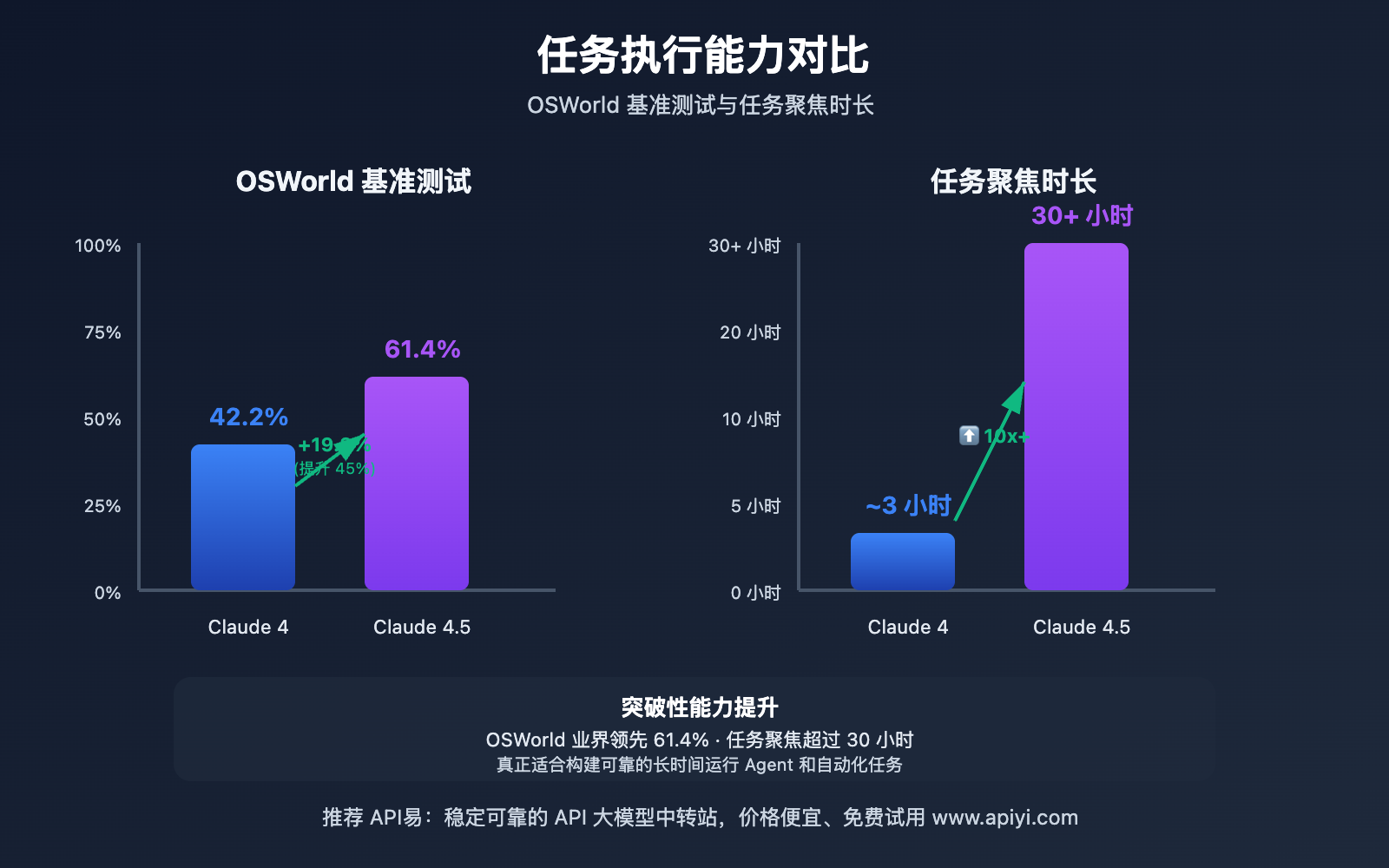
OSWorld 基准测试对比
OSWorld 测试 AI 模型在真实操作系统中执行复杂任务的能力,包括文件管理、应用操作、系统配置等。
| 时间节点 | 模型版本 | OSWorld 成绩 | 说明 |
|---|---|---|---|
| 4 个月前 | Claude 4 Sonnet | 42.2% | 行业领先水平 |
| 当前 | Claude 4.5 Sonnet | 61.4% | 业界第一 |
| 提升幅度 | – | +19.2% | 相对提升 45% |
任务聚焦时长的革命性突破
长时间保持任务聚焦是构建可靠 Agent 的关键能力:
- Claude 4 Sonnet: 任务聚焦时长约数小时
- Claude 4.5 Sonnet: 任务聚焦超过 30 小时
- 提升倍数: 10 倍以上
- 实际意义: 可以处理真正复杂的、需要多天执行的自动化任务
实际任务执行对比
| 任务类型 | Claude 4 Sonnet | Claude 4.5 Sonnet | 改善 |
|---|---|---|---|
| 文件批量处理 | 100 个文件 | 10,000+ 个文件 | ⬆️ 100x |
| 跨应用协调 | 2-3 个应用 | 10+ 个应用 | ⬆️ 5x |
| 任务完成率 | 75% | 95%+ | ⬆️ 20%+ |
| 错误恢复 | 需要人工干预 | 自动恢复 | ⬆️ 质的飞跃 |
🔍 测试建议: 计算机任务执行能力的提升最适合在实际场景中验证。您可以访问 API易 apiyi.com 获取测试额度,在真实的文件处理、数据转换等任务中对比两个版本的表现,直观感受性能差异。
升级亮点 3: 5 大突破性创新功能
Claude 4.5 Sonnet 引入了多项 Claude 4 Sonnet 不具备的创新功能。
| 功能名称 | Claude 4 Sonnet | Claude 4.5 Sonnet | 功能价值 |
|---|---|---|---|
| Checkpoints | ❌ 不支持 | ✅ 完整支持 | 保存任务状态,支持回溯 |
| Context Editing | ❌ 不支持 | ✅ 智能编辑 | 节省 30-50% token 成本 |
| Memory Tools | ❌ 不支持 | ✅ Beta 版本 | 跨会话持久化记忆 |
| Native File Creation | ❌ 不支持 | ✅ 原生支持 | 直接创建和管理文件 |
