在使用 Claude API 做长上下文调用时,很多开发者都遇到过同一个困惑:明明已经在 cache_control 字段里声明了缓存,但响应里的 cache_creation_input_tokens 和 cache_read_input_tokens 仍然是 0,账单上也看不到缓存折扣。本文将系统拆解 Claude prompt caching 不命中的 5 大原因,重点讲清楚最容易被忽视的「最低可缓存 Token 门槛」与「静默失败」机制。
核心价值: 读完本文,你将看懂 Anthropic 各模型的最低缓存门槛、明白为什么短提示词加 cache_control 也不报错却没缓存,并学会用 4 行代码判断到底命没命中。

Claude prompt caching 核心要点
Claude prompt caching 是 Anthropic 提供的提示词缓存机制:把重复出现的系统提示词、长文档、工具定义存到一个临时缓存里,下一次命中时按读价计费,比正常输入价格便宜约 90%。它的关键特征是「前缀匹配 + 显式声明 + 静默失败」,这三点决定了你大多数排查问题的方向。
| 要点 | 说明 | 排查价值 |
|---|---|---|
| 显式声明 | 必须在 system、messages 或 tools 内插入 cache_control 块 |
漏写或位置错都不会有缓存 |
| 前缀匹配 | 命中要求缓存块之前的所有内容字节级一致 | 哪怕多一个空格也会失效 |
| 静默失败 | 不满足条件的请求会正常返回,不报错也不缓存 | 必须主动校验 usage 字段 |
| TTL 限制 | 默认 5 分钟,最长 1 小时 | 长间隔调用会自然过期 |
「静默失败」是这套机制最容易让人翻车的部分。Anthropic 文档明确指出:当你的请求不满足缓存条件(例如长度不够、前缀变了),API 仍然会返回正常的回答,但不会创建缓存、也不会读缓存、更不会抛错。这意味着你在调用代码里看不到任何异常,只能通过响应里的 usage 对象主动检查。
如果你正在通过 API易 apiyi.com 平台调用 Claude 的 Sonnet、Opus、Haiku 系列模型,缓存逻辑和 Anthropic 官方接口完全一致,建议在落库前先打印一次 usage 字段,确认缓存确实生效再上量。
Claude prompt caching 各模型最低 Token 门槛速查
最常被忽视的不命中原因,是提示词长度没达到 Anthropic 对该模型设定的「最低可缓存 Token」门槛。低于这个长度,即使写了 cache_control 也只会被当作普通请求处理。不同模型的门槛差距很大,下表是 2026 年 5 月当前的官方数据,建议直接收藏。
