OpenAI 官方发布 GPT 5.5 提示词指南后,最值得注意的变化不是某个新的提示词模板,而是提示词设计方法的整体转向。
过去很多开发者习惯写很长的系统提示词。
这些提示词通常会列出详细流程、固定步骤、强制语气、禁止项、工具调用顺序和大量兜底规则。
这种写法在早期模型上有价值,因为早期模型更需要外部流程来保持稳定。
但 GPT 5.5 的能力边界发生了变化。
官方指南明确强调,GPT 5.5 更适合结果优先、约束清晰、过程留白的提示词。
换句话说,开发者不应该继续把 GPT 5.5 当作需要严格牵引的旧模型。
更好的做法是告诉模型目标是什么、成功标准是什么、可用证据是什么、最终输出要包含什么。
至于搜索、推理、取舍、工具调用和中间路径,应该给模型保留一定空间。
这也是本文的核心关键词:GPT 5.5 提示词指南。
本文将结合 OpenAI 官方英文资料,系统讲解 GPT 5.5 提示词指南的关键变化,并给出可直接落地的旧 Prompt 迁移方法。
如果你正在维护客服助手、知识库问答、研究代理、代码代理、内容生成系统或工作流自动化工具,这篇文章可以作为一次 Prompt 升级清单。

GPT 5.5 提示词指南的核心变化是什么?
GPT 5.5 提示词指南最核心的一句话,可以概括为:描述目的地,而不是替模型铺满每一步路。
OpenAI 官方文档指出,GPT 5.5 在提示词定义目标结果、成功标准、约束条件和可用上下文时表现更强。
这并不意味着提示词越短越好。
短不是目标。
清晰才是目标。
如果短提示词缺少成功标准、证据边界和输出结构,GPT 5.5 仍然可能给出不稳定结果。
真正应该删除的是没有带来控制力的流程噪音。
例如「你必须先思考,再分析,再总结,再输出」这种泛化步骤,通常不如直接定义最终交付物。
对 GPT 5.5 来说,更好的提示词结构是:
完成这个任务,交付可直接使用的结果。
成功标准:
- 覆盖用户目标
- 遵守约束
- 标明不确定信息
- 输出指定格式
这类提示词没有把每一步过程写死,却给出了清晰的评判标准。
它让模型可以根据任务形态选择最合适的推理路径。
GPT 5.5 提示词指南关键结论
| 变化点 | 官方方向 | 对开发者的影响 | 推荐动作 |
|---|---|---|---|
| 结果优先 | 先定义目标和成功标准 | 旧的步骤型 Prompt 可能变成噪音 | 从输出契约重新设计 |
| 少写流程 | 不再搬运旧提示词堆栈 | 过度指定会缩小搜索空间 | 删除泛化步骤 |
| 推理调优 | low 和 medium 需要重新评估 |
不要默认开最高推理 | 用评测选择档位 |
| 工具工作流 | preamble、phase、assistant-item replay 仍重要 | 工具型 Agent 不能只靠短提示词 | 保留状态和工具规则 |
| 用户体验 | personality、检索预算、验证规则更重要 | 面向客户的输出要可控 | 写短而明确的体验规则 |
选择建议:如果你在 API 中接入 GPT 5.5,不建议直接复用 GPT 4 或 GPT 5.2 时代的长提示词。我们建议先通过 API易 apiyi.com 建立一套可对比的测试入口,把旧 Prompt、新 Prompt、不同 reasoning_effort 放在同一组样本上评测,再决定迁移方案。
GPT 5.5 提示词指南为什么反对旧 Prompt 过度指定?