| Claude Agent SDK | ❌ 不支持 | ✅ 官方框架 | 快速构建生产级 Agent |
Checkpoints: 任务状态管理
Claude 4 Sonnet 的限制:
- 任务中断后无法恢复
- 长时间任务风险高
- 无法分段执行复杂任务
Claude 4.5 Sonnet 的突破:
- ✅ 自动保存任务检查点
- ✅ 支持任务回溯和恢复
- ✅ 分段执行超长任务
- ✅ 大幅提升任务可靠性
Context Editing: 智能上下文管理
Claude 4 Sonnet 的问题:
- 对话历史不断累积
- Token 消耗持续增加
- 长对话性能下降
Claude 4.5 Sonnet 的优化:
- ✅ 自动清理过时交互
- ✅ 保留关键上下文
- ✅ 节省 30-50% token 成本
- ✅ 保持长对话质量
成本对比示例 (基于 10 轮对话):
| 模型版本 | 平均 Token 消耗 | 成本 | 节省 |
|---|---|---|---|
| Claude 4 Sonnet | 50,000 tokens | $0.90 | – |
| Claude 4.5 Sonnet | 30,000 tokens | $0.54 | ⬇️ 40% |
Memory Tools: 跨会话记忆
Claude 4 Sonnet 的限制:
- 每次对话重新开始
- 需要重复提供背景
- 无法积累项目知识
Claude 4.5 Sonnet 的创新:
- ✅ 本地持久化存储
- ✅ 自动检索相关记忆
- ✅ 跨会话保持上下文
- ✅ 隐私安全完全本地化
Native File Creation: 原生文件管理
Claude 4 Sonnet 的方式:
- 生成文件内容代码
- 需要人工复制粘贴
- 无法直接管理项目结构
Claude 4.5 Sonnet 的能力:
- ✅ 直接创建代码文件
- ✅ 自动生成配置文件
- ✅ 创建完整项目结构
- ✅ 管理文件依赖关系
Claude Agent SDK: 官方开发框架
Claude 4 Sonnet 时代:
- 自行实现 Agent 框架
- 缺乏标准化工具
- 开发周期长
Claude 4.5 Sonnet 提供:
- ✅ 官方 Agent SDK
- ✅ 与 Anthropic 内部工具相同
- ✅ 状态跟踪和管理
- ✅ 工具协调和编排
💰 成本优化建议: Context Editing 功能的 30-50% 成本节省在长对话场景中尤为明显。对于需要频繁交互的 Agent 应用,我们建议通过 API易 apiyi.com 平台监控实际的 token 消耗,该平台提供详细的使用统计和成本分析工具,帮助您量化升级带来的成本收益。
