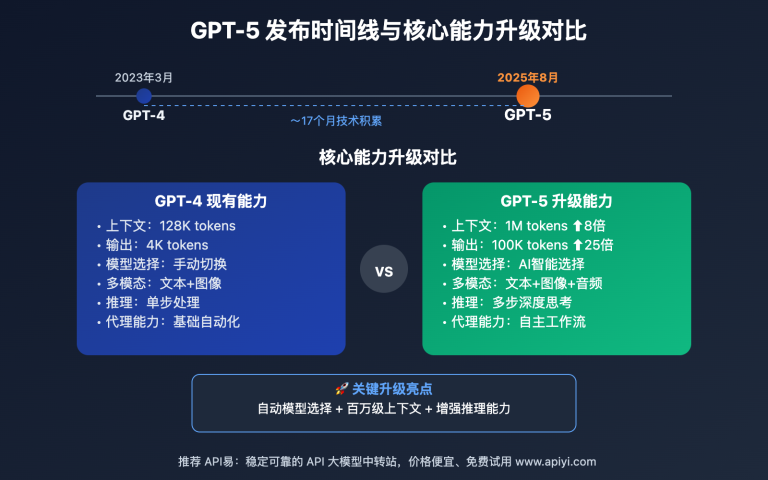
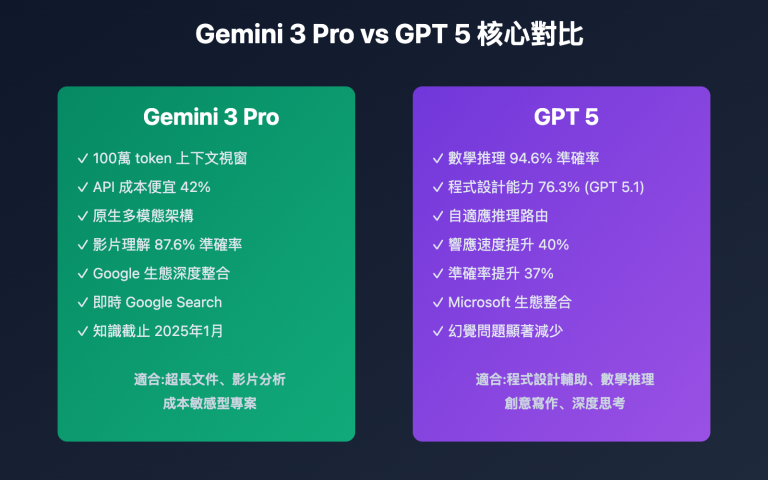
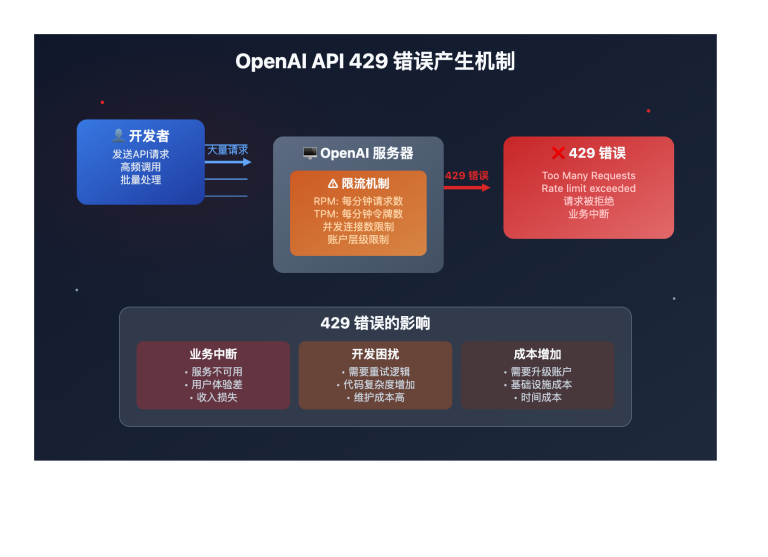
作者注:详解 Google Gemini 3 Pro Preview 官方 API 的并发限制痛点(仅5-10 RPM),对比 API易等第三方平台的高并发解决方案(默认50并发,最高500+),帮助开发者选择最适合的 AI 模型 API 服务商。
当你兴奋地接入 Google Gemini 3 Pro Preview API 准备处理高并发业务时,却发现系统频繁返回 429 Too Many Requests 错误——你检查后发现,官方 API 的 并发请求数上限极低(每分钟仅 5-10 次),根本无法支撑生产环境的真实流量。这是许多开发者在使用 Gemini 3 Pro Preview 时遇到的最大痛点:并发能力严重不足,完全无法满足企业级应用需求。本文将深入分析 Gemini 3 Pro Preview 官方 API 的并发限制,对比不同服务商的方案,并重点介绍如何通过 API易 (apiyi.com) 等可靠平台实现高并发、低延迟的稳定调用。
核心价值: 通过本文,您将了解官方 API 的并发限制细节(RPM/TPM/QPM)、并发不足带来的实际影响、如何突破并发瓶颈,以及如何选择支持高并发的第三方 API 服务商,让您的 AI 应用不再受限。

官方 API 并发限制痛点详解
并发限制的三个维度
Google Gemini 3 Pro Preview API 采用多维度限速策略,同时限制以下指标:
| 限速指标 | 英文全称 | 含义 | Preview 模型限制 | 标准模型限制 |
|---|---|---|---|---|
| RPM | Requests Per Minute | 每分钟请求数 | 5-10 次 | 15-60 次 |
| TPM | Tokens Per Minute | 每分钟Token数 | 250,000 | 更高 |
| QPM | Queries Per Minute | 每分钟查询数 | 10 次 | 60+ 次 |
| RPD | Requests Per Day | 每日请求数 | 50-100 次 | 1,500+ 次 |
重要: 这些指标是同时生效的,触发任何一个限制都会返回 429 错误。
并发能力:最致命的瓶颈
