Author's Note: Detailed explanation of Claude Haiku 4.5 API integration methods, covering OpenAI SDK compatible access, official SDK usage, advanced feature configuration, and production environment deployment, helping developers quickly integrate the fastest near-frontier intelligent model.
Claude Haiku 4.5 API integration is a new challenge for many developers. This article will detail how to quickly integrate this latest high-performance model through standardized API interfaces.
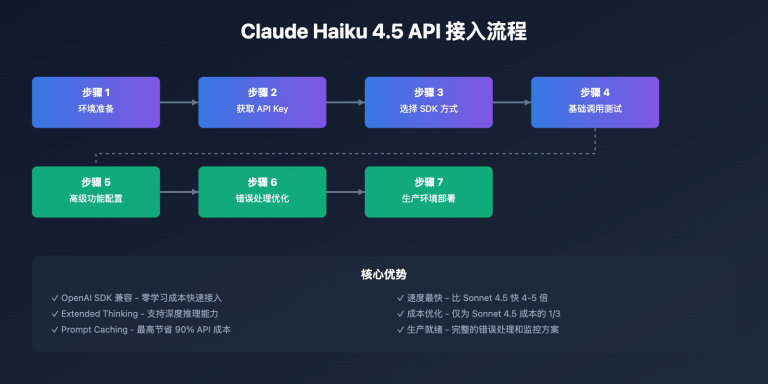
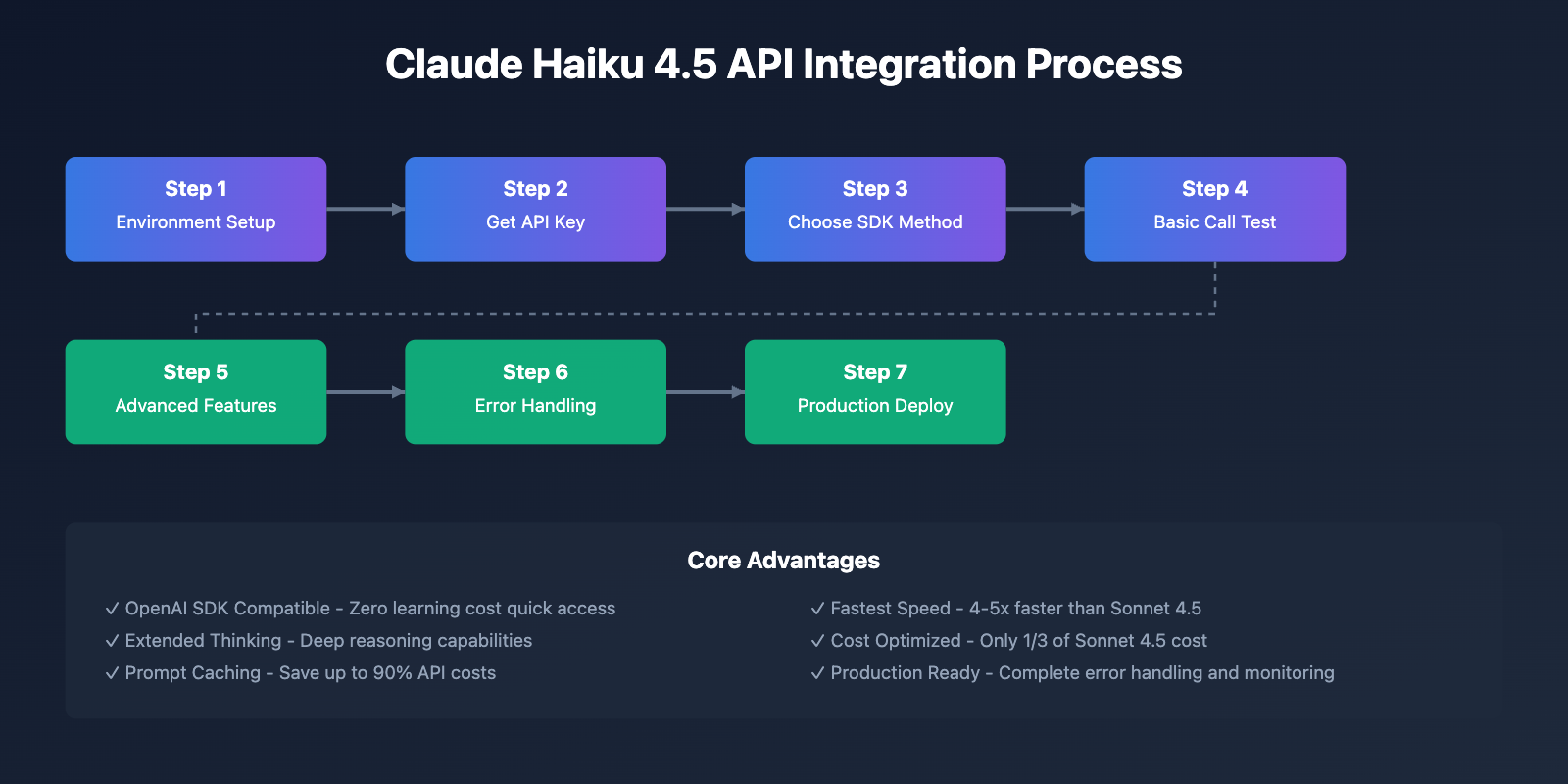
The article covers core points including environment preparation, OpenAI SDK compatible access, Anthropic official SDK usage, and advanced feature configuration, helping you quickly master the complete workflow of Claude Haiku 4.5 API integration.
Core Value: Through this article, you will learn how to complete API integration in 10 minutes and master the usage methods of advanced features like Extended Thinking and Prompt Caching, significantly improving development efficiency.
Claude Haiku 4.5 API Integration Background
Claude Haiku 4.5 is Anthropic's latest high-performance small model released on October 15, 2025, officially positioned as the "fastest near-frontier intelligent model." While maintaining coding performance close to Claude Sonnet 4, this model achieves 2x+ speed improvement and one-third the cost.