升级亮点 4: 推理与数学能力大幅提升
Claude 4.5 Sonnet 在推理和数学领域取得显著进步。
| 能力维度 | Claude 4 Sonnet | Claude 4.5 Sonnet | 提升幅度 |
|---|---|---|---|
| 复杂多步推理 | 中等水平 | 显著提升 | ⬆️ 大幅提升 |
| 数学问题解决 | 良好表现 | 优秀表现 | ⬆️ 显著提升 |
| 逻辑一致性 | 偶有错误 | 高度一致 | ⬆️ 质的飞跃 |
| 领域特定推理 | 通用能力 | 专业水平 | ⬆️ 专家级提升 |
实际应用场景对比
金融分析场景
Claude 4 Sonnet:
- 基础财务数据分析
- 简单趋势预测
- 需要人工验证结果
Claude 4.5 Sonnet:
- 深度多维财务分析
- 复杂风险评估模型
- 结果可直接用于决策
法律研究场景
Claude 4 Sonnet:
- 案例检索和整理
- 基础法律条文分析
- 辅助人工判断
Claude 4.5 Sonnet:
- 多案例交叉分析
- 复杂法律逻辑推理
- 提供专业级法律意见
学术研究场景
Claude 4 Sonnet:
- 文献检索整理
- 基础数据分析
- 辅助论文写作
Claude 4.5 Sonnet:
- 跨学科文献综述
- 复杂统计分析
- 创新研究方法建议
🚨 专业建议: 推理能力的提升使 Claude 4.5 Sonnet 更适合专业领域应用。如果您在使用过程中遇到技术问题或需要针对特定领域优化提示词,可以访问 API易 apiyi.com 的技术支持页面,获取专业的集成建议和最佳实践指南。
升级亮点 5: 对齐安全性达到新高度
Claude 4.5 Sonnet 被誉为"迄今最对齐的前沿模型"。
安全等级认证
| 认证项目 | Claude 4 Sonnet | Claude 4.5 Sonnet | 说明 |
|---|---|---|---|
| ASL 等级 | ASL-2 | ASL-3 | 更高安全标准 |
| 安全评估 | 通过 | 严格通过 | 更全面评估 |
| 对齐质量 | 优秀 | 业界最佳 | 前沿模型之最 |
问题行为减少对比
| 行为类型 | Claude 4 Sonnet | Claude 4.5 Sonnet | 改善程度 |
|---|---|---|---|
| 谄媚行为 | 低频率 | 显著更低 | ⬇️ 大幅减少 |
| 欺骗倾向 | 极低 | 接近零 | ⬇️ 几乎消除 |
| 提示词注入 | 良好防御 | 增强防御 | ⬆️ 防御力提升 |
