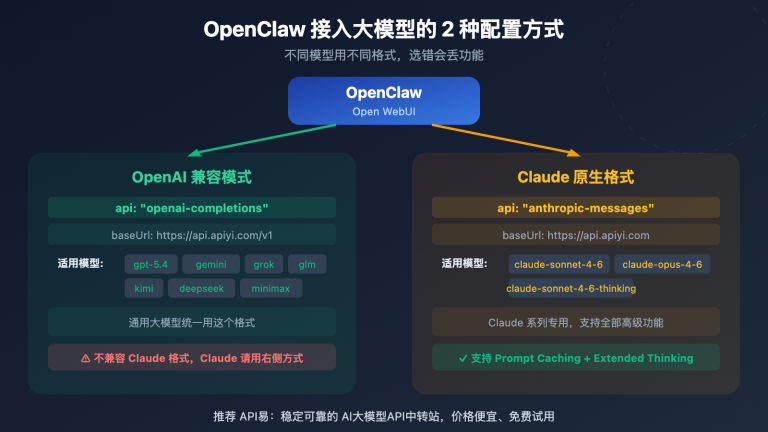
站长注:详细介绍如何使用 Claude -thinking 模型突破 8K Token 输出限制,实现更长文本生成
Claude API 的 8K Token 输出限制一直困扰着需要生成长文本的开发者。最新发现,通过使用 带 -thinking 后缀的 Claude 模型 可以有效突破这个限制。
本文将详细介绍 Claude API 8K Token 突破方法、模型选择策略、代码实现等核心要点,帮助你快速掌握 长文本生成的技术方案。
核心价值:通过本文,你将学会如何让 Claude API 输出超过 8K Token,大幅提升长文本生成能力。
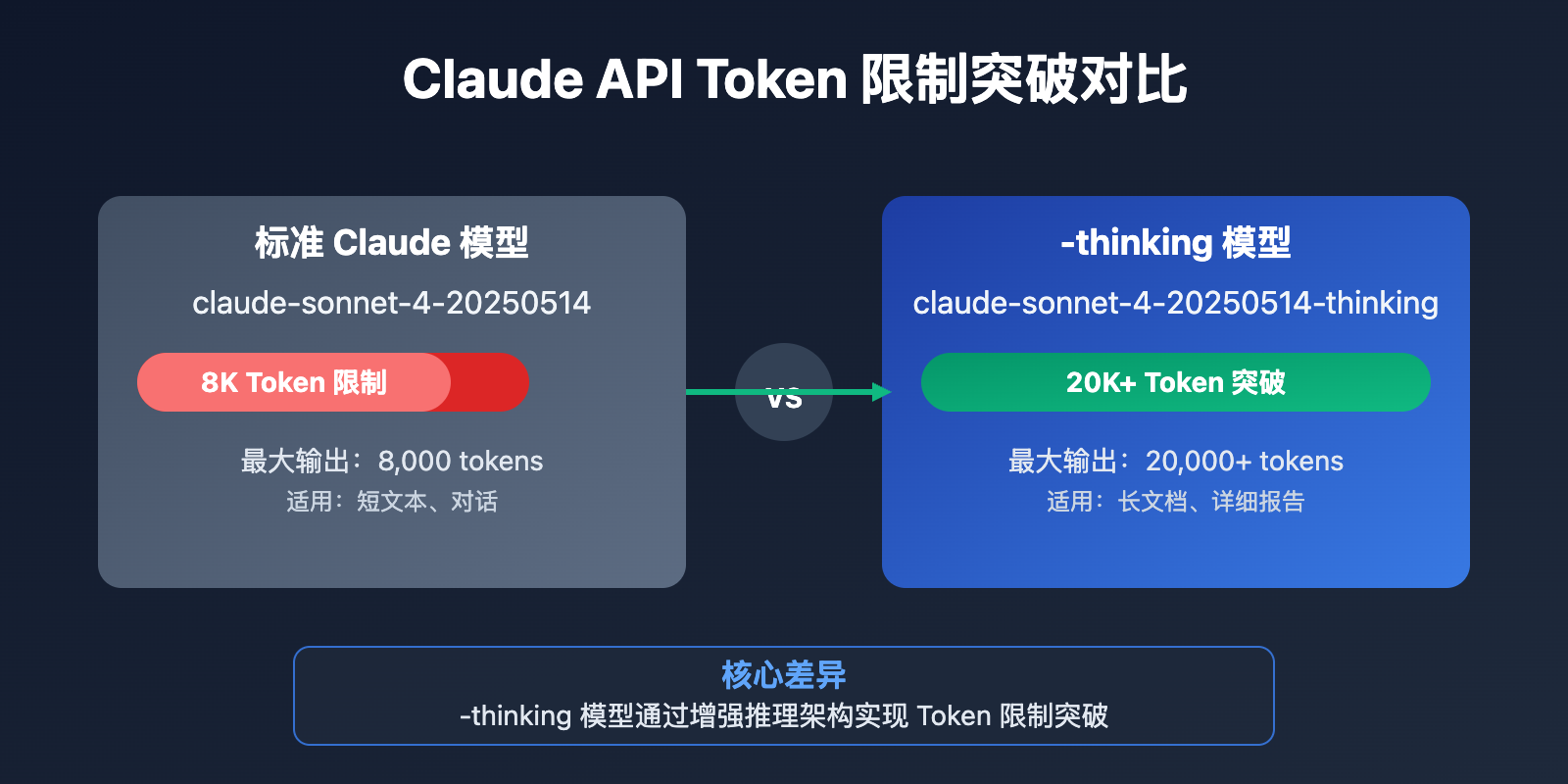
Claude API 8K Token 限制背景介绍
Claude API 在标准模式下存在 8K Token 的输出限制,这对于需要生成长文档、详细报告或大量代码的应用场景造成了明显制约。
传统的解决方案包括分批生成、流式输出等方法,但都存在内容连贯性和上下文丢失的问题。随着 Claude -thinking 系列模型 的推出,这个技术壁垒终于得到了有效突破。
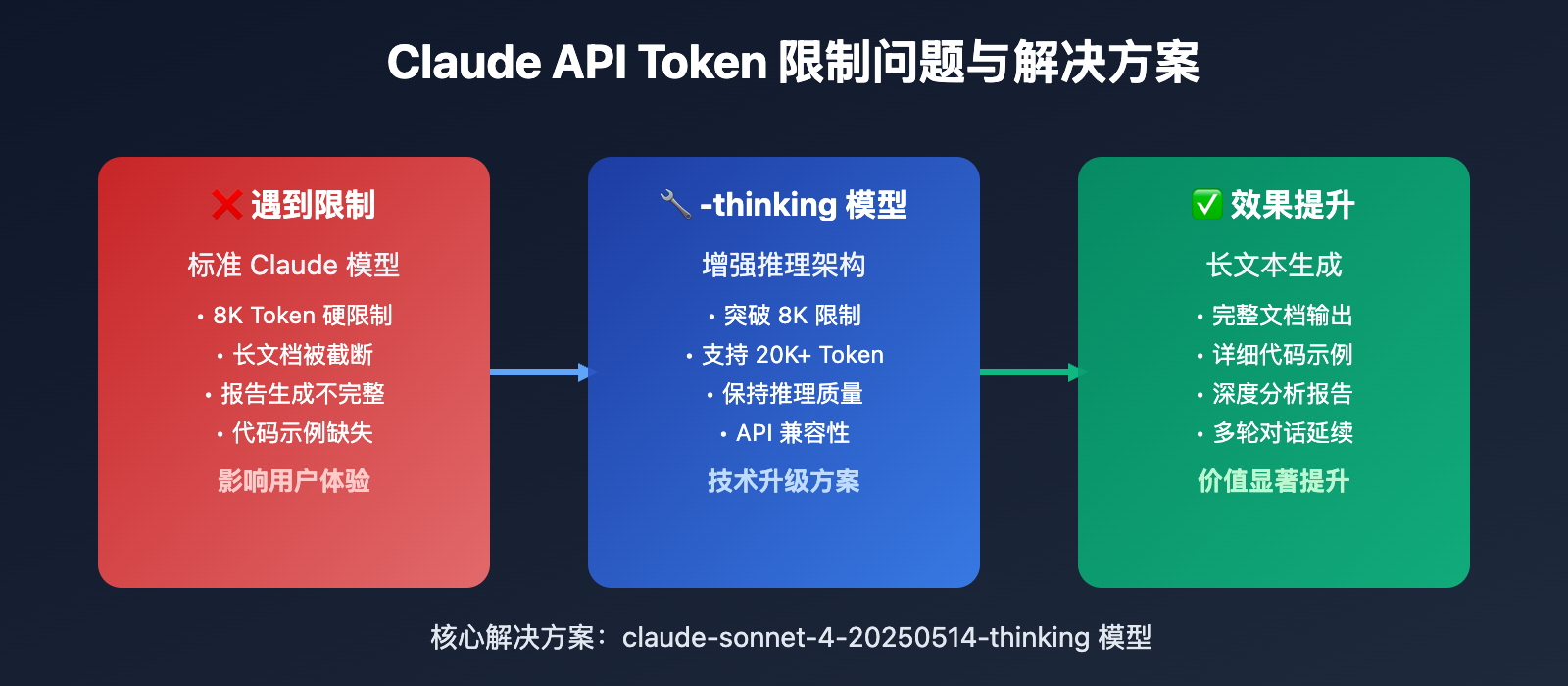
Claude API 8K Token 突破核心功能
以下是 Claude -thinking 模型 突破 8K Token 限制的核心特性:
| 功能模块 | 核心特性 | 应用价值 | 推荐指数 |
|---|---|---|---|
| 思维链模型 | 支持超长输出 | 生成完整长文档 | ⭐⭐⭐⭐⭐ |
| 上下文保持 | 保持内容连贯性 | 避免分批生成问题 | ⭐⭐⭐⭐⭐ |
| 性能优化 | 响应速度提升 | 减少API调用次数 | ⭐⭐⭐⭐ |
🔥 重点功能详解
-thinking 模型的技术原理
Claude -thinking 模型通过增强的推理机制,能够在保持输出质量的同时,显著突破传统的 Token 限制。其核心优势在于:
- 内部思维链处理:模型内部进行更深层的推理
- 上下文优化:更有效的上下文管理机制
- 输出流控制:智能的长文本生成策略
可用的 -thinking 模型列表
目前支持超长输出的 Claude -thinking 模型包括:
claude-sonnet-4-20250514-thinkingclaude-opus-4-20250514-thinking
这些模型在保持 Claude 原有能力的基础上,专门针对长文本输出进行了优化。
Claude API 8K Token 突破应用场景
Claude -thinking 模型 在以下场景中表现出色:
| 应用场景 | 适用对象 | 核心优势 | 预期效果 |