For developers, Claude Haiku 4.5 API integration has two mainstream approaches:
- OpenAI SDK Compatible Access: Through third-party API aggregation platforms, using standard OpenAI SDK calls with zero learning cost
- Anthropic Official SDK Access: Using official Python/TypeScript SDK for complete feature support
This article will detail both integration approaches and how to configure advanced features like Extended Thinking, Prompt Caching, and Streaming to help developers quickly build production-grade applications.
Claude Haiku 4.5 API Integration Preparation
Before starting Claude Haiku 4.5 API integration, complete the following preparation work:
📋 Environment Requirements
| Environment Type | Recommended Config | Minimum Requirements |
|---|---|---|
| Python Version | Python 3.10+ | Python 3.8+ |
| Node.js Version | Node.js 18+ | Node.js 16+ |
| Network Environment | Stable international network connection | Can access API servers |
| Development Tools | VS Code / PyCharm | Any text editor |
🔑 Getting API Key
Claude Haiku 4.5 API integration requires a valid API Key. Depending on your chosen integration method, there are two ways to obtain it:
| Method | Use Case | Advantages | Access URL |
|---|---|---|---|
| Anthropic Official | Direct official API usage | Complete native features, high stability | console.anthropic.com |
| API易 Aggregation Platform | OpenAI SDK compatible calls | Multi-model switching support, better cost | apiyi.com |
| AWS Bedrock | AWS cloud environment deployment | Enterprise-grade security, regional deployment | AWS Console |
| Google Vertex AI | GCP cloud environment deployment | Google Cloud ecosystem integration | Google Cloud Console |
🎯 Integration Recommendation: For quick testing and development, we recommend integrating through the API易 apiyi.com platform. This platform provides OpenAI SDK compatible interfaces, allowing you to use familiar OpenAI calling methods to directly use Claude Haiku 4.5 without learning new SDKs, while also supporting one-click multi-model switching and cost comparison features.
💻 Installing Required SDKs
Install the corresponding SDK based on your chosen programming language:
Python Environment:
# Method 1: OpenAI SDK (Recommended for quick access)
pip install openai
# Method 2: Anthropic Official SDK (Complete features)
pip install anthropic
# Optional: Install HTTP client optimization library
pip install httpx
Node.js Environment:
# Method 1: OpenAI SDK (Recommended for quick access)
npm install openai
# Method 2: Anthropic Official SDK (Complete features)
npm install @anthropic-ai/sdk
# TypeScript support
npm install -D @types/node typescript
Claude Haiku 4.5 API Integration Method 1: OpenAI SDK Compatible Access
OpenAI SDK compatible access is the simplest and fastest Claude Haiku 4.5 API integration method, especially suitable for developers already familiar with OpenAI API.
🚀 Core Advantages
- Zero Learning Cost: Use existing OpenAI SDK code, only need to modify configuration
- Quick Switching: One-click switching between GPT and Claude models for comparison
- Unified Management: Unified management of multiple model calls and costs through aggregation platforms
- Cost Optimization: Aggregation platforms usually provide better prices
💻 Python Quick Integration Example
from openai import OpenAI
# Configure client - Using API易 aggregation platform
client = OpenAI(
api_key="YOUR_API_KEY", # Get from apiyi.com
base_url="https://vip.apiyi.com/v1" # API易 OpenAI compatible endpoint
)
# Call Claude Haiku 4.5
response = client.chat.completions.create(
model="claude-haiku-4-5", # Or use full ID: claude-haiku-4-5-20251001
messages=[
{
"role": "system",
"content": "You are a professional Python programming assistant, skilled at writing high-quality, high-performance code."
},
{
"role": "user",
"content": "Please help me write a Python implementation of a quicksort algorithm, requiring clean code with detailed comments."
}
],
temperature=0.7,
max_tokens=2000
)
# Output result
print(response.choices[0].message.content)
🎯 Key Configuration Explanation
| Parameter | Description | Recommended Value |
|---|---|---|
model |
Model ID | claude-haiku-4-5 or claude-haiku-4-5-20251001 |
temperature |
Creativity control | 0.7(balanced), 0.3(precise), 0.9(creative) |
max_tokens |
Maximum output length | 2000-4000(regular), max 64000 |
base_url |
API endpoint | Use URL provided by aggregation platform |
🔍 Testing Recommendation: Before formal integration, we recommend getting free test credits through API易 apiyi.com first to verify if Claude Haiku 4.5 API integration is working properly. The platform provides online testing tools and detailed call logs for quick problem identification.
🌊 Streaming Output Support
Streaming output is crucial for chat applications, and Claude Haiku 4.5's ultra-fast speed shows even more advantages in streaming scenarios:
# Streaming call example
stream = client.chat.completions.create(
model="claude-haiku-4-5",
messages=[
{"role": "user", "content": "Explain what quantum computing is in 200 words"}
],
stream=True # Enable streaming output
)
# Real-time output
for chunk in stream:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="", flush=True)
Claude Haiku 4.5 API Integration Method 2: Anthropic Official SDK
If you need to use Claude's unique advanced features like Extended Thinking and Context Awareness, we recommend using the Anthropic official SDK for Claude Haiku 4.5 API integration.