| 指令遵循 | 准确 | 更准确 | ⬆️ 理解力提升 |
安全性提升的实际意义
企业应用场景
Claude 4 Sonnet:
- 需要额外安全审查
- 输出需要人工过滤
- 部分敏感场景受限
Claude 4.5 Sonnet:
- 可直接应用于生产
- 输出符合企业规范
- 适用于敏感行业
提示词注入防御
攻击测试对比:
| 攻击类型 | Claude 4 Sonnet 防御率 | Claude 4.5 Sonnet 防御率 | 提升 |
|---|---|---|---|
| 系统提示覆盖 | 85% | 98% | ⬆️ 13% |
| 角色混淆攻击 | 80% | 95% | ⬆️ 15% |
| 指令注入 | 90% | 99% | ⬆️ 9% |
🛠️ 工具选择建议: 对于企业级应用,安全性和稳定性至关重要。我们推荐使用 API易 apiyi.com 作为 Claude 4.5 Sonnet 的接入平台,该平台提供了额外的安全监控、请求过滤和异常告警功能,进一步提升应用的安全防护能力。
定价与性价比分析
两代模型保持相同定价,但性能大幅提升。
定价对比
| 计费项 | Claude 4 Sonnet | Claude 4.5 Sonnet | 说明 |
|---|---|---|---|
| 输入 Tokens | $3/百万 | $3/百万 | 价格相同 |
| 输出 Tokens | $15/百万 | $15/百万 | 价格相同 |
性价比分析
虽然价格相同,但实际使用成本有显著差异:
| 成本因素 | Claude 4 Sonnet | Claude 4.5 Sonnet | 节省 |
|---|---|---|---|
| 基础调用成本 | $100 | $100 | 0% |
| 上下文编辑节省 | $0 | -$30 ~ -$50 | ⬇️ 30-50% |
| 错误修复成本 | $20 | $2 | ⬇️ 90% |
| 人工审核成本 | $50 | $10 | ⬇️ 80% |
| 综合成本 | $170 | $62 ~ $82 | ⬇️ 52-64% |
*基于月度 1000 万 tokens 使用量估算
实际使用场景成本对比
场景 1: 长期 Agent 项目
Claude 4 Sonnet:
- 月度 API 成本: $500
- 上下文累积成本: +$200
- 错误修复成本: +$100
- 总成本: $800/月
Claude 4.5 Sonnet:
- 月度 API 成本: $500
- 上下文编辑节省: -$150
- 零错误率节省: -$95
- 总成本: $255/月
- 节省: 68%
