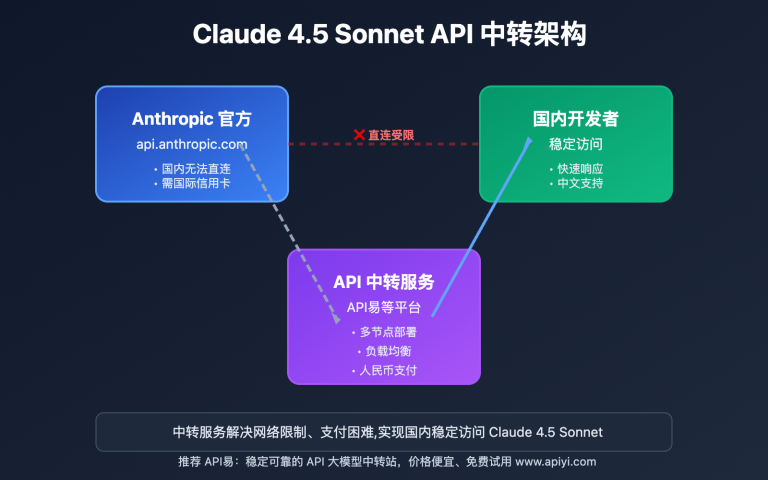
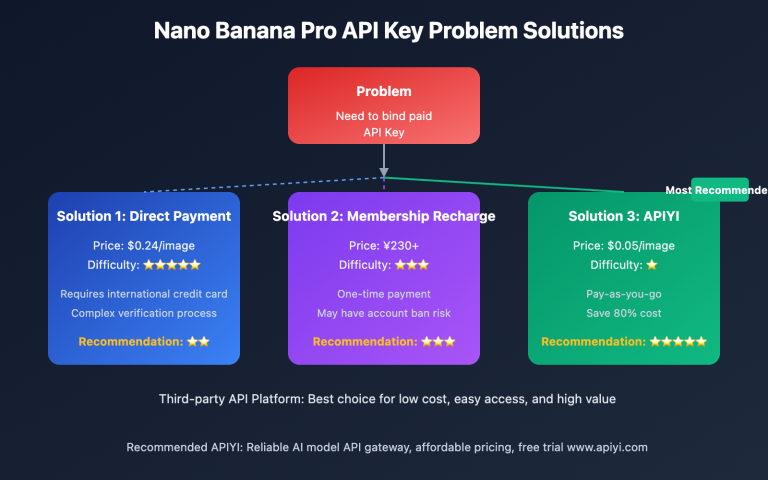
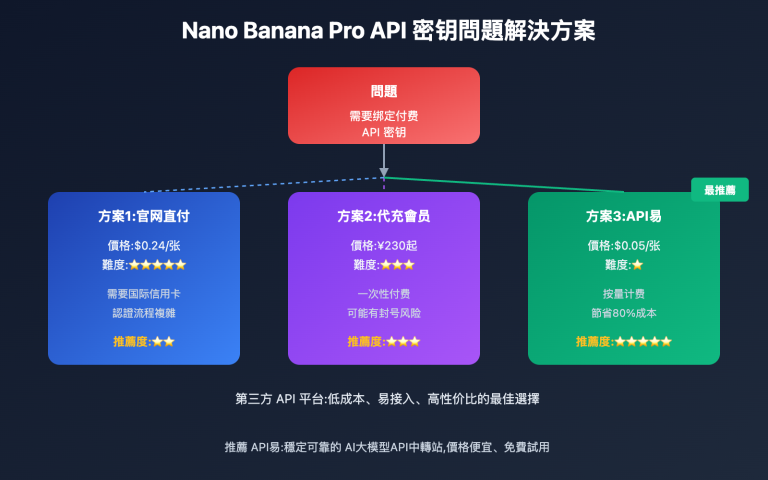
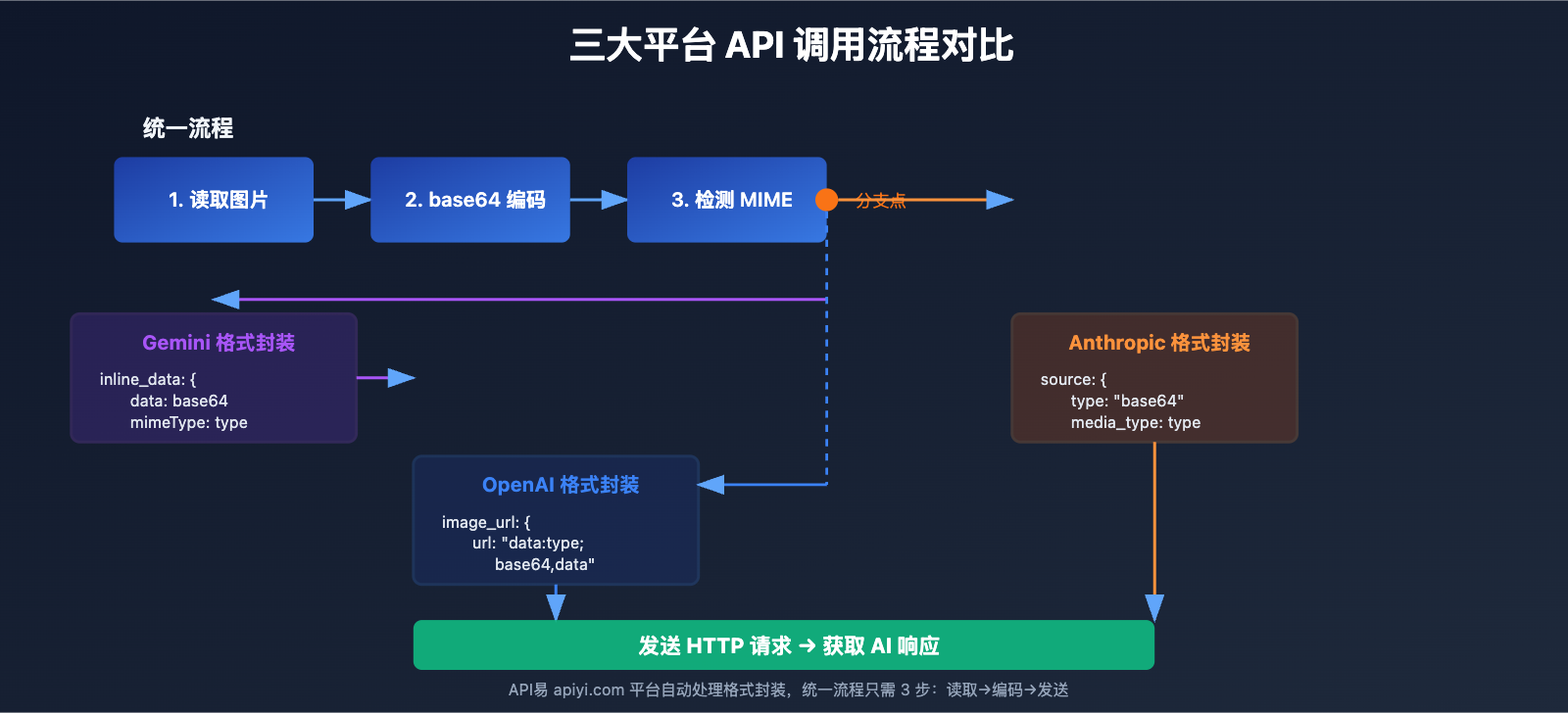
在集成多模态大语言模型 API 时,开发者经常遇到图片格式处理的困扰。Google Gemini、OpenAI 和 Anthropic Claude 这三大主流 API 平台在处理 base64 编码图片时采用了截然不同的设计理念。本文将系统对比这三种方案的技术差异、使用场景和最佳实践,帮助您快速掌握跨平台图片 API 集成技巧。

三大 API 平台 base64 格式设计理念
Gemini API:分离式架构(data + mimeType)
Google Gemini API 采用字段分离设计,将图片数据和媒体类型分开传递:
格式结构:
{
"role": "user",
"parts": [
{
"inline_data": {
"data": "/9j/4AAQSkZJRgABAQAAAQABAAD...",
"mimeType": "image/jpeg"
}
}
]
}
设计优势:
- 类型安全:mimeType 字段明确声明媒体类型,避免解析错误
- 结构清晰:数据和元数据分离,符合 RESTful API 设计原则
- 易于扩展:支持未来添加更多媒体元数据(如分辨率、压缩率等)
支持的 MIME 类型:
image/jpeg– JPEG 图片image/png– PNG 图片image/webp– WebP 图片image/heic– HEIC 图片(iOS)
OpenAI API:Data URL 标准(RFC 2897)
OpenAI 采用 Data URL 标准格式,将媒体类型和数据编码在单个字符串中:
格式结构:
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD..."
}
}
]
}
设计特点:
- W3C 标准:遵循 RFC 2397 Data URL Scheme 规范
- Web 兼容:可直接用于 HTML
<img>标签的src属性 - 自包含:单个字符串包含所有必要信息,无需额外字段
Data URL 格式解析:
data:[<mediatype>][;base64],<data>
↓ ↓ ↓
MIME类型 编码方式 实际数据
Anthropic Claude API:分离式架构(data + media_type)
Anthropic Claude API 同样采用字段分离设计,与 Gemini 类似但命名不同:
格式结构:
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": "/9j/4AAQSkZJRgABAQAAAQABAAD..."