🔧 Python Official SDK Integration
import anthropic
# Initialize client
client = anthropic.Anthropic(
api_key="YOUR_ANTHROPIC_API_KEY" # Get from console.anthropic.com
)
# Basic call
message = client.messages.create(
model="claude-haiku-4-5-20251001",
max_tokens=4096,
messages=[
{
"role": "user",
"content": "Please write an efficient algorithm in Python to calculate Fibonacci sequence"
}
]
)
print(message.content[0].text)
🧠 Enable Extended Thinking
Extended Thinking is one of Claude Haiku 4.5's core new features, allowing the model to perform deep reasoning:
# Enable extended thinking
message = client.messages.create(
model="claude-haiku-4-5-20251001",
max_tokens=4096,
thinking={
"type": "enabled",
"budget_tokens": 10000 # Thinking token budget, default 128K
},
messages=[
{
"role": "user",
"content": "Analyze the time complexity of the following code and provide optimization suggestions:\n\n[Your code]"
}
]
)
# Output thinking process and final answer
for block in message.content:
if block.type == "thinking":
print(f"Thinking process: {block.thinking}")
elif block.type == "text":
print(f"Final answer: {block.text}")
💾 Configure Prompt Caching
Prompt Caching can significantly reduce costs for repeated calls, saving up to 90% of API fees:
# Using Prompt Caching
message = client.messages.create(
model="claude-haiku-4-5-20251001",
max_tokens=2048,
system=[
{
"type": "text",
"text": "You are a professional code review assistant...", # Long system prompt
"cache_control": {"type": "ephemeral"} # Cache this part
}
],
messages=[
{
"role": "user",
"content": "Review this code:\n\n[Code content]"
}
]
)
💰 Cost Optimization Suggestion: If your application frequently uses the same system prompts or context, we strongly recommend enabling Prompt Caching. Based on our testing, for applications containing extensive background knowledge (like customer service bots, document Q&A systems), enabling caching can reduce API costs by 70-90%. You can monitor cache effectiveness in real-time through API易 apiyi.com's cost analysis tools.
Claude Haiku 4.5 API Complete Project Example
The following is a complete chatbot project example showing how to integrate Claude Haiku 4.5 API in practical applications.
🤖 Intelligent Chat Assistant Implementation
import anthropic
import os
from typing import List, Dict
class ClaudeHaikuChatbot:
"""Claude Haiku 4.5 Chatbot"""
def __init__(self, api_key: str):
self.client = anthropic.Anthropic(api_key=api_key)
self.conversation_history: List[Dict] = []
def add_message(self, role: str, content: str):
"""Add message to conversation history"""
self.conversation_history.append({
"role": role,
"content": content
})
def chat(self, user_input: str, use_thinking: bool = False) -> str:
"""Send message and get response"""
# Add user message
self.add_message("user", user_input)
# Build request parameters
params = {
"model": "claude-haiku-4-5-20251001",
"max_tokens": 4096,
"messages": self.conversation_history
}
# Optional: Enable extended thinking
if use_thinking:
params["thinking"] = {
"type": "enabled",
"budget_tokens": 10000
}
# Call API
try:
message = self.client.messages.create(**params)
# Extract response content
response_text = ""
for block in message.content:
if block.type == "text":
response_text = block.text
break
# Add assistant response to history
self.add_message("assistant", response_text)
return response_text
except anthropic.APIError as e:
return f"API Error: {str(e)}"
def reset(self):
"""Reset conversation history"""
self.conversation_history = []
# Usage example
if __name__ == "__main__":
# Initialize chatbot
chatbot = ClaudeHaikuChatbot(
api_key=os.getenv("ANTHROPIC_API_KEY")
)
# Multi-turn conversation
print("Chatbot started! (Type 'quit' to exit)")
while True:
user_input = input("\nYou: ").strip()
if user_input.lower() == 'quit':
break
if not user_input:
continue
# Get response
response = chatbot.chat(user_input, use_thinking=True)
print(f"\nClaude: {response}")
📝 Code Assistant Example
class CodeAssistant:
"""Claude Haiku 4.5 based code assistant"""
def __init__(self, api_key: str):
self.client = anthropic.Anthropic(api_key=api_key)
def generate_code(self, description: str, language: str = "python") -> str:
"""Generate code based on description"""
message = self.client.messages.create(
model="claude-haiku-4-5-20251001",
max_tokens=4096,
system=f"You are a professional {language} programmer, skilled at writing clear, efficient code.",
messages=[
{
"role": "user",
"content": f"Please implement the following functionality in {language}:\n\n{description}\n\nRequirements:\n1. Clean, readable code\n2. Include detailed comments\n3. Consider edge cases"
}
]
)
return message.content[0].text
def review_code(self, code: str) -> str:
"""Code review and optimization suggestions"""
message = self.client.messages.create(
model="claude-haiku-4-5-20251001",
max_tokens=4096,
thinking={
"type": "enabled",
"budget_tokens": 10000
},
messages=[
{
"role": "user",
"content": f"Please review the following code and provide optimization suggestions:\n\n```\n{code}\n```\n\nPlease analyze from the following dimensions:\n1. Performance optimization\n2. Code standards\n3. Potential bugs\n4. Maintainability"
}
]
)
# Extract text response (excluding thinking process)
for block in message.content:
if block.type == "text":
return block.text
return "Unable to generate review result"
# Usage example
assistant = CodeAssistant(api_key=os.getenv("ANTHROPIC_API_KEY"))
# Generate code
code = assistant.generate_code(
"Implement an LRU cache supporting get and put operations with O(1) time complexity",
language="python"
)
print(code)
# Review code
review = assistant.review_code(code)
print(review)
Claude Haiku 4.5 API Advanced Features Integration
Claude Haiku 4.5 provides multiple advanced features that can significantly improve application performance and reduce costs when used appropriately.