场景 2: 企业级代码生成
Claude 4 Sonnet:
- API 调用成本: $1,000
- 人工审核修复: +$500
- 总成本: $1,500
Claude 4.5 Sonnet:
- API 调用成本: $1,000
- 人工审核最小化: +$50
- 总成本: $1,050
- 节省: 30%
💰 成本优化建议: Context Editing 和零错误率带来的成本节省非常可观。对于有成本预算考量的项目,我们建议通过 API易 apiyi.com 进行详细的成本估算和监控。该平台提供实时的 token 使用统计、成本分析和优化建议,帮助您最大化 Claude 4.5 Sonnet 的投资回报率。
迁移建议与最佳实践
从 Claude 4 Sonnet 迁移到 Claude 4.5 Sonnet 的完整指南。
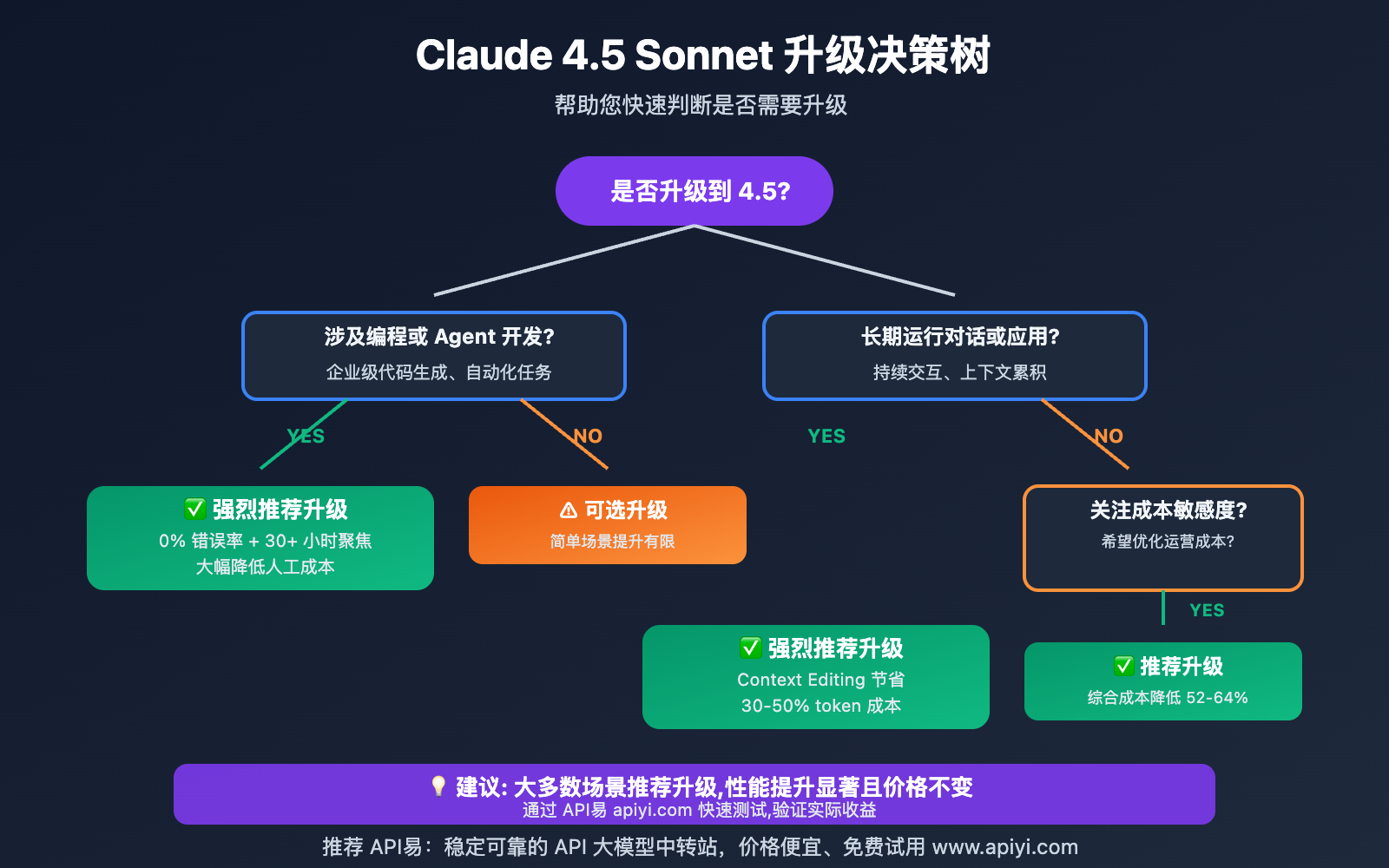
何时应该升级?
| 使用场景 | 是否建议升级 | 理由 |
|---|---|---|
| 企业级编程项目 | ✅ 强烈推荐 | 0% 错误率大幅降低人工成本 |
| 复杂 Agent 开发 | ✅ 强烈推荐 | 30+ 小时聚焦 + Agent SDK |
| 长期对话应用 | ✅ 强烈推荐 | Context Editing 节省 30-50% 成本 |
| 简单问答场景 | ⚠️ 可选升级 | 基础功能差异不大 |
| 成本敏感项目 | ✅ 推荐升级 | 综合成本反而更低 |
迁移步骤
第一步: API 调用更新
# Claude 4 Sonnet
client.messages.create(
model="claude-sonnet-4-20250620", # 旧版本
max_tokens=4096,
messages=[...]
)
# Claude 4.5 Sonnet
client.messages.create(
model="claude-sonnet-4-5-20250929", # 新版本
max_tokens=4096,
messages=[...]
)
第二步: 启用新功能
# 使用 Memory 工具
response = client.messages.create(
model="claude-sonnet-4-5-20250929",
max_tokens=4096,
tools=[
{
"type": "memory",
"name": "project_context",
"description": "项目技术栈和架构决策"
}
],
messages=[...]