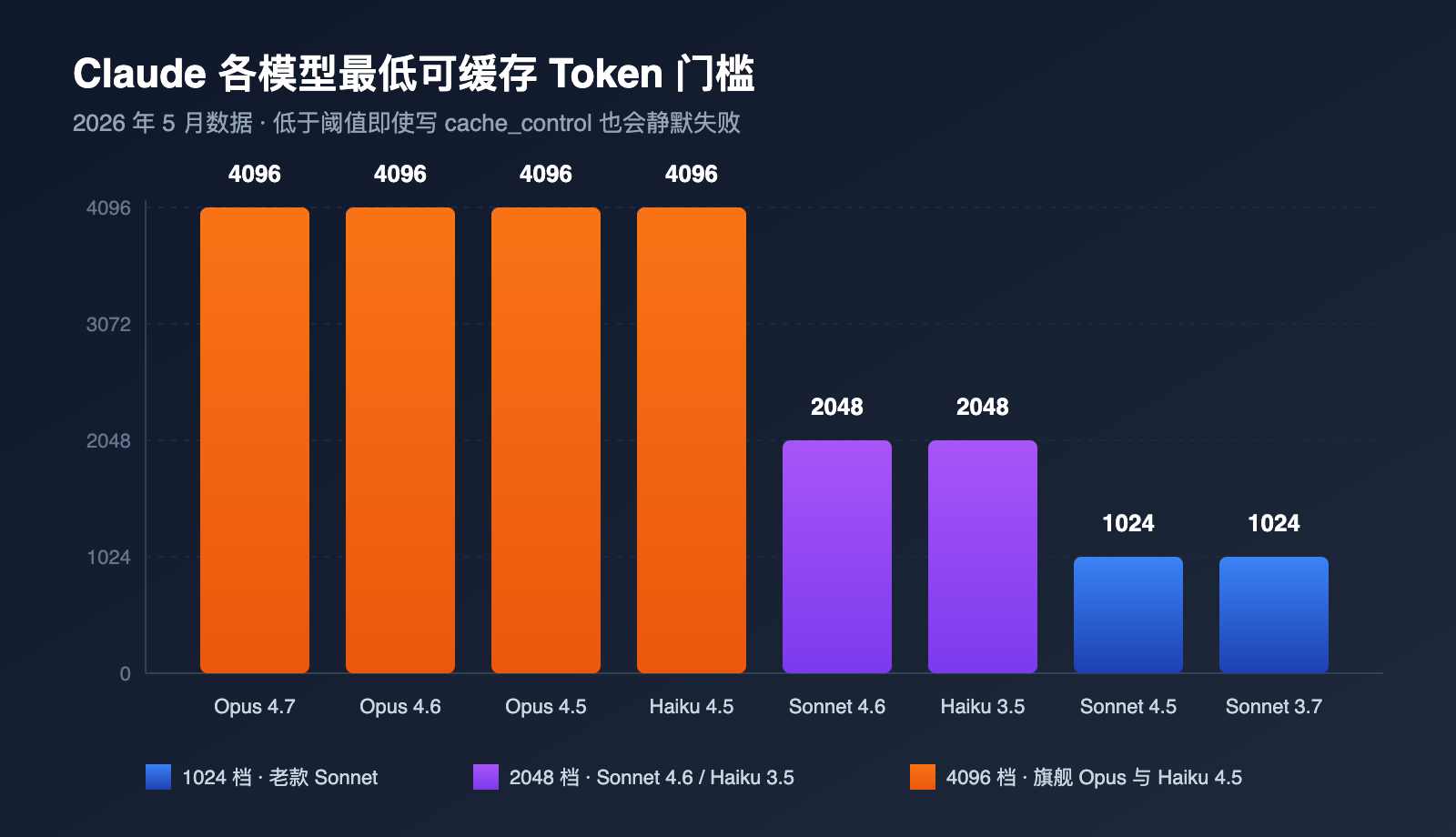
| 模型 | 最低可缓存 Token | 备注 |
|---|---|---|
| Claude Opus 4.7 / 4.6 / 4.5 | 4096 | 最新旗舰,门槛拉到最高 |
| Claude Sonnet 4.6 | 2048 | 当前主力 Sonnet,门槛翻倍 |
| Claude Sonnet 4.5 / Sonnet 4 / Sonnet 3.7 | 1024 | 历史经典 Sonnet 系列 |
| Claude Opus 4.1 / Opus 4 | 1024 | 老一代 Opus |
| Claude Haiku 4.5 | 4096 | Haiku 反而比 Sonnet 高 |
| Claude Haiku 3.5 | 2048 | 长期稳定的快速模型 |
很多人第一次看到这张表会愣住:为什么 Haiku 4.5 这种「小模型」的门槛反而和 Opus 4.7 一样高?原因是新一代 Haiku 用了更长的注意力窗口,缓存命中的工程意义只有在更长的前缀上才显著,所以 Anthropic 在产品策略上把门槛推上去了。
实践中最常见的误判,是开发者按照旧版 Sonnet 3.7 的 1024 习惯去设计提示词,切到 Sonnet 4.6 之后突然失效,却以为是代码写错。如果你在 API易 apiyi.com 上同时调用多代 Claude 模型,强烈建议把这张表作为参数检查的一部分,按 model 字段动态判断门槛。
Claude prompt caching 不命中的 5 大原因
理解了「最低 Token 门槛」和「静默失败」之后,就可以系统排查不命中问题了。下面这 5 个原因按出现频率排序,前两个占据了我们日常调试遇到的大多数案例。
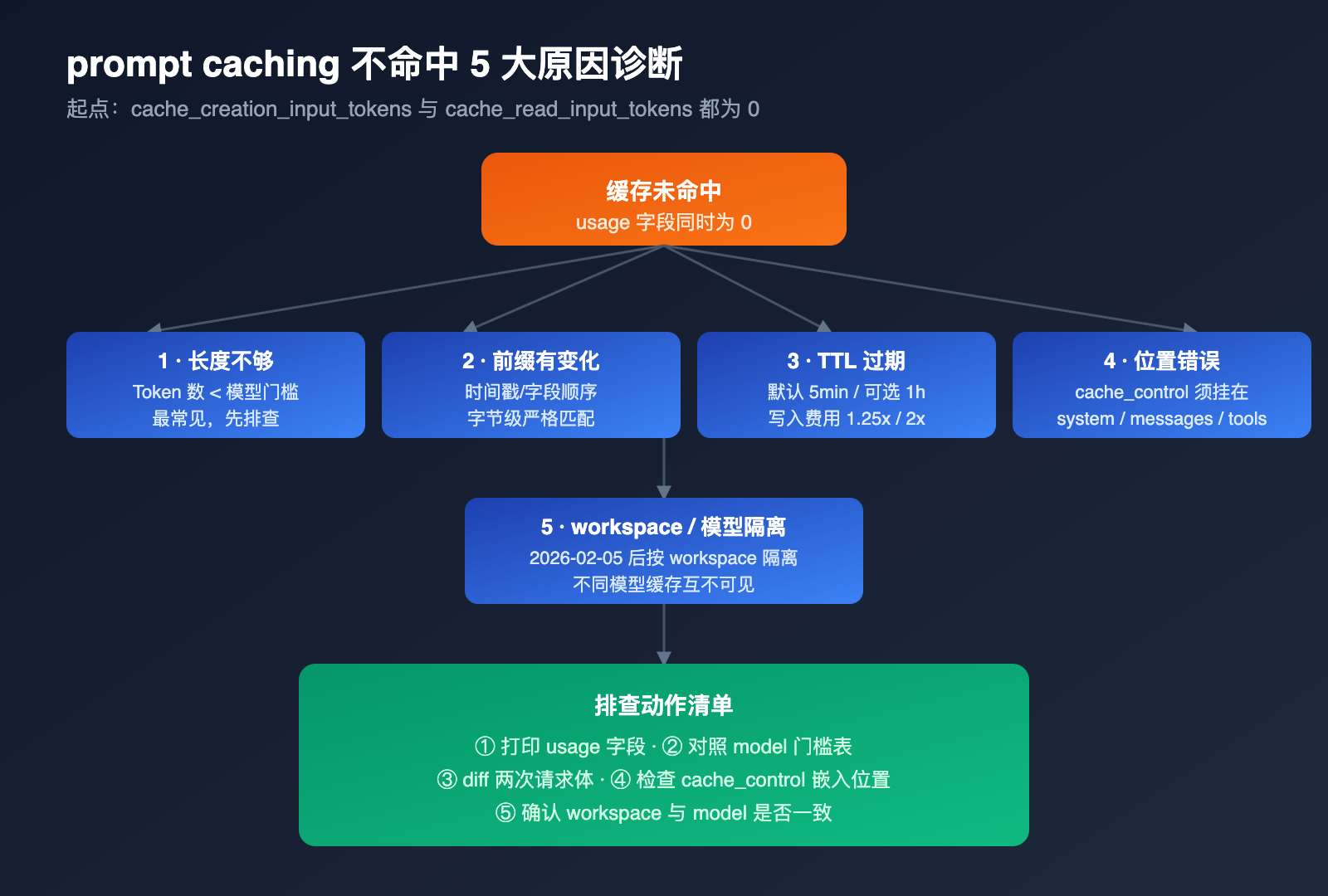
原因 1:提示词长度低于最低门槛
这是绝对的头号杀手。例如你在 Sonnet 4.6 上声明缓存,但实际系统提示词只有 1500 token,缓存就完全不会建立。诊断方法很简单:先用本地 tokenizer 估算一下系统提示词 + 工具定义 + 已缓存消息部分的 Token 总量,再对照上表的门槛。
更隐蔽的情况是「多个 cache_control 块叠加」。Anthropic 的策略是「每个缓存断点都要让其前面的累计内容达到模型门槛」,否则该断点失效。建议初学者只使用一个 cache_control 块,等熟悉机制后再做分层缓存。
原因 2:缓存前缀有任何字节级变化
prompt caching 是严格的前缀匹配,意味着你的系统提示词、工具定义、消息历史,只要有一个字符不一样,缓存就视为失效,必须重新写入。常见的「伪变化」包括:
- 系统提示词里夹了带时间戳的渲染逻辑,每次请求时间都不同