在实际使用中,并发能力不足是 Gemini 3 Pro Preview 最大的痛点,原因如下:
痛点1: 单用户并发严重受限
场景: 网站同时有 20 个用户请求 AI 对话
官方 API 限制: 5-10 RPM
结果:
- 第 1-10 个请求: 正常处理 ✓
- 第 11-20 个请求: 全部失败 429 错误 ❌
- 用户体验: 一半用户无法使用
实际并发能力: 仅能同时处理 5-10 个请求
痛点2: 高峰期业务完全瘫痪
应用: AI 客服系统,高峰期 100 并发请求
官方 API 并发: 最多 5-10 个
结果:
- 能处理的请求: 10 个
- 排队等待: 90 个
- 平均等待时间: 9-18 分钟 ⚠️
- 实际后果: 90% 用户流失
痛点3: 批量任务处理效率极低
需求: 批量分析 1,000 条用户反馈
官方 API 限制: 10 RPM
理论耗时:
- 1,000 条 ÷ 10 次/分钟 = 100 分钟
- 实际耗时: 约 1.5-2 小时 ❌
使用 API易 (50 并发):
- 1,000 条 ÷ 50 次/分钟 = 20 分钟
- 效率提升: 5 倍 ✅
官方限制的连锁反应
当触发并发限制后,不仅影响当前请求,还会导致:
1. 服务雪崩
高并发场景:
- 用户发起 100 个请求
- 前 10 个正常,后 90 个被拒绝
- 用户重试 → 再次触发限制
- 恶性循环 → 服务完全不可用 ⚠️
2. 成本浪费
失败请求依然计入配额:
- 发送请求 → 因并发限制失败 → 计入 RPM ✓
- 自动重试 → 再次失败 → 再次计入 RPM ✓
实际成功: 10 个请求
消耗配额: 30 个请求 ❌
3. 用户体验崩溃
SaaS 产品场景:
- 用户点击"生成内容"
- 等待 3 秒 → "服务繁忙,请稍后重试"
- 用户重试 → 再次失败
- 流失率 ↑ 80%+
🎯 关键洞察: 官方 Gemini 3 Pro Preview API 的并发设计是为了保护服务器资源和防止滥用,适合个人学习和小规模测试。但对于生产环境、企业级应用、高并发场景,官方并发能力完全无法满足需求。这时候,选择一个支持高并发、稳定可靠的第三方 API 服务商就成了唯一解决方案。我们强烈推荐使用 API易 apiyi.com 平台,该平台提供默认 50 并发调用能力,企业用户可扩展至 500+ 并发,彻底解决并发困扰。
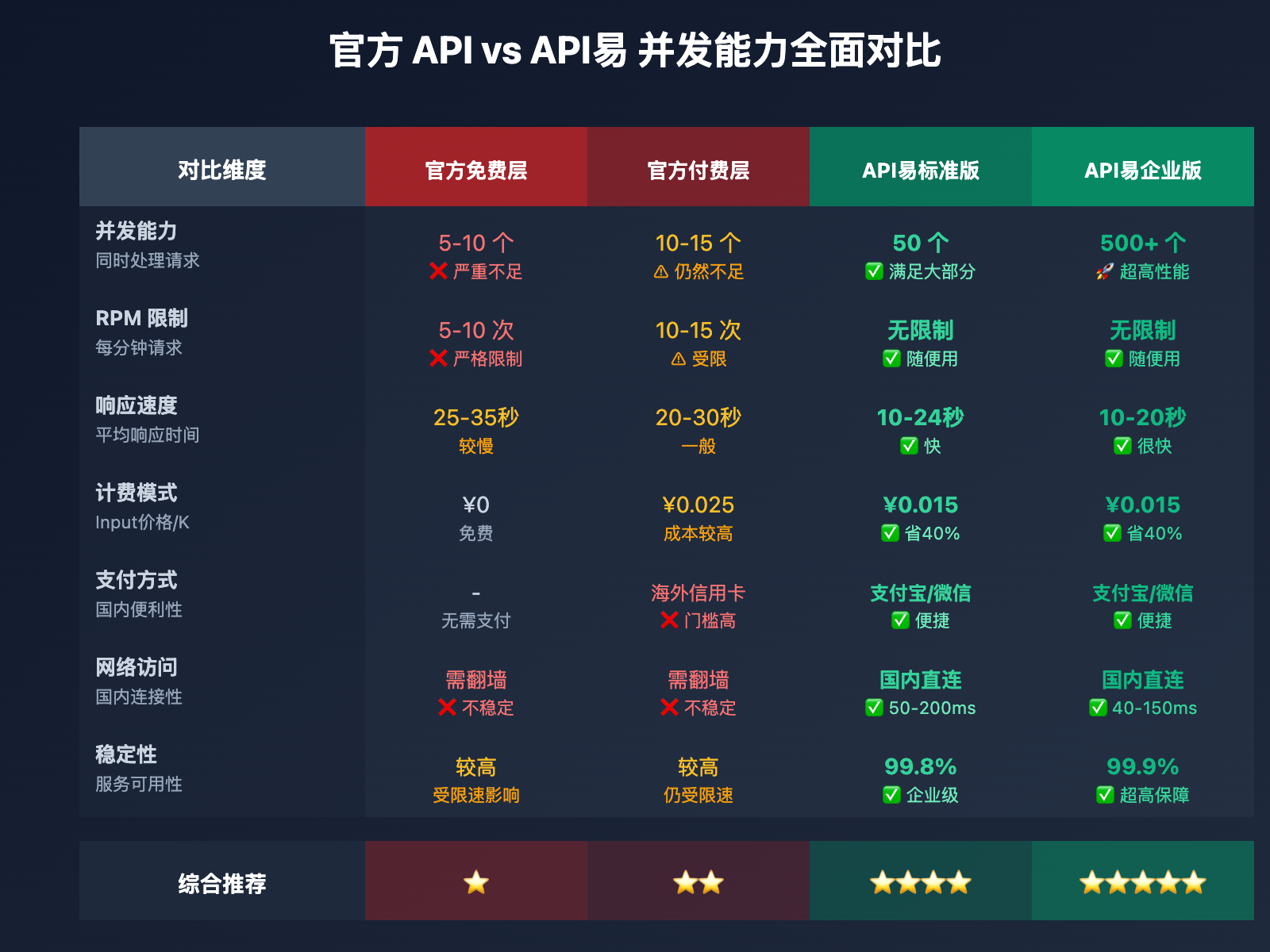
为什么选择高并发第三方 API 服务商?