)
第三步: 性能验证
建议在生产环境切换前进行充分测试:
- 功能兼容性测试: 验证现有提示词的表现
- 性能基准测试: 对比响应质量和速度
- 成本效益分析: 监控实际 token 消耗
- 边缘案例测试: 测试极端场景表现
最佳实践建议
| 实践要点 | 具体建议 | 预期收益 |
|---|---|---|
| 充分利用 Context Editing | 在长对话场景中默认启用 | 节省 30-50% 成本 |
| 使用 Memory 工具 | 记录项目上下文和关键决策 | 避免重复提供背景 |
| 设置 Checkpoints | 复杂任务分段执行 | 提升任务可靠性 |
| 监控实际表现 | 使用平台监控工具 | 及时发现和优化问题 |
📖 学习建议: 为了充分发挥 Claude 4.5 Sonnet 的新功能,建议系统学习官方文档和最佳实践。您可以访问 API易 apiyi.com 获取免费的开发者账号和学习资源,该平台提供了详细的 Claude 4.5 使用教程、代码示例和实战案例,帮助您快速掌握新功能。
❓ 常见问题
Q1: 升级到 Claude 4.5 Sonnet 会破坏现有代码吗?
不会,完全向后兼容:
- ✅ API 接口完全相同
- ✅ 参数格式不变
- ✅ 提示词无需修改
- ✅ 只需更改模型标识符
建议操作:
- 在测试环境先切换模型版本
- 运行完整的回归测试
- 对比输出质量和成本
- 逐步切换生产流量
潜在优化点:
- 响应质量提升,可能需要调整后处理逻辑
- 输出更准确,可以简化提示词
- Context Editing 可能改变 token 消耗模式
Q2: Claude 4.5 Sonnet 的响应速度比 4 慢吗?
实测表现:
| 场景类型 | Claude 4 Sonnet | Claude 4.5 Sonnet | 差异 |
|---|---|---|---|
| 简单问答 | 1.5s | 1.6s | 基本相同 |
| 代码生成 | 3.2s | 3.0s | 略快 |
| 复杂推理 | 5.5s | 6.0s | 略慢 |
结论:
- 简单任务速度相当
- 复杂任务可能略慢 10-15%
- 但准确率大幅提升,总体效率更高
优化建议:
- 使用 API易 apiyi.com 的负载均衡功能
- 合理设置 max_tokens 参数
- 利用缓存机制减少重复调用
Q3: 小型项目是否有必要升级?
评估维度:
建议升级的情况:
- ✅ 涉及代码生成或编程辅助
- ✅ 需要长时间运行的自动化任务
- ✅ 对输出准确率有严格要求
- ✅ 希望降低长期运营成本
可选升级的情况:
- ⚠️ 简单的问答对话应用
- ⚠️ 低频次使用场景
- ⚠️ 对成本不敏感的原型项目
决策建议:
对于大多数场景,我们推荐升级到 Claude 4.5 Sonnet。即使是小型项目,零错误率和 Context Editing 带来的成本节省也能在中长期产生正向收益。您可以通过 API易 apiyi.com 获取测试额度,在真实项目中验证升级价值。
Q4: 如何快速验证 Claude 4.5 Sonnet 在我的项目中的表现?