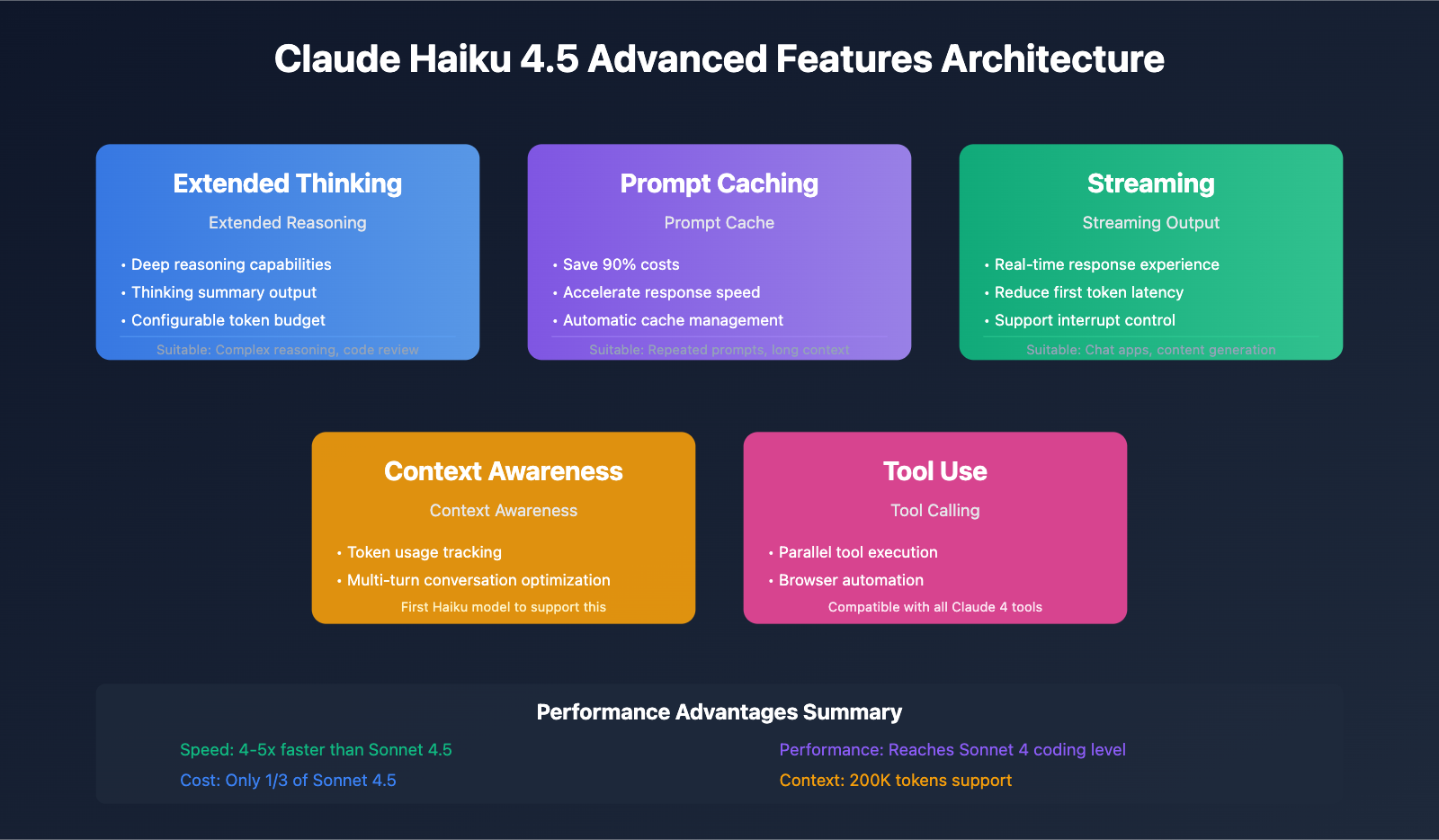
🧠 Extended Thinking Configuration Details
Extended Thinking allows the model to perform deep reasoning, especially suitable for complex programming and analysis tasks:
| Configuration Parameter | Description | Recommended Value | Impact |
|---|---|---|---|
type |
Enable type | "enabled" |
Enable extended thinking |
budget_tokens |
Thinking token budget | 10000-50000 | Control reasoning depth |
return_thinking |
Return thinking process | true/false |
Whether to view reasoning process |
Usage Recommendations:
- Simple tasks: Don't enable, save costs
- Medium complexity: 10000-20000 tokens
- High complexity: 50000+ tokens
- Debug mode:
return_thinking: trueto view reasoning process
💾 Prompt Caching Best Practices
Prompt Caching is a key feature for reducing Claude Haiku 4.5 API costs:
Content Suitable for Caching:
- ✅ System prompts (over 1024 tokens)
- ✅ Knowledge base context (FAQ, product documentation)
- ✅ Codebase information (project structure, API documentation)
- ✅ Conversation history (multi-turn conversations)
Content Not Suitable for Caching:
- ❌ Frequently changing data
- ❌ Short prompts (less than 1024 tokens)
- ❌ One-time use content
🛠️ Tool Selection Recommendation: To maximize Prompt Caching effectiveness, you need to monitor cache hit rates and cost savings. We recommend using API易 apiyi.com's cost analysis features, which can display cache usage for each call in real-time, helping you optimize caching strategies and ensure the best cost-effectiveness.
🌊 Streaming Output Implementation
Streaming output can significantly improve user experience, especially for long text generation:
# Streaming output - OpenAI SDK method
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1"
)
stream = client.chat.completions.create(
model="claude-haiku-4-5",
messages=[{"role": "user", "content": "Write a 500-word technical blog"}],
stream=True
)
for chunk in stream:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
# Streaming output - Anthropic SDK method
import anthropic
client = anthropic.Anthropic(api_key="YOUR_API_KEY")
with client.messages.stream(
model="claude-haiku-4-5-20251001",
max_tokens=4096,
messages=[{"role": "user", "content": "Write a technical blog"}]
) as stream:
for text in stream.text_stream:
print(text, end="", flush=True)
Claude Haiku 4.5 API Error Handling and Retry Strategies
In production environments, robust error handling mechanisms are crucial.