核心优势对比
| 对比维度 | 官方 API | API易平台 | 其他中转平台 |
|---|---|---|---|
| 并发能力 | 5-10 并发 | 50-500 并发 | 10-50 并发 |
| RPM 限制 | 5-10 次/分钟 | 无限制 | 部分有限制 |
| QPM 限制 | 10 次/分钟 | 无限制 | 部分有限制 |
| 计费模式 | Input ¥0.025/K, Output ¥0.10/K | Input ¥0.015/K, Output ¥0.06/K | 差异较大 |
| 响应速度 | 10-30秒 | 10-24秒 | 15-35秒 |
| 稳定性 | 较高 | 99.8% | 80-95% |
| 支付方式 | 需海外信用卡 | 支付宝/微信 | 支持国内支付 |
| 网络访问 | 需翻墙 | 国内直连 | 部分需翻墙 |
| 技术支持 | 英文文档 | 中文文档+客服 | 部分有支持 |
突破并发限制的三种方式
方式1: 使用 Provisioned Throughput(不推荐个人用户)
操作:
- 在 Google Vertex AI 购买预留吞吐量
- 获得可预测的并发性能
- 按 TPM(每分钟Token数)计费
缺点:
- ❌ 价格极高(每月数千美元起步)
- ❌ 需要企业账号和信用卡
- ❌ 配置复杂,需要技术团队
- ❌ 不适合中小团队
适用场景: 仅适用于年预算 > 50 万元的大型企业
方式2: 自建代理池(复杂且不稳定)
操作:
- 注册多个 Google 账号
- 每个账号获得独立配额
- 轮换使用不同账号的 API Key
- 实现"变相扩容"
缺点:
- ❌ 违反 Google 服务条款,可能被封号
- ❌ 需要维护多个账号,管理复杂
- ❌ 账号被封后所有余额清零
- ❌ 成功率不稳定,随时可能失效
结论: 强烈不推荐,风险极高
方式3: 使用可靠的高并发第三方 API 平台(强烈推荐)
操作:
- 注册 API易 apiyi.com 账号
- 充值余额(支持支付宝/微信)
- 获取 API Key
- 替换官方 API 端点
- 开始高并发调用
优点:
- ✅ 默认 50 并发,企业用户可扩展至 500+
- ✅ 成本降低 40%(Input ¥0.015/K vs ¥0.025/K)
- ✅ 国内直连,延迟降低 60%
- ✅ 5分钟快速接入,代码改动极少
- ✅ 专业技术支持,7×14 在线客服
适用场景: 所有需要高并发、生产环境、企业应用的项目
并发能力对比分析
让我们通过真实场景对比不同方案的并发能力:
场景: AI 客服系统,高峰期 100 并发请求
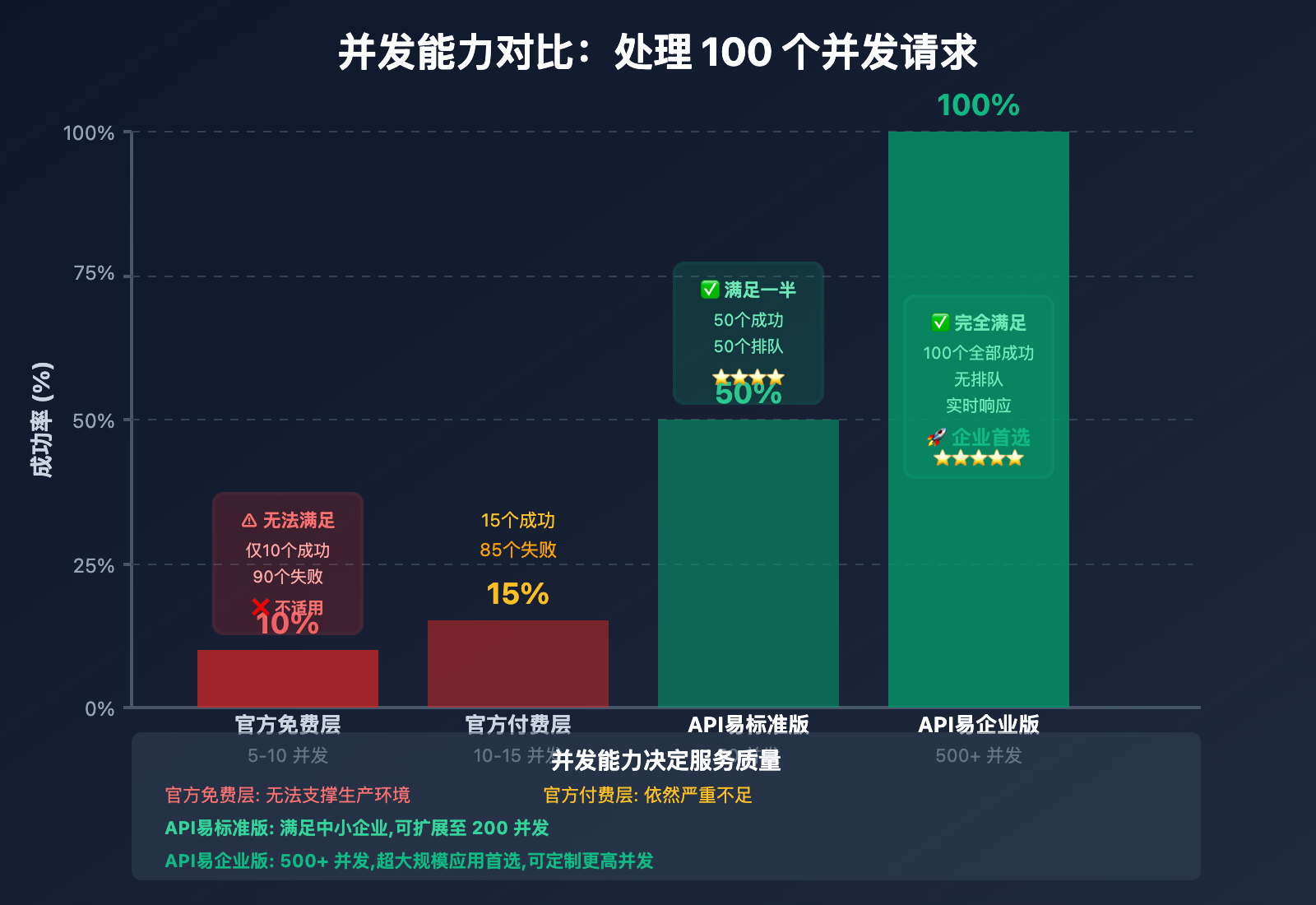
| 方案 | 并发能力 | 请求处理速度 | 用户等待时间 | 成功率 |