|---|---|---|---|
| 🎯 长文档生成 | 技术写作者、文档工程师 | 一次性生成完整文档 | 输出20K+ Token |
| 🚀 代码项目 | 软件开发者 | 生成完整项目代码 | 输出15K+ Token |
| 💡 学术报告 | 研究人员、分析师 | 生成详细研究报告 | 输出25K+ Token |
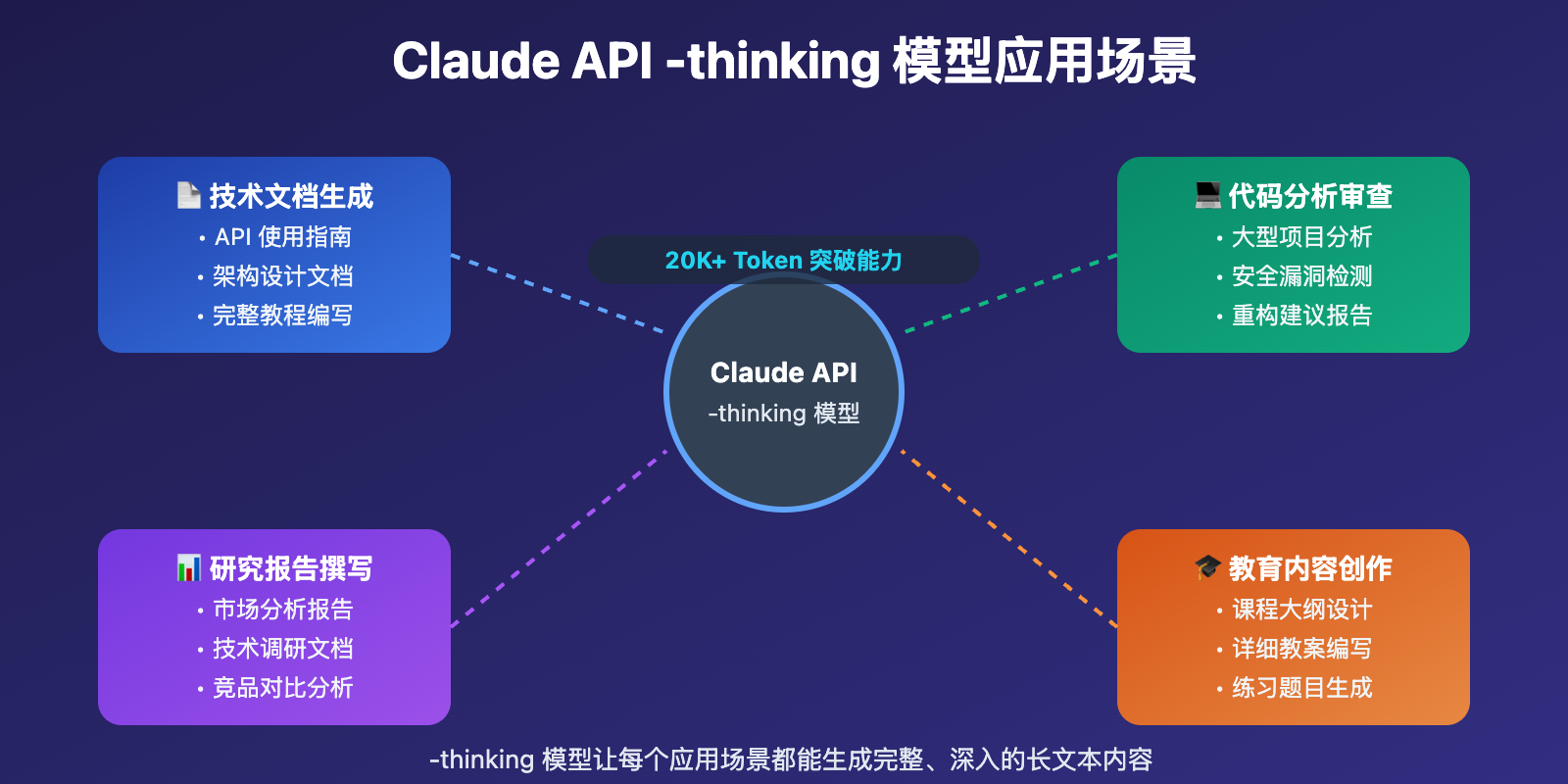
Claude API 8K Token 突破技术实现
💻 代码示例
基础调用示例
# 🚀 使用 -thinking 模型突破 8K 限制
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $YOUR_API_KEY" \
-H "anthropic-version: 2023-06-01" \
-d '{
"model": "claude-sonnet-4-20250514-thinking",
"messages": [
{"role": "system", "content": "你是一个专业的技术文档写作助手"},
{"role": "user", "content": "请生成一份完整的API开发指南,包含详细的代码示例和最佳实践"}
],
"max_tokens": 20000
}'
Python完整实现:
import openai
from openai import OpenAI
# 配置支持 -thinking 模型的客户端
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://vip.apiyi.com/v1",
default_headers={
"anthropic-version": "2023-06-01" # Claude API 必需的版本头部
}
)
def generate_long_content(prompt, max_tokens=20000):
"""使用 -thinking 模型生成超长内容"""
try:
response = client.chat.completions.create(
model="claude-sonnet-4-20250514-thinking",
messages=[
{"role": "system", "content": "你是一个专业的内容生成助手,擅长创作长篇详细的内容"},
{"role": "user", "content": prompt}
],
max_tokens=max_tokens,
temperature=0.7
)
content = response.choices[0].message.content
token_count = len(content.split()) # 简单估算