⚠️ Common Error Types
| Error Type | HTTP Status Code | Cause | Solution |
|---|---|---|---|
| Authentication Error | 401 | Invalid or expired API Key | Check API Key configuration |
| Rate Limit Exceeded | 429 | Request rate exceeded | Implement exponential backoff retry |
| Request Timeout | 504 | Network or server timeout | Increase timeout, implement retry |
| Server Error | 500/503 | Temporary server failure | Automatic retry |
| Parameter Error | 400 | Invalid request parameters | Check parameter format |
🔄 Exponential Backoff Retry Implementation
import time
import random
from typing import Callable, Any
def retry_with_exponential_backoff(
func: Callable,
max_retries: int = 5,
initial_delay: float = 1.0,
max_delay: float = 60.0,
exponential_base: float = 2.0,
jitter: bool = True
) -> Any:
"""
Exponential backoff retry decorator
Args:
func: Function to retry
max_retries: Maximum retry attempts
initial_delay: Initial delay (seconds)
max_delay: Maximum delay (seconds)
exponential_base: Exponential base
jitter: Whether to add random jitter
"""
retries = 0
delay = initial_delay
while retries < max_retries:
try:
return func()
except anthropic.RateLimitError as e:
retries += 1
if retries >= max_retries:
raise
# Calculate delay time
delay = min(delay * exponential_base, max_delay)
# Add random jitter (avoid thundering herd effect)
if jitter:
delay = delay * (0.5 + random.random())
print(f"Rate limit triggered, waiting {delay:.2f} seconds before retry ({retries}/{max_retries})")
time.sleep(delay)
except anthropic.APIError as e:
# Other API errors
print(f"API Error: {str(e)}")
raise
# Usage example
def make_api_call():
return client.messages.create(
model="claude-haiku-4-5-20251001",
max_tokens=1024,
messages=[{"role": "user", "content": "Hello"}]
)
response = retry_with_exponential_backoff(make_api_call)
🛡️ Complete Error Handling Framework
import logging
from typing import Optional
class ClaudeAPIClient:
"""Claude API client with complete error handling"""
def __init__(self, api_key: str, max_retries: int = 3):
self.client = anthropic.Anthropic(api_key=api_key)
self.max_retries = max_retries
self.logger = logging.getLogger(__name__)
def call_with_retry(
self,
messages: list,
model: str = "claude-haiku-4-5-20251001",
**kwargs
) -> Optional[str]:
"""API call with retry"""
for attempt in range(self.max_retries):
try:
response = self.client.messages.create(
model=model,
messages=messages,
**kwargs
)
# Extract text content
for block in response.content:
if block.type == "text":
return block.text
return None
except anthropic.RateLimitError as e:
self.logger.warning(f"Rate limit triggered (attempt {attempt + 1}/{self.max_retries})")
if attempt < self.max_retries - 1:
time.sleep(2 ** attempt) # Exponential backoff
else:
self.logger.error("Exceeded maximum retry attempts")
raise
except anthropic.APIConnectionError as e:
self.logger.error(f"Network connection error: {str(e)}")
if attempt < self.max_retries - 1:
time.sleep(1)
else:
raise
except anthropic.AuthenticationError as e:
self.logger.error(f"Authentication failed: {str(e)}")
raise # Don't retry authentication errors
except anthropic.APIError as e:
self.logger.error(f"API Error: {str(e)}")
raise
return None
🚨 Error Handling Recommendation: In production environments, we recommend implementing comprehensive error monitoring and alerting mechanisms. If you encounter frequent timeouts or rate limiting issues during use, it may be due to insufficient stability of the API service provider. We recommend choosing aggregation platforms like API易 apiyi.com that have multi-node deployment and load balancing capabilities, which provide higher availability guarantees and detailed error logs to help you quickly identify and resolve issues.
Claude Haiku 4.5 API Performance Optimization and Best Practices
Optimizing Claude Haiku 4.5 API integration performance can significantly improve application experience and reduce costs.
⚡ Core Performance Optimization Strategies
| Optimization Direction | Specific Measures | Expected Effect |
|---|---|---|
| Reduce Latency | Use streaming output, select nearest node | First token latency reduced by 50%+ |
| Reduce Costs | Enable Prompt Caching, batch processing | Cost reduced by 70-90% |
| Improve Concurrency | Connection pooling, async calls | Throughput increased by 3-5x |
| Optimize Prompts | Streamline prompts, reasonable parameter configuration | Token usage reduced by 30%+ |
🚀 Async Concurrent Calls
For scenarios requiring processing large numbers of requests, async calls can significantly improve throughput:
import asyncio
from anthropic import AsyncAnthropic
async def process_batch(prompts: list[str]) -> list[str]:
"""Batch async processing of multiple requests"""
client = AsyncAnthropic(api_key="YOUR_API_KEY")
async def process_one(prompt: str) -> str:
message = await client.messages.create(
model="claude-haiku-4-5-20251001",
max_tokens=1024,
messages=[{"role": "user", "content": prompt}]
)
return message.content[0].text
# Concurrently execute all requests
tasks = [process_one(prompt) for prompt in prompts]
results = await asyncio.gather(*tasks)
return results
# Usage example
prompts = [
"Summarize this text: ...",
"Translate to English: ...",
"Generate title: ..."
]
results = asyncio.run(process_batch(prompts))
💰 Cost Optimization Checklist
Immediately Implementable:
- ✅ Enable Prompt Caching (save 90%)
- ✅ Use Message Batches API (save 50%)
- ✅ Selective use of Extended Thinking (avoid unnecessary reasoning costs)
- ✅ Optimize
max_tokensparameter (avoid waste)
Medium-term Optimization:
- ✅ Implement intelligent model routing (simple tasks use Haiku, complex tasks use Sonnet)
- ✅ Monitor and analyze token usage patterns
- ✅ Optimize system prompt length
Long-term Strategy:
- ✅ Establish cost warning mechanisms
- ✅ Regularly evaluate model cost-effectiveness
- ✅ Consider using aggregation platform discounts
💡 Best Practice Recommendation: To achieve optimal cost-effectiveness, we recommend combining multiple optimization strategies. Based on our practical experience, using Claude Haiku 4.5 through the API易 apiyi.com platform, combined with Prompt Caching and batch processing, can reduce overall API costs to about 30% of official direct calls while gaining better stability and technical support.
Claude Haiku 4.5 API Production Environment Deployment Recommendations
Deploying Claude Haiku 4.5 API to production environments requires considering security, reliability, and monitorability.