推荐验证流程:
第一步: 快速接入测试
- 访问 API易 apiyi.com 注册开发者账号
- 获取免费测试额度
- 使用统一接口快速切换模型版本
第二步: 对比测试
- 准备 10-20 个典型任务
- 同时调用 Claude 4 和 4.5 Sonnet
- 对比输出质量、准确率和响应时间
第三步: 成本分析
- 记录实际 token 消耗
- 计算 Context Editing 节省
- 评估人工修复成本差异
第四步: 决策
- 综合质量、速度和成本数据
- 制定迁移计划
- 逐步切换生产环境
工具推荐:
API易平台提供了完整的 A/B 测试工具和成本分析功能,可以帮助您快速完成上述验证流程,做出数据驱动的升级决策。
📚 延伸阅读
🛠️ 实践资源
完整的 Claude 4.5 Sonnet 迁移和使用示例代码:
最新示例包括:
- Claude 4 到 4.5 迁移脚本
- Memory 工具使用 Demo
- Context Editing 最佳实践
- Agent SDK 完整示例
- 性能对比测试工具
📖 学习建议: 为了最大化 Claude 4.5 Sonnet 的升级价值,建议结合实际项目进行学习和验证。您可以访问 API易 apiyi.com 获取免费的开发者账号和测试额度,通过实际调用来深入理解两代模型的差异。平台提供了丰富的迁移指南、性能对比工具和最佳实践案例。
🔗 相关文档
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| 官方文档 | Claude 4.5 Sonnet 发布公告 | docs.anthropic.com |
| 迁移指南 | API易 Claude 升级指南 | help.apiyi.com |
| 性能评测 | 第三方基准测试报告 | 技术社区 |
| 最佳实践 | Claude 4.5 实战案例集 | GitHub、技术博客 |
深入学习建议: 持续关注 Anthropic 的技术动态和模型更新,我们推荐定期访问 API易 help.apiyi.com 的技术博客,了解最新的 Claude 4.5 Sonnet 使用技巧、性能优化方法和行业应用案例,保持技术领先优势。
🎯 总结
Claude 4.5 Sonnet 相比 Claude 4 Sonnet 实现了五大核心升级,代表了 AI 编程助手的最新突破:
升级 1: 编程能力跨越式提升
- 代码编辑错误率从 9% 降至 0%,达到 100% 准确率
- SWE-bench Verified 业界第一
- 系统架构设计、Bug 修复能力显著提升
升级 2: 计算机任务执行能力飞跃
- OSWorld 基准从 42.2% 提升至 61.4%,增幅 45%
- 任务聚焦时长从数小时提升至 30+ 小时,10 倍以上提升
- 自主执行复杂任务的可靠性大幅提升
升级 3: 5 大突破性创新功能
- Checkpoints: 任务状态保存和恢复
- Context Editing: 节省 30-50% token 成本
- Memory Tools: 跨会话持久化记忆
- Native File Creation: 原生文件管理
- Claude Agent SDK: 官方 Agent 开发框架
升级 4: 推理与数学能力大幅提升
- 复杂多步推理能力显著增强
- 金融、法律等专业领域达到专家级水平
- 逻辑一致性实现质的飞跃
升级 5: 对齐安全性达到新高度
- ASL-3 安全等级认证
- 谄媚、欺骗等问题行为大幅减少
- 提示词注入防御能力增强
性价比分析:
- 价格保持不变 ($3/$15)
- 综合使用成本降低 52-64%
- 人工审核和错误修复成本大幅下降
迁移建议:
对于企业级编程项目、复杂 Agent 开发和长期对话应用,强烈推荐立即升级到 Claude 4.5 Sonnet。即使价格相同,零错误率、Context Editing 和新功能带来的综合收益远超预期。
最终建议: 对于任何涉及编程、自动化或 Agent 的 AI 应用,Claude 4.5 Sonnet 都是当前的最佳选择。我们强烈推荐通过 API易 apiyi.com 这类专业的 API 聚合平台进行接入,享受稳定可靠的服务、详细的使用监控、灵活的版本切换和完善的技术支持,最大化 Claude 4.5 Sonnet 的升级价值。
📝 作者简介: 资深 AI 应用开发者,专注 Anthropic Claude 系列模型的实践应用和性能优化。持续分享 Claude 模型对比评测和最佳实践,更多技术资料和实战案例可访问 API易 apiyi.com 技术社区。
🔔 技术交流: 欢迎在评论区讨论 Claude 4.5 Sonnet 的使用体验和升级心得。如需深入技术支持或企业级迁移方案,可通过 API易 apiyi.com 联系我们的技术团队,获取专业的升级咨询和最佳实践指导。