- 工具定义按字典顺序序列化时,因为 Python 字典无序导致字段顺序漂移
- 对历史消息做了 trim 或 dedupe 处理,导致同一段对话出现细微差异
排查这种问题最直接的办法是对两次请求的完整 payload 做 diff 比对。如果你在自研网关里用 API易 apiyi.com 做统一中转,可以在网关日志里直接把请求体 hash 出来,发现 hash 不一致就基本能定位到前缀漂移。
原因 3:TTL 已过期
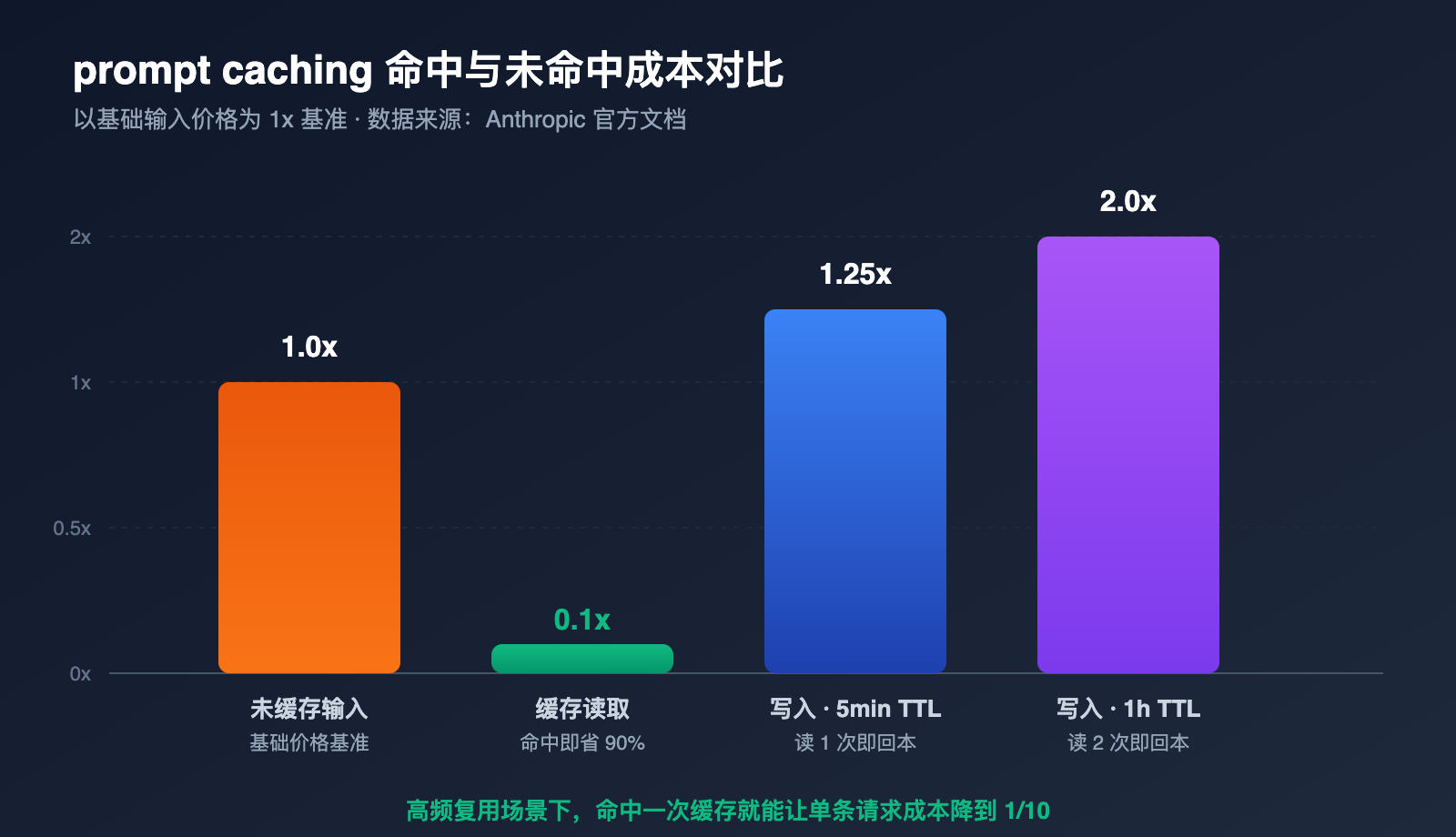
默认 TTL 是 5 分钟,超过这个间隔后,旧缓存条目会被释放,下一次请求会重新触发写入。1 小时 TTL 写入价格是基础输入价的 2 倍,要按调用频率衡量是否值得开启。
判断 TTL 过期的特征是:cache_creation_input_tokens 突然变成非零数值,而你以为这条请求应该读缓存。如果发现这种情况,可以缩短两次请求间隔,或者切到 "ttl": "1h" 长 TTL。
原因 4:cache_control 位置错误
cache_control 必须挂在 system、messages 或 tools 数组里的具体内容块上,并且 type 一定是 ephemeral。常见错误用法包括:
- 把
cache_control放在了messages.create()的顶层参数而不是某个 content block 上 - 在
messages数组里的 user 消息上声明,但前缀实际想缓存的是 system - 同一条 message 里写了多个 cache_control 但都没达到 2048 门槛
正确做法是把 cache_control 直接嵌在你希望「截止到此为止」的那个 block 内部,缓存会从 prompt 开头一直锁到这个 block 结尾。
原因 5:跨工作区或跨模型导致缓存不共享
自 2026 年 2 月 5 日起,Anthropic 把 prompt cache 的隔离边界改为「工作区级别」,意味着不同 workspace 之间的缓存互不可见。如果你的两次调用分别走了不同的 API Key、不同的 workspace,缓存自然不能复用。
模型层面也是一样的逻辑。把同一份提示词在 Sonnet 4.6 上写入缓存,下次切到 Sonnet 4.5 调用,绝不会命中。多模型调度时,最好按 model 维度分别维护一份缓存预热脚本,或者通过 API易 apiyi.com 这类聚合平台直接复用同一个上游 workspace,避免缓存碎片化。
Claude prompt caching 命中校验代码与判断逻辑