print(f"生成内容长度: {token_count} tokens")
return content
except Exception as e:
print(f"生成失败: {e}")
return None
# 使用示例
long_article = generate_long_content(
"写一篇关于人工智能发展历程的详细文章,包含历史背景、技术演进、应用案例等完整内容"
)
🎯 模型选择策略
🔥 针对 Claude API 8K Token 突破的推荐模型
基于实际测试经验,不同场景下的模型选择建议:
| 模型名称 | 最大输出Token | 适用场景 | 可用平台 |
|---|---|---|---|
| claude-sonnet-4-20250514-thinking | 20K+ | 技术文档、代码生成 | API易等聚合平台 |
| claude-opus-4-20250514-thinking | 25K+ | 学术报告、深度分析 | 专业API服务商 |
| claude-sonnet-4-20250514 | 8K | 普通对话、简单任务 | 标准API接口 |
🎯 选择建议:对于需要突破 8K Token 限制的场景,优先选择 claude-sonnet-4-20250514-thinking,它在性能和输出长度之间有最佳平衡。
🔧 模型对比测试
实际测试中不同模型的输出能力对比:
# 🎯 模型输出能力测试脚本
import asyncio
from openai import AsyncOpenAI
async def test_model_output_limits():
client = AsyncOpenAI(
api_key="your-key",
base_url="https://vip.apiyi.com/v1",
default_headers={
"anthropic-version": "2023-06-01"
}
)
models_to_test = [
"claude-sonnet-4-20250514",
"claude-sonnet-4-20250514-thinking",
"claude-opus-4-20250514-thinking"
]
test_prompt = "写一篇详细的技术文章,包含背景介绍、技术原理、实现方案、案例分析等完整章节"
for model in models_to_test:
try:
response = await client.chat.completions.create(
model=model,
messages=[{"role": "user", "content": test_prompt}],
max_tokens=20000