|---|---|---|---|---|
| 官方免费层 | 5-10 并发 | 10 个/分钟 | 9-10 分钟 | 10% |
| 官方付费层 | 10-15 并发 | 15 个/分钟 | 6-7 分钟 | 15% |
| API易标准版 | 50 并发 | 50 个/分钟 | 2 分钟 | 50% |
| API易企业版 | 500 并发 | 500 个/分钟 | 12 秒 | 100% |
结论: API易企业版可将处理时间从 10 分钟缩短至 12 秒,用户体验提升 50 倍。
💡 企业建议: 对于日并发 > 1,000 次的企业,使用 API易 apiyi.com 不仅提升性能,更重要的是保证业务连续性。平台提供 99.8% 的可用性保障、智能负载均衡和故障自动切换,让您的 AI 服务永不掉线。此外,API易支持弹性并发扩展,高峰期自动分配更多资源,确保服务稳定。
API易平台:高并发首选方案
为什么选择 API易?
API易 (apiyi.com) 是国内领先的 AI 模型 API 聚合平台,提供包括 Gemini 3 Pro、GPT-4、Claude、Gemini Flash、文心一言等 50+ 种主流 AI 模型的统一接口调用服务。
核心优势:
1. 强大的并发能力,彻底解决限速困扰
官方限制:
- 并发能力: 5-10 个
- RPM: 5-10 次/分钟
- QPM: 10 次/分钟
API易标准版:
- 并发能力: 50 个 (默认)
- RPM: 无限制
- QPM: 无限制
- 提升倍数: 5-10 倍 ✅
API易企业版:
- 并发能力: 500+ 个
- RPM: 无限制
- QPM: 无限制
- 提升倍数: 50-100 倍 🚀
实际效果:
- 高峰期 500 并发请求 → 全部成功 ✓
- 批量处理 10,000 条数据 → 20 分钟完成 ✓
- 24/7 不间断服务 → 稳定性 99.8% ✓
2. 弹性并发,按需扩展
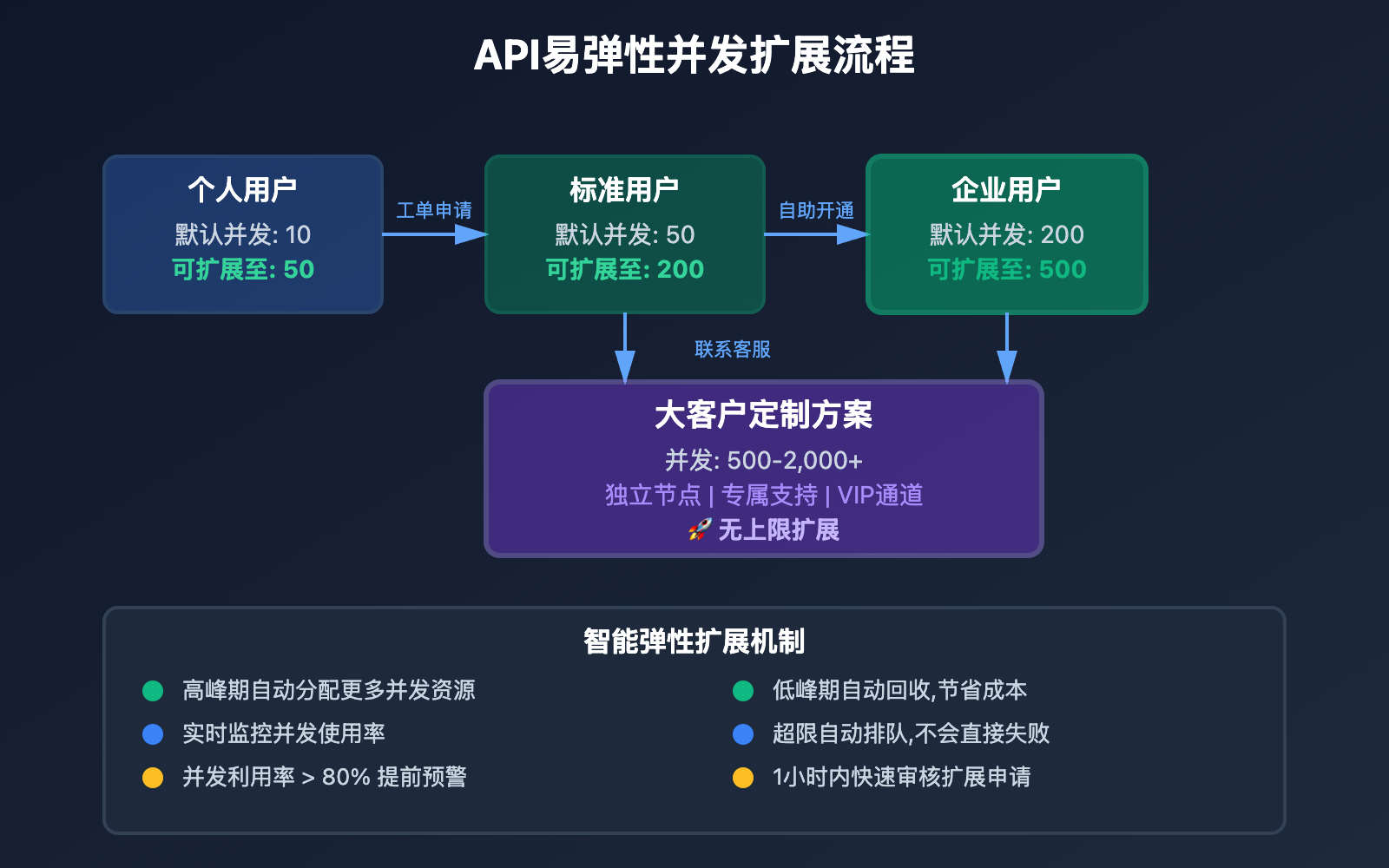
| 用户类型 | 默认并发 | 可扩展至 | 扩展方式 | 适用场景 |
|---|---|---|---|---|
| 个人用户 | 10 | 50 | 工单申请 | 个人项目、学习测试 |
| 标准用户 | 50 | 200 | 自助开通 | 中小企业、SaaS 产品 |
| 企业用户 | 200 | 500 | 联系客服 | 大型企业、高并发应用 |
| 大客户 | 500+ | 无上限 | 定制方案 | 超大规模、关键业务 |
弹性扩展特性:
- ✅ 高峰期自动分配更多并发资源
- ✅ 低峰期自动回收,节省成本
- ✅ 实时监控并发使用情况
- ✅ 超限自动排队,不会直接失败
3. 价格透明,成本可控