排查不命中问题的第一步永远是「打印 usage 字段」。Anthropic 在每次 messages.create 的返回里都会附带一个 usage 对象,里面有 4 个关键字段,是判断缓存状态的唯一可靠依据。
极简校验代码
import anthropic
client = anthropic.Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model="claude-sonnet-4-6",
max_tokens=1024,
system=[{
"type": "text",
"text": LONG_SYSTEM_PROMPT, # 必须 ≥ 2048 token
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": "your question"}]
)
u = response.usage
print(f"写缓存: {u.cache_creation_input_tokens}")
print(f"读缓存: {u.cache_read_input_tokens}")
print(f"未缓存输入: {u.input_tokens}")
把这段代码当作排查模板。每当怀疑缓存没生效时,第一时间跑一遍,看返回字段就能锁定问题方向。
查看完整封装版本
import anthropic
import logging
MIN_TOKENS = {
"claude-opus-4-7": 4096,
"claude-opus-4-6": 4096,
"claude-opus-4-5": 4096,
"claude-sonnet-4-6": 2048,
"claude-sonnet-4-5": 1024,
"claude-haiku-4-5": 4096,
"claude-haiku-3-5": 2048,
}
def call_with_cache_check(model: str, system_text: str, user_msg: str):
client = anthropic.Anthropic(
api_key="YOUR_APIYI_KEY",
base_url="https://api.apiyi.com"
)
response = client.messages.create(
model=model,
max_tokens=1024,
system=[{
"type": "text",
"text": system_text,
"cache_control": {"type": "ephemeral"}
}],
messages=[{"role": "user", "content": user_msg}]
)
u = response.usage