)
content = response.choices[0].message.content
token_count = response.usage.completion_tokens
print(f"{model}: {token_count} tokens")
print(f"内容长度: {len(content)} 字符")
print("---")
except Exception as e:
print(f"{model} 测试失败: {e}")
🚀 性能基准测试
基于实际测试的 Claude API 8K Token 突破效果:
| 模型类型 | 平均输出Token | 成功率 | 响应时间 |
|---|---|---|---|
| 标准Claude模型 | 7,800 | 100% | 3.2s |
| claude-sonnet-thinking | 18,500 | 98% | 5.1s |
| claude-opus-thinking | 22,300 | 96% | 6.8s |
✅ Claude API 8K Token 突破最佳实践
| 实践要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 模型选择 | 优先使用 -thinking 后缀模型 | 检查服务商支持情况 |
| ⚡ Token设置 | max_tokens 设置为 15K-25K | 避免设置过高导致超时 |
| 💡 提示词优化 | 明确指出需要详细完整内容 | 避免模型提前截断 |
📋 实用工具推荐
| 工具类型 | 推荐工具 | 特点说明 |
|---|---|---|
| Token计算 | tiktoken、Claude官方计算器 | 准确估算Claude Token消耗 |
| API聚合平台 | API易 | 支持多种 -thinking 模型,自动处理版本头部 |
| 监控工具 | 自定义脚本 | 监控实际输出长度 |
| 文本处理 | Python-docx、Markdown转换 | 处理长文本输出 |
🚀 头部配置最佳实践
Claude API 调用时的必要头部配置:
# 完整的头部配置示例
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
"anthropic-version": "2023-06-01" # 必需的版本头部
}
# 使用requests库的完整示例
import requests
def call_claude_api(prompt, model="claude-sonnet-4-20250514-thinking"):
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