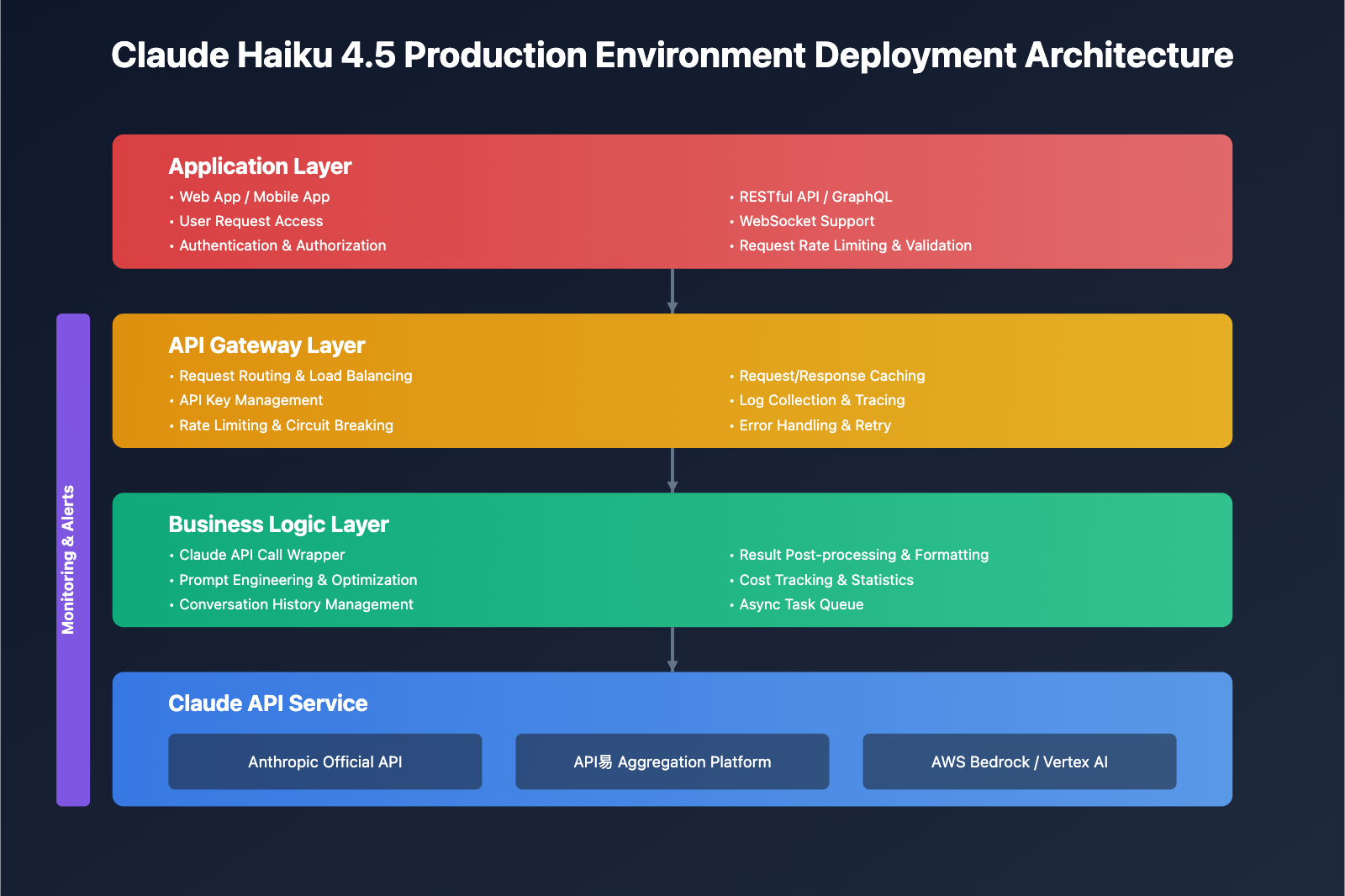
🔐 Security Configuration
API Key Management:
- ✅ Use environment variables for storage, don't hardcode
- ✅ Regularly rotate API Keys
- ✅ Use different Keys for different environments
- ✅ Implement Key usage monitoring and alerts
Access Control:
- ✅ Implement user-level rate limiting
- ✅ Log all API call logs
- ✅ Desensitize sensitive data
- ✅ Implement IP whitelist (if needed)
📊 Monitoring and Logging
Key Monitoring Metrics:
| Metric Type | Specific Metrics | Alert Threshold Recommendation |
|---|---|---|
| Availability | API success rate | < 99% |
| Performance | Average response time | > 3 seconds |
| Cost | Daily token consumption | 20% over budget |
| Errors | 5xx error rate | > 1% |
| Rate Limiting | 429 error count | > 10 times/hour |
Logging Recommendations:
import logging
import json
from datetime import datetime
class APILogger:
"""Claude API call logger"""
def __init__(self):
self.logger = logging.getLogger("claude_api")
handler = logging.FileHandler("claude_api.log")
handler.setFormatter(logging.Formatter(
'%(asctime)s - %(levelname)s - %(message)s'
))
self.logger.addHandler(handler)
self.logger.setLevel(logging.INFO)
def log_request(self, model: str, messages: list, **kwargs):
"""Log request"""
log_data = {
"timestamp": datetime.now().isoformat(),
"type": "request",
"model": model,
"message_count": len(messages),
"params": kwargs
}
self.logger.info(json.dumps(log_data))
def log_response(self, response, duration: float, cost: float):
"""Log response"""
log_data = {
"timestamp": datetime.now().isoformat(),
"type": "response",
"duration_ms": duration * 1000,
"input_tokens": response.usage.input_tokens,
"output_tokens": response.usage.output_tokens,
"estimated_cost": cost,
"success": True
}
self.logger.info(json.dumps(log_data))
def log_error(self, error: Exception, context: dict):
"""Log error"""
log_data = {
"timestamp": datetime.now().isoformat(),
"type": "error",
"error_type": type(error).__name__,
"error_message": str(error),
"context": context
}
self.logger.error(json.dumps(log_data))
🚀 Deployment Environment Recommendations
Development Environment:
- Use test API Key
- Enable detailed logging
- Use smaller token limits
Staging Environment:
- Consistent with production environment configuration
- Perform stress testing
- Verify monitoring alerts
Production Environment:
- Use production API Key
- Enable caching and optimization
- Implement complete monitoring and alerts
- Configure automatic retry and circuit breaking
🔧 Deployment Recommendation: For enterprise applications, we strongly recommend using professional API aggregation platforms like API易 apiyi.com. This platform provides out-of-the-box monitoring dashboards, cost analysis, automatic retry, and multi-node load balancing enterprise features that can significantly reduce operational complexity. Meanwhile, the platform supports one-click switching between different API providers, allowing quick switching to backup services when main services have issues, ensuring business continuity.