if u.cache_creation_input_tokens == 0 and u.cache_read_input_tokens == 0:
logging.warning(
f"缓存未生效,疑似低于 {MIN_TOKENS.get(model)} token 门槛"
)
return response
命中状态判断表
cache_creation_input_tokens |
cache_read_input_tokens |
判断结论 |
|---|---|---|
| > 0 | = 0 | 首次写入缓存(正常) |
| = 0 | > 0 | 命中缓存(最理想) |
| > 0 | > 0 | 部分命中,新增部分被写入 |
| = 0 | = 0 | 未缓存,需要排查上述 5 大原因 |
最后一行就是出现问题时的特征。看到这一行就直接跳到原因 1 开始排查,按 5 个方向逐一对照即可。如果团队对接口稳定性要求高,可以把这套判断逻辑包成中间件挂在 API易 apiyi.com 调用链路上,触发告警时立即通知排查。
凑够最低 Token 门槛的 4 种实用技巧
当你确认是「长度不够」导致不命中后,下一步就是想办法让缓存前缀达到门槛。下面 4 个技巧按推荐程度排序,前 3 种几乎没有副作用。
| 技巧 | 适用场景 | 大致增加 Token | 注意事项 |
|---|---|---|---|
| 完整知识库 | 系统提示词太薄 | +2000~4000 | 必须每次都真的会用 |
| 工具定义集中托管 | 多工具应用 | +500~2000 | tools 字段同样可缓存 |
| 常用 few-shot 示例 | 任务化提示 | +1000~3000 | 示例要有泛化价值 |
| 填充无关文本 | 应急 | 任意 | 不推荐,影响输出质量 |
第一种「完整知识库」是最稳的做法。如果你的应用本来就有一份内部知识库,例如产品 FAQ、风格指南、流程 SOP,可以一次性塞进 system 块顶部并打上 cache_control,让长度直接超过 4096,所有模型一次性满足门槛。
第二种「工具定义」常被忽略。Anthropic 的 tools 字段同样支持 cache_control,对于多工具 Agent 应用尤其有效。一份典型的工具描述加上 JSON Schema 就轻松突破 2048。
第三种「few-shot 示例」适合复杂任务化场景。把 3-5 个标准案例放在 system 末尾,既能提升输出稳定性,又可以把 Token 数从 1500 提到 2500-3500,刚好越过 Sonnet 4.6 的门槛。
第四种「填充无关文本」纯属应急,不建议日常使用,因为模型仍然会读那些填充文本,可能影响输出风格。如果实在没办法凑长度,可以考虑通过 API易 apiyi.com 平台切换到门槛较低的 Sonnet 4.5 或 Sonnet 3.7,让现有提示词直接落入 1024 门槛区间。