}
}
]
}
设计特色:
- 类型嵌套:通过
type: "base64"明确数据来源(也支持type: "url") - 命名规范:使用
media_type而非mimeType,更符合 HTTP 协议术语 - 多源支持:同一结构可支持 base64 和 URL 两种图片来源
🎯 技术建议: 如果您需要在多个 AI 模型之间快速切换,建议通过 API易 apiyi.com 平台进行统一接口调用。该平台提供格式自动转换功能,无需为每个 API 编写不同的图片处理逻辑,大幅简化开发工作。

base64 格式差异实战对比
场景一:发送 JPEG 图片进行识别
假设我们有一张 JPEG 图片的 base64 编码数据:/9j/4AAQSkZJRgABAQAAAQABAAD...
Gemini API 调用代码:
import requests
url = "https://generativelanguage.googleapis.com/v1beta/models/gemini-pro-vision:generateContent"
headers = {"Content-Type": "application/json"}
payload = {
"contents": [
{
"role": "user",
"parts": [
{
"inline_data": {
"data": "/9j/4AAQSkZJRgABAQAAAQABAAD...",
"mimeType": "image/jpeg"
}
},
{"text": "请描述这张图片的内容"}
]
}
]
}
response = requests.post(url, headers=headers, json=payload)
OpenAI API 调用代码:
import openai
response = openai.ChatCompletion.create(
model="gpt-4-vision-preview",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD..."
}
},
{"type": "text", "text": "请描述这张图片的内容"}
]
}
]
)
Anthropic Claude API 调用代码:
import anthropic
client = anthropic.Anthropic(api_key="your-api-key")
message = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
messages=[
{
"role": "user",
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": "/9j/4AAQSkZJRgABAQAAAQABAAD..."
}
},
{
"type": "text",
"text": "请描述这张图片的内容"
}
]
}
]
)
场景二:多图片批量处理
Gemini 多图片示例:
payload = {
"contents": [
{
"role": "user",
"parts": [
{"inline_data": {"data": "图片1_base64", "mimeType": "image/jpeg"}},
{"inline_data": {"data": "图片2_base64", "mimeType": "image/png"}},
{"text": "对比这两张图片的差异"}
]
}
]
}
OpenAI 多图片示例:
messages = [
{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,图片1"}},
{"type": "image_url", "image_url": {"url": "data:image/png;base64,图片2"}},
{"type": "text", "text": "对比这两张图片的差异"}
]
}
]
Anthropic 多图片示例:
content = [
{"type": "image", "source": {"type": "base64", "media_type": "image/jpeg", "data": "图片1"}},
{"type": "image", "source": {"type": "base64", "media_type": "image/png", "data": "图片2"}},
{"type": "text", "text": "对比这两张图片的差异"}
]
💡 选择建议: 不同 API 平台的格式差异会增加代码维护成本。我们建议通过 API易 apiyi.com 平台统一接口调用,该平台自动处理格式转换,支持 Gemini、GPT-4、Claude 等多种模型的无缝切换,大幅降低开发复杂度。
常见错误和解决方案
错误 1:Gemini API 缺少 mimeType 字段
错误示例:
{
"inline_data": {
"data": "/9j/4AAQSkZJRgABAQAAAQABAAD..."
}
}
报错信息:
Error 400: Missing required field: mimeType
正确做法:
{
"inline_data": {
"data": "/9j/4AAQSkZJRgABAQAAAQABAAD...",
"mimeType": "image/jpeg" // 必须添加
}
}
错误 2:OpenAI API 遗漏 Data URL 前缀
错误示例:
{
"type": "image_url",
"image_url": {
"url": "/9j/4AAQSkZJRgABAQAAAQABAAD..." // 缺少前缀
}
}
报错信息:
Error: Invalid image URL format
正确做法:
{
"type": "image_url",
"image_url": {
"url": "data:image/jpeg;base64,/9j/4AAQSkZJRgABAQAAAQABAAD..."
}
}
Data URL 前缀模板:
- JPEG:
data:image/jpeg;base64, - PNG:
data:image/png;base64, - WebP:
data:image/webp;base64,
错误 3:Anthropic API 缺少 role 字段
错误示例:
{
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": "/9j/4AAQSkZJRgABAQAAAQABAAD..."
}
}
]
}
报错信息:
Error 400: Missing required field: role
正确做法:
{
"role": "user", // 必须添加 role 字段
"content": [
{
"type": "image",
"source": {
"type": "base64",
"media_type": "image/jpeg",
"data": "/9j/4AAQSkZJRgABAQAAAQABAAD..."