❓ Claude Haiku 4.5 API Integration Common Questions
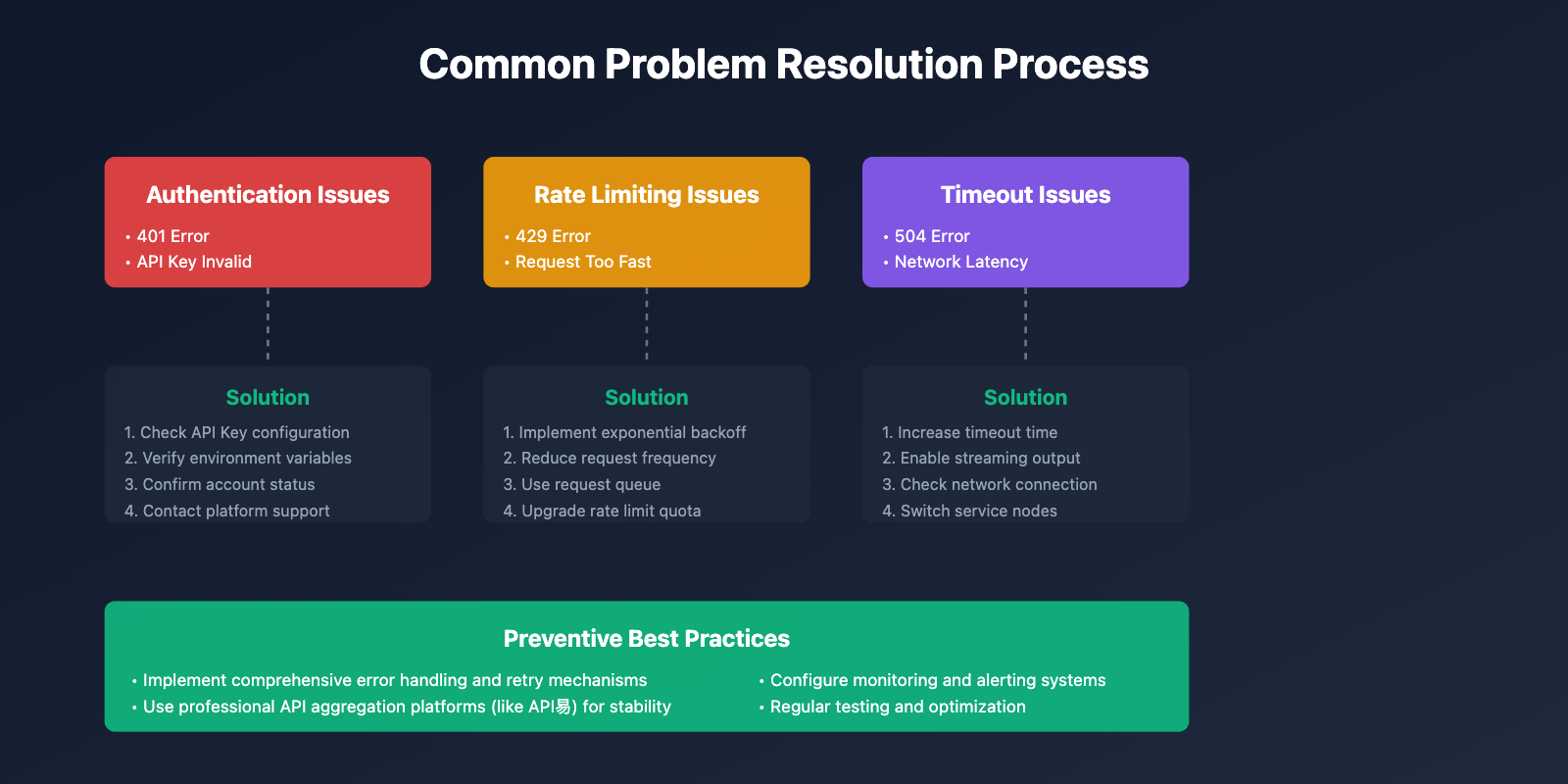
Q1: Claude Haiku 4.5 API integration reports 401 authentication error, what to do?
Authentication errors are usually caused by the following reasons:
Troubleshooting Steps:
- Check API Key format: Ensure complete copy, no extra spaces
- Verify environment variables: Use
echo $ANTHROPIC_API_KEYto check - Confirm account status: Login to console to check if account is normal
- Check API endpoint: Confirm using correct base_url
Code Example:
import os
# Correct configuration method
api_key = os.getenv("ANTHROPIC_API_KEY")
if not api_key:
raise ValueError("API Key not set")
client = anthropic.Anthropic(api_key=api_key)
Professional Recommendation: If using aggregation platforms like API易 apiyi.com, we recommend testing API Key validity in the platform console first. The platform provides convenient online testing tools for quick verification of configuration correctness.
Q2: How to choose between OpenAI SDK compatible access or official SDK?
The choice mainly depends on your needs:
Choose OpenAI SDK Compatible Access (Recommended for):
- ✅ Already have OpenAI API experience
- ✅ Need to quickly switch between multiple models
- ✅ Prioritize development speed
- ✅ Don't need Claude's unique advanced features
Choose Anthropic Official SDK (Recommended for):
- ✅ Need Extended Thinking functionality
- ✅ Need Context Awareness functionality
- ✅ Need complete Prompt Caching control
- ✅ Pursue optimal performance and feature completeness
Recommended Approach: For quick integration and testing, we recommend first using OpenAI SDK compatible method through API易 apiyi.com, verify basic functionality, then switch to official SDK if advanced features are needed. This progressive integration can maximize development efficiency.