旧 Prompt 常见问题不是「长」本身。
真正的问题是长提示词里包含大量不再必要的流程性指令。
早期模型需要开发者明确写出「第一步、第二步、第三步」,否则容易跑偏。
到了 GPT 5.5,模型已经具备更强的任务理解、路径规划、工具使用和验证能力。
如果继续塞入大量历史包袱,反而会让模型把注意力放在遵守旧流程上,而不是解决当前问题。
官方 GPT 5.5 提示词指南提到,旧提示词往往因为早期模型需要更多牵引而把流程写得过细。
在 GPT 5.5 上,这种做法可能增加噪音,限制模型搜索空间,或者让答案变得机械。
这就是很多团队升级模型后反而觉得「输出变僵硬」的原因。
他们换了模型,却没换 Prompt。
GPT 5.5 提示词指南下旧 Prompt 的 5 类噪音
-
泛化步骤噪音:例如固定要求「先分析、再拆解、再执行、再总结」。
-
绝对词噪音:例如到处使用
ALWAYS、NEVER、must、only。 -
重复角色噪音:例如反复声明「你是世界顶级专家」但没有成功标准。
-
输出装饰噪音:例如无论任务大小都要求复杂标题、表格、emoji 或长解释。
-
工具顺序噪音:例如把工具调用顺序写死,却没有说明什么时候该停。
GPT 5.5 不需要开发者替它模拟思考流程。
它更需要开发者定义任务边界。
边界包括:目标、约束、证据、失败条件、输出格式、验证标准和停止条件。
GPT 5.5 提示词指南下旧 Prompt 与新 Prompt 对比
| 维度 | 旧 Prompt 写法 | GPT 5.5 推荐写法 | 迁移重点 |
|---|---|---|---|
| 任务目标 | 写很多步骤 | 明确最终交付物 | 从流程改为结果 |
| 推理过程 | 要求固定链路 | 允许模型选择路径 | 删除伪流程 |
| 成功标准 | 通常缺失 | 明确什么算完成 | 加完成标准 |
| 约束条件 | 混在长规则里 | 单独列出关键约束 | 抽取硬约束 |
| 输出格式 | 过度装饰 | 按产品场景定义 | 保留必要结构 |
| 工具调用 | 固定顺序 | 用决策规则触发 | 写清何时调用 |
很多提示词迁移失败,是因为团队只做了模型名替换。
例如把 gpt-5.4 改成 gpt-5.5,但保留了旧 Prompt 的全部流程堆栈。
这种迁移方式表面上最省事,实际最容易带来隐性退化。
更稳妥的方法是重新建立 GPT 5.5 的最小可用提示词基线。
GPT 5.5 提示词指南推荐的结果优先结构
GPT 5.5 提示词指南不是让开发者什么都不写。
它建议开发者把注意力放在「什么是好结果」上。
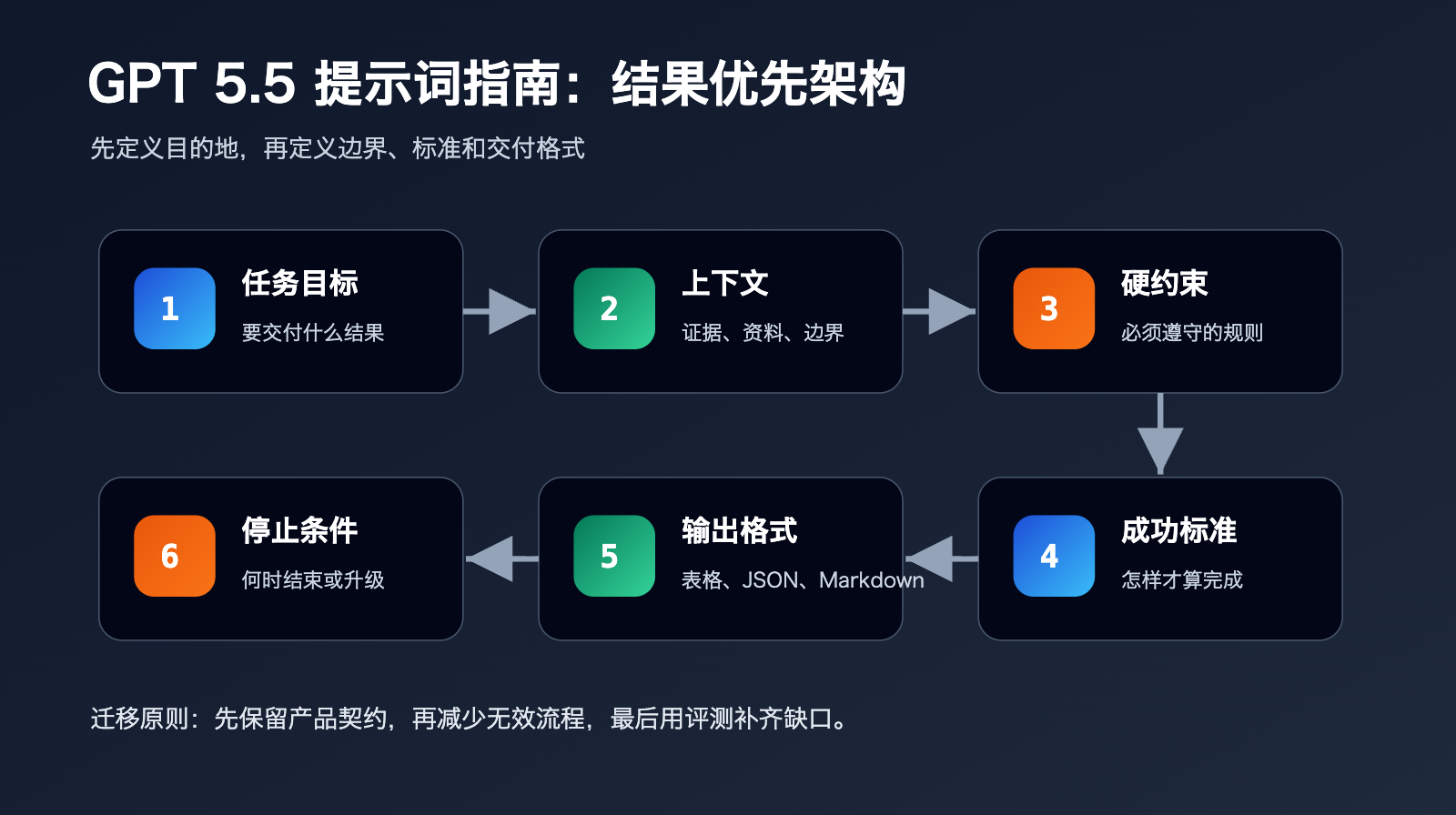
一个可复用的 GPT 5.5 提示词结构,可以拆成 6 个部分。
第一是任务目标。
第二是上下文和证据。
第三是硬性约束。
第四是成功标准。
第五是输出格式。
第六是停止条件或升级条件。
这 6 个部分足够覆盖大多数生产场景。
如果任务很简单,可以只保留其中 3 个部分。
如果任务涉及工具、检索、写入数据库或高风险决策,再补充工具规则和验证闭环。
GPT 5.5 提示词指南的结果优先模板
任务:
基于给定资料完成 {目标},输出可直接使用的 {交付物}。
上下文:
- 可使用的信息:{资料范围}
- 不可假设的信息:{边界}
约束:
- 必须遵守:{硬约束}
- 不确定时:{询问或标注规则}
成功标准:
- 结果覆盖 {关键需求}
- 结论有证据支持
- 输出符合 {格式}
- 明确列出 blockers
输出格式:
{结构化格式}
这个模板看起来不复杂,但它比长篇流程提示词更可控。