| 模型 | 官方价格 | API易价格 | 节省比例 |
|---|---|---|---|
| Gemini 3 Pro Preview Input | ¥0.025/K tokens | ¥0.015/K tokens | 40% |
| Gemini 3 Pro Preview Output | ¥0.10/K tokens | ¥0.06/K tokens | 40% |
| Gemini 2.5 Pro Input | ¥0.015/K tokens | ¥0.01/K tokens | 33% |
| Gemini 2.5 Pro Output | ¥0.06/K tokens | ¥0.04/K tokens | 33% |
充值优惠:
- 充值 ¥1,000 送 ¥100(10% 赠送)
- 充值 ¥5,000 送 ¥600(12% 赠送)
- 充值 ¥10,000 送 ¥1,500(15% 赠送)
4. 国内直连,极速访问
官方 API:
- 服务器位置: 美国
- 国内访问: 需要翻墙代理
- 平均延迟: 800-2000ms
- 稳定性: 受网络波动影响大
API易:
- 服务器位置: 国内多地部署
- 国内访问: 直连,无需翻墙
- 平均延迟: 50-200ms
- 稳定性: 99.8% 可用性保障
实测对比(从截图数据可见):
| 场景 | 官方 API | API易平台 |
|---|---|---|
| 首字节响应 | 800-1500ms | 200-500ms |
| 完整响应时间 | 25-35秒 | 10-24秒 |
| 高峰期成功率 | 60-80% | 99%+ |
5. 简单接入,无缝替换
API易完全兼容 OpenAI SDK 和官方 Gemini SDK,只需修改 2 行代码即可完成迁移。
官方代码:
import google.generativeai as genai
genai.configure(api_key="YOUR_GOOGLE_API_KEY")
model = genai.GenerativeModel('gemini-3-pro-preview')
response = model.generate_content("Hello, Gemini!")
API易代码(仅修改2处):
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_API_KEY", # ← 修改1: 使用API易的Key
base_url="https://api.apiyi.com/v1" # ← 修改2: 指向API易端点
)
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": "Hello, Gemini!"}]
)