Q3: Claude Haiku 4.5 API response is slow, how to optimize?
Multiple dimensions of response speed optimization:
Immediately Effective Optimizations:
- ✅ Enable streaming output (significantly improve user experience)
- ✅ Reduce
max_tokenssetting (reduce generation time) - ✅ Optimize prompt length (reduce input tokens)
Architecture-level Optimizations:
- ✅ Use async calls (improve concurrent processing capability)
- ✅ Implement request caching (return same requests directly)
- ✅ Select geographically nearest API nodes
Service Provider Selection:
- ✅ Compare response latency of different service providers
- ✅ Choose platforms with multi-node deployment
- ✅ Consider using load-balanced aggregation services
Testing Recommendation: We recommend conducting actual performance testing through API易 apiyi.com. This platform provides detailed response time statistics and multi-node support to help you find optimal service configuration.
Q4: How to reduce Claude Haiku 4.5 API call costs?
Cost optimization is a long-term focus:
High Priority Measures (Save 70-90%):
- Enable Prompt Caching: Cache repeated system prompts and context
- Use Message Batches API: Batch process requests to save 50%
- Optimize prompts: Streamline unnecessary descriptions and examples
Medium Priority Measures (Save 20-30%):
- Intelligent model routing: Simple tasks use Haiku, complex tasks use Sonnet
- Control output length: Reasonably set
max_tokens - Selective use of Extended Thinking: Only enable when necessary
Long-term Strategy:
- Monitor token usage: Establish cost tracking and warnings
- Regular evaluation: Compare prices of different service providers
- Bulk purchasing: Choose aggregation platforms with discounts
Cost Optimization Recommendation: Based on our practical experience, using Claude Haiku 4.5 through API易 apiyi.com, combined with the platform's cost analysis tools and optimization suggestions, can control overall costs to 30-40% of official direct calls while gaining better service stability.
Q5: When is Extended Thinking feature worth using?
Extended Thinking will increase token consumption, requiring careful consideration:
Recommended Use Cases:
- ✅ Complex code review and optimization suggestions
- ✅ Multi-step logical reasoning tasks
- ✅ Technical problems requiring deep analysis
- ✅ Mathematical and scientific calculation problems
Not Recommended Use Cases:
- ❌ Simple text generation
- ❌ Basic Q&A tasks
- ❌ Mechanical tasks like code formatting
- ❌ Cost-sensitive high-concurrency scenarios
Configuration Recommendations:
- Complex tasks:
budget_tokens: 20000-50000 - Medium tasks:
budget_tokens: 10000 - Testing/debugging: Enable
return_thinkingto view reasoning process
Usage Recommendation: We recommend first evaluating in small-scale tests whether Extended Thinking provides significant improvement for your tasks. If performance improvement is not obvious, you can disable it to save costs. You can quickly compare the effect differences between enabling and disabling Extended Thinking through API易 apiyi.com's A/B testing feature.
📚 Further Reading
🛠️ Open Source Resources
Complete example code for Claude Haiku 4.5 API integration has been open-sourced, covering various practical scenarios:
Latest Examples:
- Complete Claude Haiku 4.5 chatbot implementation
- Extended Thinking advanced usage examples
- Prompt Caching cost optimization practice
- Streaming output best practices
- Error handling and retry framework
- Production environment deployment configuration templates
- Performance monitoring and logging systems
📖 Learning Recommendation: For beginners in Claude Haiku 4.5 API integration, we recommend starting with simple OpenAI SDK compatible methods and gradually transitioning to official SDK advanced features. You can access API易 apiyi.com to get free developer accounts and test credits, deepening understanding through actual calls. The platform provides rich code examples, video tutorials, and practical cases.
🔗 Related Documentation
| Resource Type | Recommended Content | Access Method |
|---|---|---|
| Official Documentation | Anthropic API Reference Documentation | docs.claude.com |
| Community Resources | API易 Claude Usage Guide | help.apiyi.com |
| Video Tutorials | Claude Haiku 4.5 Quick Start | Tech Community YouTube |
| Technical Blogs | AI Development Best Practices | Major Tech Communities |
Deep Learning Recommendation: Continuously follow Claude model updates and new features. We recommend regularly accessing API易 help.apiyi.com's technical blog to learn about the latest API integration techniques, performance optimization solutions, and cost control strategies, maintaining technological leadership advantages.
🎯 Summary
This article detailed the complete workflow of Claude Haiku 4.5 API integration, from environment preparation to production deployment, covering all core knowledge points developers need to master.
Key Review: Claude Haiku 4.5 provides two mainstream integration approaches—OpenAI SDK compatible access and Anthropic official SDK, the former suitable for quick start, the latter providing complete feature support.
In practical applications, we recommend:
- Prioritize stable and reliable API aggregation platforms
- Implement comprehensive error handling and retry mechanisms
- Flexibly enable advanced features based on scenarios
- Continuously monitor performance and cost optimization
Final Recommendation: For enterprise applications and production environment deployment, we strongly recommend using professional API aggregation platforms like API易 apiyi.com. It not only provides OpenAI SDK compatible interfaces and native Claude API support but also integrates enterprise features like automatic retry, load balancing, cost analysis, and performance monitoring, significantly reducing development and operational costs. The platform supports one-click switching between multiple AI models, allowing you to choose the most suitable model for different scenarios, achieving optimal balance between performance and cost.
📝 Author Bio: Senior AI application developer, focused on large model API integration and architecture design. Regularly shares development practical experience with Claude and other AI models. More technical materials and best practice cases available at API易 apiyi.com technical community.
🔔 Technical Exchange: Welcome to discuss technical issues about Claude Haiku 4.5 API integration in the comments section, continuously sharing AI development experience and industry trends. For in-depth technical support, contact our technical team through API易 apiyi.com.