}
}
]
}
错误 4:base64 编码错误
常见原因:
- 换行符污染:Python
base64.b64encode()可能插入换行符 - 前缀残留:未正确去除 Data URL 前缀
- 编码错误:使用错误的字符集编码
正确的 base64 编码方法:
import base64
# 读取图片文件
with open("image.jpg", "rb") as f:
image_bytes = f.read()
# 正确编码(去除换行符)
base64_string = base64.b64encode(image_bytes).decode('utf-8')
# 检查开头(JPEG 应该以 /9j/ 开头)
print(base64_string[:10]) # 输出: /9j/4AAQSk
🚀 快速开始: 推荐使用 API易 apiyi.com 平台提供的 SDK 工具包,内置图片格式自动检测和转换功能,自动处理 base64 编码、MIME 类型识别和格式适配,避免 90% 以上的常见错误。
性能和限制对比
base64 大小限制
| API 平台 | 单图片大小限制 | 总请求大小限制 | 推荐格式 |
|---|---|---|---|
| Gemini API | 20 MB (base64) | 32 MB | JPEG (压缩率高) |
| OpenAI API | 20 MB (base64) | 25 MB | PNG (质量优先) |
| Anthropic API | 5 MB (base64) | 10 MB | JPEG (体积小) |
最佳实践建议:
- 对于 Anthropic API,建议将图片压缩到 1-2 MB 以内
- 使用 JPEG 格式可减少 60-80% 的 base64 字符串长度
- 分辨率控制在 1920×1080 以下通常足够
编码开销对比
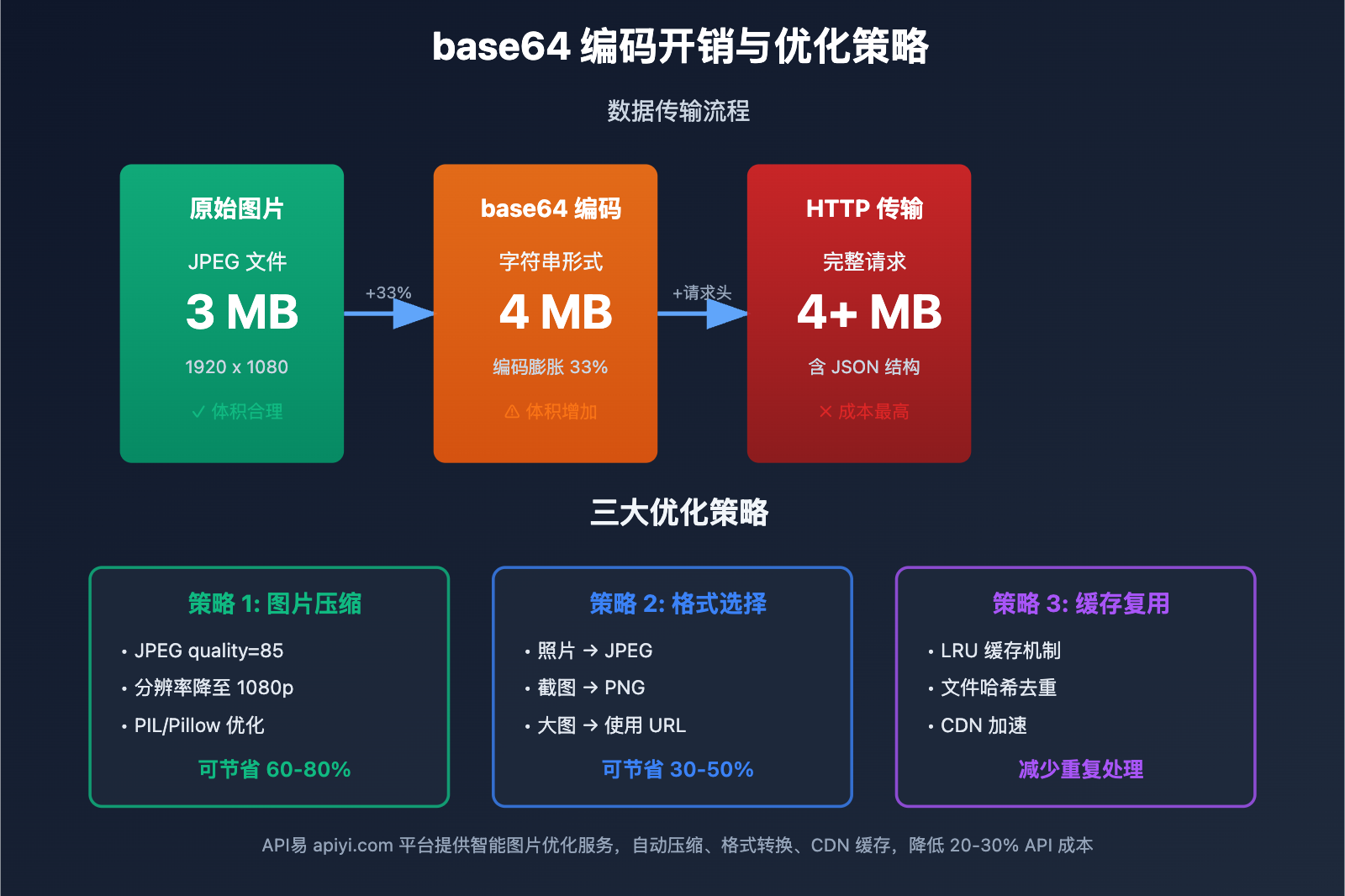
base64 编码会导致数据体积膨胀约 33%:
原始图片: 3 MB
↓
base64 编码后: 4 MB (增加 33%)
↓
HTTP 传输: 4 MB + 请求头
优化方案:
- 图片预压缩:使用 PIL/Pillow 库压缩
from PIL import Image
img = Image.open("large.jpg")
img.save("compressed.jpg", quality=85, optimize=True)
-
选择高效格式:
- 照片类图片:JPEG (quality=85)
- 截图/图表:PNG (optimize=True)
- 透明背景:PNG
- 动态图:WebP
-
使用 URL 模式:对于大图片,使用公网 URL 而非 base64
# Anthropic 支持 URL 模式
{
"type": "image",
"source": {
"type": "url",
"url": "https://example.com/image.jpg"
}
}
💰 成本优化: base64 编码会增加约 33% 的 token 消耗成本。通过 API易 apiyi.com 平台调用 API,平台提供智能图片压缩和格式优化服务,可降低 20-30% 的 API 调用成本。
跨平台统一封装方案
设计统一的图片处理接口
为了简化多平台集成,建议封装统一的图片处理类:
from enum import Enum
import base64
from typing import Union
from pathlib import Path
class APIProvider(Enum):
GEMINI = "gemini"
OPENAI = "openai"
ANTHROPIC = "anthropic"
class ImageFormatter:
"""统一的图片格式转换器"""
def __init__(self, provider: APIProvider):
self.provider = provider
def format_image(
self,
image_data: Union[str, bytes, Path],
mime_type: str = "image/jpeg"
) -> dict:
"""
将图片转换为指定 API 平台的格式
Args:
image_data: base64 字符串、二进制数据或文件路径
mime_type: MIME 类型
Returns:
符合目标 API 格式的字典
"""
# 统一转换为 base64 字符串
b64_data = self._to_base64(image_data)
# 根据平台返回不同格式
if self.provider == APIProvider.GEMINI:
return {
"inline_data": {
"data": b64_data,
"mimeType": mime_type
}
}
elif self.provider == APIProvider.OPENAI:
return {
"type": "image_url",
"image_url": {
"url": f"data:{mime_type};base64,{b64_data}"
}
}
elif self.provider == APIProvider.ANTHROPIC:
return {
"type": "image",
"source": {
"type": "base64",
"media_type": mime_type,
"data": b64_data
}
}
def _to_base64(self, data: Union[str, bytes, Path]) -> str:
"""内部方法:统一转换为 base64 字符串"""
if isinstance(data, str):
# 已经是 base64 字符串
return data.replace("data:image/jpeg;base64,", "").strip()
elif isinstance(data, bytes):
# 二进制数据
return base64.b64encode(data).decode('utf-8')
elif isinstance(data, Path):
# 文件路径
with open(data, "rb") as f:
return base64.b64encode(f.read()).decode('utf-8')
# 使用示例
formatter_gemini = ImageFormatter(APIProvider.GEMINI)
formatter_openai = ImageFormatter(APIProvider.OPENAI)
formatter_anthropic = ImageFormatter(APIProvider.ANTHROPIC)
# 相同的图片数据,生成不同格式
image_path = Path("test.jpg")
gemini_format = formatter_gemini.format_image(image_path)
openai_format = formatter_openai.format_image(image_path)
anthropic_format = formatter_anthropic.format_image(image_path)
实际应用示例
# 统一的多平台图片识别函数
def recognize_image(
image_path: str,
prompt: str,
provider: APIProvider
) -> str:
"""跨平台图片识别接口"""
formatter = ImageFormatter(provider)
image_data = formatter.format_image(Path(image_path))
if provider == APIProvider.GEMINI:
# Gemini API 调用
payload = {
"contents": [{
"role": "user",
"parts": [image_data, {"text": prompt}]
}]
}
response = requests.post(GEMINI_URL, json=payload)
elif provider == APIProvider.OPENAI:
# OpenAI API 调用
messages = [{
"role": "user",
"content": [
image_data,
{"type": "text", "text": prompt}
]
}]
response = openai.ChatCompletion.create(
model="gpt-4-vision-preview",
messages=messages
)
elif provider == APIProvider.ANTHROPIC:
# Anthropic API 调用
client = anthropic.Anthropic()
message = client.messages.create(
model="claude-3-5-sonnet-20241022",
max_tokens=1024,
messages=[{
"role": "user",
"content": [
image_data,
{"type": "text", "text": prompt}
]
}]
)
return extract_response(response, provider)
# 使用示例
result = recognize_image(
"product.jpg",
"描述这个产品的特点",
APIProvider.ANTHROPIC
)
🎯 技术建议: 自行维护跨平台适配代码需要投入大量时间。我们建议直接使用 API易 apiyi.com 平台提供的统一 SDK,该 SDK 已内置所有主流模型的格式适配逻辑,支持一键切换模型而无需修改代码,大幅提升开发效率。
MIME 类型识别最佳实践
自动检测图片格式
import magic # python-magic 库
def detect_mime_type(file_path: str) -> str:
"""自动检测文件的 MIME 类型"""
mime = magic.Magic(mime=True)
return mime.from_file(file_path)
# 使用示例
mime_type = detect_mime_type("unknown.jpg")
print(mime_type) # 输出: image/jpeg
基于文件头的快速检测
def quick_detect_image_type(data: bytes) -> str:
"""基于文件魔数快速检测图片格式"""
# JPEG 文件头: FF D8 FF
if data[:3] == b'\xff\xd8\xff':
return "image/jpeg"
# PNG 文件头: 89 50 4E 47
elif data[:4] == b'\x89PNG':
return "image/png"
# WebP 文件头: RIFF....WEBP
elif data[:4] == b'RIFF' and data[8:12] == b'WEBP':
return "image/webp"
# GIF 文件头: GIF87a 或 GIF89a
elif data[:6] in (b'GIF87a', b'GIF89a'):
return "image/gif"
else:
return "application/octet-stream"
# 从 base64 检测
import base64
b64_string = "/9j/4AAQSkZJRgABAQAAAQABAAD..."
decoded = base64.b64decode(b64_string)
mime_type = quick_detect_image_type(decoded)
print(mime_type) # 输出: image/jpeg
base64 字符串特征识别
无需解码,直接从 base64 字符串开头判断:
def detect_from_base64_prefix(b64_string: str) -> str:
"""从 base64 前缀判断图片类型"""
# JPEG: /9j/
if b64_string.startswith('/9j/') or b64_string.startswith('iVBOR'):
return "image/jpeg"