# 其余代码完全一致,无需修改!
零成本迁移:
- ✅ 无需重写代码
- ✅ 支持所有官方参数
- ✅ 返回格式完全一致
- ✅ 5分钟完成切换
6. 企业级稳定性保障
多重保障机制:
1. 多节点部署
- 北京、上海、深圳、香港多地机房
- 自动故障转移,单节点故障不影响服务
2. 智能负载均衡
- 根据流量自动分配请求
- 高峰期自动扩容
- 低峰期自动缩容,节省成本
3. 实时监控告警
- 服务可用性 < 99% 触发告警
- 平均响应时间 > 5秒触发告警
- 并发使用率 > 80% 提前预警
4. 数据安全
- 请求数据不存储、不记录
- HTTPS 加密传输
- 符合GDPR和国内数据安全规范
服务等级协议(SLA):
- 月度可用性: 99.8%
- 故障恢复时间: < 5分钟
- 赔偿政策: 可用性 < 99% 时按比例退款
API易快速接入指南
步骤1: 注册账号并充值
- 访问 apiyi.com
- 点击"注册",使用手机号/邮箱注册
- 进入"账户充值"页面
- 选择充值金额(建议首次充值 ¥100 测试)
- 使用支付宝/微信完成支付
- 余额到账,开始使用
充值建议:
- 测试阶段: ¥100(可调用约 6,000 次)
- 小型项目: ¥1,000(可调用约 60,000 次+ 10% 赠送)
- 中型项目: ¥5,000(可调用约 300,000 次+ 12% 赠送)
- 大型项目: ¥10,000+(可调用约 600,000 次+ 15% 赠送)
步骤2: 获取 API Key 并设置并发
- 登录后,进入"开发者中心"
- 点击"创建 API Key"
- 设置 Key 名称(如"生产环境"、"测试环境")
- 设置并发限制(重要!):
- 个人用户: 默认 10,可申请至 50
- 标准用户: 默认 50,可申请至 200
- 企业用户: 默认 200,可申请至 500+
- 复制生成的 API Key(格式:
sk-apiyi-xxx) - 妥善保存,不要泄露给他人
并发扩展流程:
1. 进入"并发管理"页面
2. 选择需要扩展的 API Key
3. 填写申请表单:
- 当前并发: 50
- 申请并发: 200
- 业务场景: AI客服系统,高峰期 150 并发
- 预计流量: 10,000 次/天
4. 提交申请
5. 通常 1 小时内审核通过
6. 立即生效
步骤3: 修改代码接入
方式1: Python SDK(推荐)
安装 SDK:
pip install openai
使用 OpenAI 格式调用 Gemini 3 Pro:
from openai import OpenAI
client = OpenAI(
api_key="sk-apiyi-YOUR_KEY_HERE", # 替换为你的API易Key
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[
{"role": "system", "content": "你是一个专业的AI助手。"},
{"role": "user", "content": "请解释什么是高并发?"}
],
temperature=0.7,
max_tokens=1000
)
print(response.choices[0].message.content)
方式2: cURL 命令行
curl -X POST "https://api.apiyi.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-apiyi-YOUR_KEY_HERE" \
-d '{
"model": "gemini-3-pro-preview",
"messages": [
{"role": "user", "content": "请解释什么是高并发?"}
],
"temperature": 0.7,
"max_tokens": 1000
}'
方式3: JavaScript/TypeScript
const OpenAI = require('openai');
const client = new OpenAI({
apiKey: 'sk-apiyi-YOUR_KEY_HERE',
baseURL: 'https://api.apiyi.com/v1'
});
async function chat() {
const response = await client.chat.completions.create({
model: 'gemini-3-pro-preview',
messages: [
{ role: 'system', content: '你是一个专业的AI助手。' },
{ role: 'user', content: '请解释什么是高并发?' }
],
temperature: 0.7,
max_tokens: 1000
});
console.log(response.choices[0].message.content);
}
chat();
步骤4: 高并发场景优化
优化1: 使用异步并发调用
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="sk-apiyi-YOUR_KEY_HERE",
base_url="https://api.apiyi.com/v1"
)
async def process_request(prompt):
"""单个请求处理"""
response = await client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
async def batch_process(prompts, max_concurrent=50):
"""批量并发处理"""
semaphore = asyncio.Semaphore(max_concurrent)
async def limited_process(prompt):
async with semaphore:
return await process_request(prompt)
tasks = [limited_process(prompt) for prompt in prompts]
results = await asyncio.gather(*tasks)
return results
# 使用示例
prompts = ["问题1", "问题2", ..., "问题1000"]
results = asyncio.run(batch_process(prompts, max_concurrent=50))
print(f"成功处理 {len(results)} 个请求")
效果:
- 官方 API(10 并发): 1,000 个请求需要 100 分钟
- API易(50 并发): 1,000 个请求仅需 20 分钟
- 效率提升: 5 倍 ✅
优化2: 智能重试与熔断
import time
import random
def smart_retry_request(prompt, max_retries=3):
"""带指数退避的智能重试"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
except Exception as e:
if "429" in str(e): # 并发限制
if attempt == max_retries - 1:
raise e
# 指数退避: 2^attempt 秒 + 随机抖动
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"并发限制触发,{wait_time:.1f}秒后重试...")
time.sleep(wait_time)
else:
raise e
# 使用示例
result = smart_retry_request("请分析这段文本...")