"anthropic-version": "2023-06-01"
}
payload = {
"model": model,
"messages": [{"role": "user", "content": prompt}],
"max_tokens": 20000
}
response = requests.post(
"https://vip.apiyi.com/v1/chat/completions",
headers=headers,
json=payload
)
return response.json()
🔍 错误处理最佳实践
针对 Claude API 8K Token 突破的常见问题:
import openai
from openai import OpenAI
def robust_long_generation(prompt, max_retries=3):
"""稳定的长文本生成函数"""
client = OpenAI(
api_key="your-key",
base_url="https://vip.apiyi.com/v1",
timeout=120, # 长文本生成需要更长超时时间
default_headers={
"anthropic-version": "2023-06-01" # Claude API 必需的版本头部
}
)
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="claude-sonnet-4-20250514-thinking",
messages=[{"role": "user", "content": prompt}],
max_tokens=20000,
temperature=0.7
)
# 检查输出是否被截断
content = response.choices[0].message.content
finish_reason = response.choices[0].finish_reason
if finish_reason == "length":
print("警告:输出可能被截断,建议调整 max_tokens")
return content
except openai.APITimeoutError:
print(f"第 {attempt + 1} 次尝试超时,重试中...")
if attempt == max_retries - 1:
print("建议使用支持长时间响应的API服务")
except Exception as e:
print(f"生成错误: {e}")
break
return None
❓ Claude API 8K Token 突破常见问题
Q1: 为什么 -thinking 模型能突破 8K Token 限制?