常见问题
Q1: 我加了 cache_control 但没缓存,是不是 API 出 bug 了?
大概率不是 bug,而是触发了静默失败机制。第一步先检查 model 字段对应的最低 Token 门槛,第二步打印 usage 对象。99% 的情况都是长度不够或前缀变化导致。
Q2: cache_creation_input_tokens 收费贵不贵?
5 分钟 TTL 写入是基础输入价的 1.25 倍,1 小时 TTL 是 2 倍。读取价是 0.1 倍。一般来说,5min 缓存被读 1 次就回本,1h 缓存被读 2 次回本,多次复用越多收益越大。
Q3: 旧版文档说 Sonnet 最低是 1024,新版怎么变成 2048 了?
这是 Sonnet 4.6 才出现的新门槛。Sonnet 4.5 及更老版本仍然是 1024。建议在代码里维护一份「model → 门槛」映射表,按调用模型动态判断。通过 API易 apiyi.com 调用时,model 字段的命名和 Anthropic 官方完全一致,可以直接复用同一份映射逻辑。
Q4: 多个 cache_control 块怎么用才安全?
每个 cache_control 都要求前缀累计达到门槛,否则该断点失效。新手建议只放一个断点,把整个 system 块都缓存。如果非要分层,可以把「极少变化的知识库」放第一层,「偶尔变化的工具定义」放第二层。
Q5: 我能用国内中转平台测试 prompt caching 吗?
可以。API易 apiyi.com 等聚合中转平台的 Claude 系列接口与 Anthropic 官方完全兼容,包括 cache_control、ttl、usage 字段。开发者可以在中转平台上完成调试和上量,缓存逻辑、计费规则保持一致。
总结
Claude prompt caching 看起来只是加一个 cache_control 字段那么简单,但真正用起来会被「静默失败 + 最低 Token 门槛 + 前缀严格匹配」这三件事坑到。本文给出的 5 大原因排查清单和命中判断表,可以帮助开发者把 90% 的不命中问题在 5 分钟内定位清楚。
落地建议是把校验代码做成默认中间件、把模型门槛表做成代码常量、把缓存预热做成单独脚本。如果你的业务在多模型之间频繁切换,可以通过 API易 apiyi.com 平台统一管理 Claude 调用入口,复用同一份缓存策略和监控逻辑,避免不同环境之间出现缓存碎片化和门槛不一致带来的隐性成本。
作者: APIYI 技术团队
联系: 通过 API易 apiyi.com 获取 Claude 全系列模型与 prompt caching 完整调试支持
更新时间: 2026-05-12