# PNG: iVBORw0KGgo
elif b64_string.startswith('iVBORw0KGgo'):
return "image/png"
# WebP: UklGR
elif b64_string.startswith('UklGR'):
return "image/webp"
# GIF: R0lGOD
elif b64_string.startswith('R0lGOD'):
return "image/gif"
else:
return "unknown"
常见格式的 base64 前缀:
- JPEG:
/9j/或iVBOR - PNG:
iVBORw0KGgo - WebP:
UklGR - GIF:
R0lGOD
性能优化策略
策略 1:图片预处理流水线
from PIL import Image
import io
import base64
def optimize_image_for_api(
image_path: str,
max_size: tuple = (1920, 1080),
quality: int = 85
) -> tuple[str, str]:
"""
优化图片用于 API 调用
Returns:
(base64_string, mime_type)
"""
# 打开图片
img = Image.open(image_path)
# 1. 转换 RGBA 为 RGB(处理透明背景)
if img.mode == 'RGBA':
background = Image.new('RGB', img.size, (255, 255, 255))
background.paste(img, mask=img.split()[3])
img = background
# 2. 等比例缩放
img.thumbnail(max_size, Image.Resampling.LANCZOS)
# 3. 压缩保存到内存
buffer = io.BytesIO()
img.save(buffer, format='JPEG', quality=quality, optimize=True)
# 4. 转换为 base64
buffer.seek(0)
b64_string = base64.b64encode(buffer.read()).decode('utf-8')
return b64_string, "image/jpeg"
# 使用示例
b64_data, mime_type = optimize_image_for_api("large_image.png")
print(f"原始大小: 5.2 MB -> 优化后: {len(b64_data) * 0.75 / 1024 / 1024:.2f} MB")
策略 2:批量图片异步处理
import asyncio
from concurrent.futures import ThreadPoolExecutor
async def process_images_batch(
image_paths: list[str],
provider: APIProvider
) -> list[dict]:
"""异步批量处理图片"""
formatter = ImageFormatter(provider)
# 使用线程池并发处理
with ThreadPoolExecutor(max_workers=5) as executor:
loop = asyncio.get_event_loop()
tasks = [
loop.run_in_executor(
executor,
formatter.format_image,
Path(path)
)
for path in image_paths
]
return await asyncio.gather(*tasks)
# 使用示例
image_files = ["img1.jpg", "img2.png", "img3.jpg"]
results = asyncio.run(process_images_batch(image_files, APIProvider.GEMINI))
策略 3:缓存机制
import hashlib
from functools import lru_cache
@lru_cache(maxsize=100)
def cached_image_encoding(file_path: str, provider: str) -> dict:
"""缓存图片编码结果"""
# 计算文件哈希作为缓存键
with open(file_path, "rb") as f:
file_hash = hashlib.md5(f.read()).hexdigest()
formatter = ImageFormatter(APIProvider[provider])
return formatter.format_image(Path(file_path))
# 重复调用相同图片时直接从缓存获取
result1 = cached_image_encoding("test.jpg", "GEMINI") # 首次计算
result2 = cached_image_encoding("test.jpg", "GEMINI") # 从缓存获取
💡 选择建议: 图片优化需要处理格式转换、压缩、缓存等多个环节。API易 apiyi.com 平台提供智能图片处理服务,自动完成格式检测、智能压缩、CDN 缓存等操作,开发者只需专注业务逻辑,无需关心底层优化细节。
实战案例:多模型图片识别对比
需求场景
需要同时调用 Gemini、GPT-4V 和 Claude 3.5 对同一张图片进行识别,并对比结果。
完整实现代码
import asyncio
import aiohttp
from typing import Dict, Any
class MultiModelImageRecognizer:
"""多模型图片识别器"""
def __init__(self, api_keys: dict):
self.api_keys = api_keys
self.formatters = {
"gemini": ImageFormatter(APIProvider.GEMINI),
"openai": ImageFormatter(APIProvider.OPENAI),