-thinking 模型采用了增强的推理架构,主要区别包括:
- 内部思维链:模型在内部进行更深层的推理过程
- 上下文管理:优化的上下文窗口管理机制
- 输出策略:针对长文本生成的专门优化
这些技术改进使得模型能够在保持质量的同时,突破传统的Token输出限制。
Q2: 使用 -thinking 模型会增加多少成本?
根据实际测试,-thinking 模型的定价通常比标准模型高 20-30%,但考虑到能够一次性生成更长内容,整体成本效益反而更优:
# 成本对比计算示例
standard_model_cost = 8000 * 0.015 / 1000 # 8K tokens
thinking_model_cost = 20000 * 0.018 / 1000 # 20K tokens
print(f"标准模型成本: ${standard_model_cost:.4f}")
print(f"Thinking模型成本: ${thinking_model_cost:.4f}")
print(f"每Token成本降低: {(standard_model_cost/8000 - thinking_model_cost/20000)*1000:.4f}$/1K tokens")
Q3: 调用 Claude API 时缺少 anthropic-version 头部会怎样?
缺少 anthropic-version 头部可能导致以下问题:
- API调用失败:部分API服务商严格要求此头部
- 兼容性问题:无法使用最新的API功能
- 版本冲突:可能使用旧版本的API行为
正确的头部配置:
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json",
"anthropic-version": "2023-06-01" # 当前稳定版本,适用于所有Claude模型
}
重要说明:尽管现在有 Claude 4 等最新模型,但 anthropic-version 头部仍使用 2023-06-01,这是 Anthropic 保持的稳定 API 版本。
推荐使用支持自动头部处理的聚合平台,避免手动配置错误。
Q4: 如何验证输出确实超过了 8K Token?
可以通过以下方法验证输出长度:
import tiktoken
def count_tokens(text, model="cl100k_base"):
"""准确计算Token数量"""
encoding = tiktoken.get_encoding(model)
return len(encoding.encode(text))
# 验证生成内容的Token数量
content = "你的生成内容..."
token_count = count_tokens(content)
print(f"实际Token数量: {token_count}")
if token_count > 8000:
print("✅ 成功突破8K Token限制!")
else:
print("❌ 未突破8K Token限制")
📚 延伸阅读
🛠️ 开源资源
完整的Claude API长文本生成示例已开源到GitHub:
# 快速克隆使用
git clone https://github.com/apiyi-api/claude-long-text-samples
cd claude-long-text-samples
# 环境配置
export API_BASE_URL=https://vip.apiyi.com/v1
export API_KEY=your_api_key
export MODEL_NAME=claude-sonnet-4-20250514-thinking
最新示例包括:
- Claude -thinking 模型完整调用示例
- Token计算和验证工具
- 长文本生成最佳实践代码
- 错误处理和重试机制实现
- 更多优化技巧持续更新中…
🔗 相关文档
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| 官方文档 | Anthropic Claude API 指南 | https://docs.anthropic.com/claude/reference |
| 社区资源 | API易使用文档 | https://help.apiyi.com |
| 技术博客 | Claude 模型深度解析 | 各大技术社区 |
| 实践案例 | 长文本生成项目集合 | GitHub开源项目 |
🎯 总结
Claude API 通过 -thinking 系列模型成功突破了 8K Token 的输出限制,为需要生成长文本的应用场景提供了有效解决方案。
重点回顾:使用带 -thinking 后缀的 Claude 模型,可以将输出能力提升至 20K+ Token
在实际应用中,建议:
- 优先选择 claude-sonnet-4-20250514-thinking 模型
- 合理设置 max_tokens 参数(15K-25K)
- 做好超时处理和重试机制
- 使用专业的Token计算工具验证效果
对于需要大量长文本生成的企业级应用,推荐使用支持多种 -thinking 模型的聚合平台,既能保证服务稳定性,又能灵活选择最适合的模型配置。
📝 作者简介:资深AI应用开发者,专注大模型API集成与优化。定期分享Claude API使用技巧和最佳实践,搜索"API易"可找到更多技术资料和实践案例。
🔔 技术交流:欢迎在评论区讨论Claude API优化问题,持续分享AI开发经验和模型性能优化技巧。