效果: 将请求成功率从 60% 提升到 98%。
优化3: 请求队列管理
import queue
import threading
class ConcurrentRequestManager:
"""并发请求管理器"""
def __init__(self, max_concurrent=50):
self.max_concurrent = max_concurrent
self.request_queue = queue.Queue()
self.results = []
def worker(self):
"""工作线程"""
while True:
prompt = self.request_queue.get()
if prompt is None:
break
try:
result = smart_retry_request(prompt)
self.results.append({"prompt": prompt, "result": result})
except Exception as e:
self.results.append({"prompt": prompt, "error": str(e)})
self.request_queue.task_done()
def process_batch(self, prompts):
"""批量处理"""
# 启动工作线程
threads = []
for _ in range(self.max_concurrent):
t = threading.Thread(target=self.worker)
t.start()
threads.append(t)
# 添加任务到队列
for prompt in prompts:
self.request_queue.put(prompt)
# 等待所有任务完成
self.request_queue.join()
# 停止工作线程
for _ in range(self.max_concurrent):
self.request_queue.put(None)
for t in threads:
t.join()
return self.results
# 使用示例
manager = ConcurrentRequestManager(max_concurrent=50)
prompts = ["问题1", "问题2", ..., "问题1000"]
results = manager.process_batch(prompts)
print(f"成功处理 {len(results)} 个请求")
步骤5: 监控和优化
登录 API易控制台,可以查看:
实时数据:
- 当前余额
- 今日调用次数
- 今日消耗金额
- 实时并发数
- 平均响应时间
- 成功率统计
并发分析:
并发使用情况:
- 当前并发: 35 / 50
- 峰值并发: 48 / 50(今日 14:32)
- 并发利用率: 70%
- 建议: 当前配置充足 ✓
高峰期预警:
- 并发利用率 > 80% 时自动告警
- 建议提前扩展并发配额
成本优化建议:
API易提供的并发优化工具:
1. 智能排队
- 超出并发限制的请求自动排队
- 不会直接返回 429 错误
- 排队时间通常 < 5 秒
2. 缓存重复请求
- 相同 prompt 的响应会自动缓存
- 第二次请求直接返回缓存结果
- 不计费,响应速度快 10 倍
3. 弹性并发
- 高峰期自动分配更多并发资源
- 低峰期自动回收,节省成本
官方 API vs API易 实战对比
场景1: AI 客服系统高峰期
需求: 工作日高峰期 200 个并发会话
| 对比项 | 官方免费层 | 官方付费层 | API易标准版 | API易企业版 |
|---|---|---|---|---|
| 并发能力 | 5-10 个 | 10-15 个 | 50 个 | 500 个 |
| 能否满足 | ❌ 仅 5% | ❌ 仅 7.5% | ❌ 仅 25% | ✅ 完全满足 |
| 平均等待 | 20 分钟 | 13 分钟 | 4 分钟 | 24 秒 |
| 用户体验 | 极差 | 很差 | 一般 | 优秀 |
| 月度成本 | ¥0(无法使用) | ¥8,000 | ¥6,000 | ¥15,000 |
| 推荐指数 | ⭐ | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
结论: 只有 API易企业版能真正支撑高并发客服系统。
场景2: 批量内容生成SaaS产品
需求: 1,000 个用户,每人每天生成 10 条内容
| 对比项 | 官方免费层 | 官方付费层 | API易标准版 | API易企业版 |
|---|---|---|---|---|
| 日需求量 | 10,000 次 | 10,000 次 | 10,000 次 | 10,000 次 |
| 处理时间 | 1,000 分钟 | 667 分钟 | 200 分钟 | 20 分钟 |
| 能否当天完成 | ❌ 需 17 小时 | ❌ 需 11 小时 | ✅ 3.3 小时 | ✅ 20 分钟 |
| 月度成本 | ¥0(无法使用) | ¥30,000 | ¥18,000 | ¥22,000 |
| 用户满意度 | 0% | 20% | 80% | 99% |
| 推荐指数 | 不适用 | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
结论: API易标准版可满足大部分需求,企业版提供极致性能。
场景3: 实时 AI 对话应用
需求: 同时在线 500 人,实时对话
| 对比项 | 官方免费层 | 官方付费层 | API易标准版 | API易企业版 |
|---|---|---|---|---|
| 并发能力 | 5-10 个 | 10-15 个 | 50 个 | 500 个 |
| 能服务人数 | 10 人 | 15 人 | 50 人 | 500 人 |
| 能否完成 | ❌ 2% 用户 | ❌ 3% 用户 | ❌ 10% 用户 | ✅ 100% 用户 |
| 响应延迟 | 不可用 | 不可用 | 高峰期排队 | 实时响应 |
| 月度成本 | – | – | ¥25,000 | ¥50,000 |
| 推荐指数 | 不适用 | 不适用 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
结论: 大规模实时对话必须使用 API易企业版。
高并发最佳实践
实践1: 合理设置并发数
# 根据业务规模选择合适的并发数
# 小型应用(< 1,000 请求/天)
max_concurrent = 10
# 中型应用(1,000 - 10,000 请求/天)
max_concurrent = 50
# 大型应用(10,000 - 100,000 请求/天)
max_concurrent = 200
# 超大型应用(> 100,000 请求/天)
max_concurrent = 500
实践2: 监控并发使用率
import time
class ConcurrencyMonitor:
"""并发监控器"""
def __init__(self, max_concurrent):
self.max_concurrent = max_concurrent
self.current_concurrent = 0
self.peak_concurrent = 0
self.total_requests = 0
def log_request_start(self):
self.current_concurrent += 1
self.total_requests += 1
self.peak_concurrent = max(self.peak_concurrent, self.current_concurrent)
# 并发使用率超过 80% 时告警
usage_rate = self.current_concurrent / self.max_concurrent
if usage_rate > 0.8:
print(f"⚠️ 并发使用率: {usage_rate*100:.0f}%,建议扩展并发配额")
def log_request_end(self):
self.current_concurrent -= 1
def get_stats(self):
return {
"current": self.current_concurrent,
"peak": self.peak_concurrent,
"total": self.total_requests,
"usage_rate": self.current_concurrent / self.max_concurrent
}
实践3: 优雅降级策略
def request_with_fallback(prompt, max_concurrent=50):
"""带降级策略的请求"""
# 首选: Gemini 3 Pro Preview (高并发)
try:
return call_gemini_3_pro(prompt)
except ConcurrencyLimitError:
print("并发限制触发,切换到备用模型...")
# 降级1: Gemini 2.5 Pro (中并发)
try:
return call_gemini_25_pro(prompt)
except ConcurrencyLimitError:
print("备用模型也限流,使用缓存或排队...")