"anthropic": ImageFormatter(APIProvider.ANTHROPIC)
}
async def recognize_with_all_models(
self,
image_path: str,
prompt: str
) -> Dict[str, Any]:
"""并发调用三个模型识别图片"""
# 优化图片
b64_data, mime_type = optimize_image_for_api(image_path)
# 并发调用
tasks = [
self._call_gemini(b64_data, mime_type, prompt),
self._call_openai(b64_data, mime_type, prompt),
self._call_anthropic(b64_data, mime_type, prompt)
]
results = await asyncio.gather(*tasks, return_exceptions=True)
return {
"gemini": results[0],
"openai": results[1],
"anthropic": results[2]
}
async def _call_gemini(self, b64_data: str, mime: str, prompt: str):
"""调用 Gemini API"""
image_data = self.formatters["gemini"].format_image(b64_data, mime)
payload = {
"contents": [{
"role": "user",
"parts": [image_data, {"text": prompt}]
}]
}
async with aiohttp.ClientSession() as session:
async with session.post(
"https://generativelanguage.googleapis.com/v1beta/models/gemini-pro-vision:generateContent",
json=payload,
headers={"Content-Type": "application/json"}
) as resp:
return await resp.json()
async def _call_openai(self, b64_data: str, mime: str, prompt: str):
"""调用 OpenAI API"""
image_data = self.formatters["openai"].format_image(b64_data, mime)
payload = {
"model": "gpt-4-vision-preview",
"messages": [{
"role": "user",
"content": [
image_data,
{"type": "text", "text": prompt}
]
}]
}
async with aiohttp.ClientSession() as session:
async with session.post(
"https://api.openai.com/v1/chat/completions",
json=payload,
headers={
"Authorization": f"Bearer {self.api_keys['openai']}",
"Content-Type": "application/json"
}
) as resp:
return await resp.json()
async def _call_anthropic(self, b64_data: str, mime: str, prompt: str):
"""调用 Anthropic API"""
image_data = self.formatters["anthropic"].format_image(b64_data, mime)
payload = {
"model": "claude-3-5-sonnet-20241022",
"max_tokens": 1024,
"messages": [{
"role": "user",
"content": [
image_data,
{"type": "text", "text": prompt}
]
}]
}
async with aiohttp.ClientSession() as session:
async with session.post(
"https://api.anthropic.com/v1/messages",
json=payload,
headers={
"x-api-key": self.api_keys['anthropic'],
"anthropic-version": "2023-06-01",
"content-type": "application/json"
}
) as resp:
return await resp.json()
# 使用示例
async def main():
recognizer = MultiModelImageRecognizer({
"gemini": "YOUR_GEMINI_KEY",
"openai": "YOUR_OPENAI_KEY",
"anthropic": "YOUR_ANTHROPIC_KEY"
})
results = await recognizer.recognize_with_all_models(
"product.jpg",
"详细描述这个产品的特点和卖点"
)
print("Gemini 结果:", results["gemini"])
print("OpenAI 结果:", results["openai"])
print("Anthropic 结果:", results["anthropic"])
asyncio.run(main())
🚀 快速开始: 上述代码需要管理多个 API 密钥、处理不同的错误格式、实现重试逻辑等复杂工作。推荐使用 API易 apiyi.com 平台,一个 API 密钥即可调用所有模型,统一的错误处理和自动重试机制,5 分钟即可完成多模型对比功能的集成。
常见问题解答
为什么 OpenAI 使用 Data URL 而不是分离式设计?
技术原因:
- Web 标准兼容:Data URL 是 W3C 标准,可直接用于浏览器环境
- 单字段传输:减少 JSON 结构嵌套层级,简化序列化
- 历史延续:GPT-4V 早期版本就采用此格式,保持向后兼容
适用场景:
- 前端直接调用 API(浏览器环境)
- 需要在 HTML 中直接渲染的场景
- 简化的单图片处理流程
Gemini 和 Anthropic 的 mimeType vs media_type 有何区别?
命名差异:
- Gemini:
mimeType(驼峰命名,JavaScript 风格) - Anthropic:
media_type(下划线命名,Python 风格)
功能完全相同,都表示 MIME 媒体类型。选择哪种命名主要是 API 设计风格的偏好。
base64 编码后的图片能否直接用于所有平台?
不能。需要根据平台要求添加正确的格式封装:
| 平台 | 需要的额外处理 |
|---|---|
| Gemini | 添加 mimeType 字段 |
| OpenAI | 添加 data:image/jpeg;base64, 前缀 |
| Anthropic | 添加 media_type 和 role 字段 |
如何选择 JPEG 还是 PNG 格式?
选择标准:
使用 JPEG:
- ✅ 照片、复杂图像(色彩丰富)
- ✅ 需要控制文件大小(节省成本)
- ✅ 不需要透明背景
- ❌ 不适合文字截图(会模糊)
使用 PNG:
- ✅ 截图、图表、文字内容
- ✅ 需要透明背景
- ✅ 要求无损压缩(质量优先)
- ❌ 文件体积较大
API易平台如何处理格式差异?
API易 apiyi.com 平台提供智能格式适配层:
- 自动检测输入格式:识别用户提交的图片格式
- 智能转换:根据目标模型自动转换为对应格式
- 统一接口:用户只需使用一种格式,平台自动适配
- 性能优化:自动压缩、缓存、CDN 加速
示例:
# 用户只需使用 OpenAI 格式
payload = {
"model": "gemini-pro-vision", # 切换模型
"messages": [{
"role": "user",
"content": [
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,..."}}
]
}]
}
# API易平台自动转换为 Gemini 格式
💰 成本优化: 通过 API易 apiyi.com 平台调用多模型 API,不仅解决格式差异问题,还能享受比官方更优惠的价格(平均节省 10-20%),并提供统一的用量监控和成本分析工具。
总结与建议
三大平台格式总结
| 特性 | Gemini | OpenAI | Anthropic |
|---|---|---|---|
| 设计理念 | 分离式 | Data URL | 分离式 |
| 数据字段 | data |
url |
data |
| 类型字段 | mimeType |
内嵌在 URL | media_type |
| 必需字段 | data + mimeType | url (含前缀) | data + media_type + role |
| 适用场景 | 结构化 API | Web 兼容 | 多源支持 |
| 大小限制 | 20 MB | 20 MB | 5 MB |
最佳实践建议
对于小型项目(单一模型):
- 直接使用目标平台的原生格式
- 参考本文的代码示例快速集成
- 注意错误处理和格式验证
对于中型项目(2-3 个模型):
- 使用本文提供的
ImageFormatter统一封装类 - 实现图片预处理和优化流程
- 添加缓存机制降低重复处理成本
对于大型项目(多模型、高并发):
- 建议使用 API易 apiyi.com 平台统一接口
- 利用平台的智能格式转换和优化服务
- 享受统一的监控、计费和技术支持
技术选型建议
自行开发适合:
- 只使用单一模型
- 有充足的开发资源
- 需要深度定制化
使用 API易平台适合:
- 需要对比多个模型效果
- 希望快速上线产品
- 团队资源有限
- 关注成本优化
🎯 技术建议: 大模型 API 的格式差异只是冰山一角,还涉及限流策略、错误重试、Token 计费、版本更新等诸多问题。我们建议通过 API易 apiyi.com 平台统一管理这些复杂性,让开发团队专注于核心业务逻辑,将基础设施问题交给专业平台处理。
立即体验: 访问 API易 apiyi.com 平台,使用统一接口调用 Gemini、GPT-4、Claude 等多种模型,自动处理格式差异,5 分钟完成集成,开启您的多模型 AI 应用之旅!