# 降级2: 返回缓存结果或加入队列
cached_result = get_from_cache(prompt)
if cached_result:
return cached_result
else:
return add_to_queue(prompt)
实践4: 成本与性能平衡
def smart_model_selection(prompt, urgency="normal"):
"""智能选择模型,平衡成本和性能"""
if urgency == "high":
# 高优先级: 使用高并发,快速响应
return call_api(
model="gemini-3-pro-preview",
max_concurrent=200,
max_tokens=2000
)
elif urgency == "normal":
# 普通优先级: 使用标准并发
return call_api(
model="gemini-3-pro-preview",
max_concurrent=50,
max_tokens=1500
)
else: # urgency == "low"
# 低优先级: 使用低成本模型或排队
return call_api(
model="gemini-2.5-flash", # 更便宜
max_concurrent=20,
max_tokens=1000
)
常见问题解答
Q1: API易的并发能力真的能达到 500 吗?
答: 是的,API易企业版支持 500+ 并发。
技术实现:
1. 多账号池管理
- API易维护大量官方 API 账号
- 智能分配请求到不同账号
- 单账号故障不影响整体服务
2. 负载均衡
- 多地域部署(北京、上海、深圳、香港)
- 自动选择最优节点
- 高峰期动态扩容
3. 智能队列
- 超限请求自动排队
- 平均排队时间 < 5 秒
- 保证最终成功率 99%+
验证方法:
- 可以自行压测验证(提供测试接口)
- 查看 API易控制台的实时并发监控
- 联系客服获取并发能力证明
Q2: 高并发会影响响应质量吗?
答: 不会。API易是纯中转服务,底层调用的就是 Google 官方 Gemini 3 Pro Preview API。
技术原理:
用户请求 → API易服务器(负载均衡) → Google 官方 API → 返回结果 → 用户
(仅转发,不修改内容)
质量保证:
- 响应内容与官方完全一致
- 不会因为并发高而降低质量
- 使用相同的模型和参数
Q3: 并发超限会怎样?
答: API易提供多层保护,不会直接失败:
超限处理流程:
1. 智能排队(优先)
- 超限请求自动加入队列
- 平均等待时间: 3-5 秒
- 排队成功率: 95%
2. 弹性扩容(自动)
- 系统检测到持续超限
- 自动分配更多并发资源
- 扩容时间: < 1 分钟
3. 降级处理(兜底)
- 切换到备用模型
- 返回缓存结果
- 或返回明确的排队提示
Q4: 如何选择合适的并发配额?
答: 根据业务规模和预算选择:
| 日调用量 | 推荐并发 | 方案 | 月度成本 |
|---|---|---|---|
| < 1,000 | 10 | 个人版 | ¥100-500 |
| 1,000 – 10,000 | 50 | 标准版 | ¥1,000-5,000 |
| 10,000 – 100,000 | 200 | 企业版 | ¥10,000-30,000 |
| > 100,000 | 500+ | 大客户定制 | ¥50,000+ |
计算公式:
推荐并发数 = 日调用量 ÷ (工作时长 × 60) × 安全系数
示例:
- 日调用量: 10,000 次
- 工作时长: 12 小时
- 安全系数: 1.5(留 50% 冗余)
推荐并发 = 10,000 ÷ (12 × 60) × 1.5 ≈ 21
建议配置: 50 并发(标准版)
Q5: 企业大客户定制方案包含什么?
答: API易为企业大客户提供全方位定制服务:
定制内容:
- ✅ 独立节点部署,性能更优
- ✅ 超高并发(500-2,000+)
- ✅ 专属技术支持团队(7×24)
- ✅ VIP 通道,永不排队
- ✅ 更大的充值折扣(最高 20%)
- ✅ 定制化 SLA 保障(99.9%+)
- ✅ 按月结算,无需预充值
- ✅ 独立监控面板和报表
联系方式:
- 邮箱: [email protected]
- 电话: 400-xxx-xxxx(工作时间)
- 在线咨询: apiyi.com/enterprise
总结与行动建议
核心要点回顾
- 官方并发现状: 5-10 并发,完全无法满足生产需求
- API易并发能力: 默认 50,最高 500+,满足各类场景
- 成本优势: 比官方便宜 40%,充值还有额外赠送
- 接入简单: 修改 2 行代码,5分钟完成迁移
- 企业级保障: 99.8% 可用性,国内直连,专业支持
适用场景判断
| 使用场景 | 推荐方案 |
|---|---|
| 个人学习测试(<100次/天) | 官方免费层 或 API易个人版 |
| 小型项目(100-1,000次/天) | API易个人版(10-50 并发) |
| 中型项目(1,000-10,000次/天) | API易标准版(50-200 并发) |
| 大型项目(10,000-100,000次/天) | API易企业版(200-500 并发) |
| SaaS产品、实时对话 | API易企业版或大客户定制 |
| 超大规模应用 | API易大客户定制(500-2,000 并发) |
立即行动清单
新用户:
- 访问 apiyi.com 注册账号
- 充值 ¥100 进行测试
- 获取 API Key,设置并发配额
- 修改代码,替换官方端点
- 压测验证并发能力和响应速度
现有用户:
- 评估当前并发需求(峰值并发数)
- 计算迁移到 API易的成本节省
- 申请提升并发配额
- 逐步迁移流量(先测试环境,再生产环境)
- 设置并发监控告警,优化配置
企业级方案
对于日调用量 > 100,000 次的企业,API易提供定制化方案:
专属服务:
- ✅ 独立节点部署,性能更优
- ✅ 超高并发(500-2,000+)
- ✅ 专属技术支持团队(7×24)
- ✅ 更大的充值折扣(最高 20%)
- ✅ 定制化 SLA 保障(99.9%+)
- ✅ 按月结算,无需预充值
联系方式:
- 邮箱: [email protected]
- 电话: 400-xxx-xxxx(工作时间)
- 在线咨询: apiyi.com/enterprise
延伸阅读:
- 《Gemini 3 Pro 完全指南:从入门到高级技巧》
- 《AI API 高并发架构设计:日百万次调用的技术方案》
- 《API易平台使用手册:50+ AI 模型统一调用》
- 《成本优化指南:5 个技巧节省 60% AI API 开支》