因为它让模型知道如何判断完成。
如果一个 Prompt 只能告诉模型「怎么做」,却没有告诉它「做到什么程度算好」,就很难稳定迁移到更强模型。
选择建议:如果你需要在多个模型之间切换,例如 GPT 5.5、GPT 5.4 mini、Claude 或 Gemini,建议把提示词模板拆成「模型无关的业务契约」和「模型相关的调优参数」。API易 apiyi.com 支持多模型统一调用,适合做这类迁移对比。
GPT 5.5 提示词指南如何处理推理强度?
GPT 5.5 提示词指南还有一个容易被忽略的点:不要把 reasoning_effort 当成万能旋钮。
很多团队升级模型后,第一反应是把推理强度拉高。
这会带来更高成本和更长延迟。
但官方指南建议,推理强度应该是最后一公里调优项,而不是质量提升的第一选择。
在很多场景里,清晰的输出契约、验证闭环和工具规则,比盲目提高推理强度更有效。
GPT 5.5 的官方提示词指南特别提到,low 和 medium effort 应该重新评估。
这意味着你不能沿用旧模型的推理档位经验。
例如某个 GPT 5.4 任务需要 high,在 GPT 5.5 上可能 medium 就足够。
某些短文本分类、字段抽取、客服分流、格式转换任务,甚至可以从 none 或 low 开始。
反过来,研究型、多文档冲突分析、战略写作、复杂代码迁移等任务,仍然适合 medium 或 high。
这个表格不是固定答案。
真正可靠的做法是做代表性样本评测。
先固定 Prompt,再比较不同 reasoning_effort 的质量、延迟和成本。
如果 low 已经能稳定通过评测,就没有必要默认 high。
如果 medium 失败,不要马上升级到 high。
先检查 Prompt 是否缺少完成标准、验证循环、工具持久性规则或错误恢复规则。
选择建议:如果你要在生产环境评估 GPT 5.5,建议准备 30-100 条真实样本,分别跑旧 Prompt、新 Prompt、不同 reasoning_effort。API易 apiyi.com 可以作为统一调用入口,方便记录模型、参数、响应时间和输出质量。
GPT 5.5 提示词指南下旧 Prompt 迁移步骤
旧 Prompt 迁移到 GPT 5.5,最忌讳一次性大改。
因为你很难判断质量变化来自模型、提示词、参数还是工具链。
官方 Using GPT 5.5 页面建议,把 GPT 5.5 当作新模型家族调优,而不是直接替换旧模型。
迁移应该从最小提示词基线开始。
这里的「最小」不是删到只剩一句话。
而是只保留产品契约必须依赖的指令。
产品契约包括:身份边界、任务目标、数据来源、输出格式、安全规则、工具权限和完成标准。
其余历史遗留内容都应该经过评测再决定是否加回。
GPT 5.5 提示词指南的迁移流程
| 步骤 | 操作 | 产出 | 注意事项 |
|---|---|---|---|
| 1 | 复制旧 Prompt | 旧版本基线 | 不要立即改写 |
| 2 | 标注硬约束 | 必须保留清单 | 安全和格式优先 |
| 3 | 删除伪流程 | 精简版 Prompt | 去掉泛化步骤 |
| 4 | 补成功标准 | 结果优先 Prompt | 明确完成条件 |
| 5 | 固定测试样本 | 评测集 | 覆盖失败场景 |
| 6 | 调 reasoning_effort | 参数矩阵 | 先 low / medium |
| 7 | 回补规则 | 最终 Prompt | 只补测出的问题 |
迁移时可以用一个简单原则判断某条指令是否应该保留:
如果删除它后,评测没有明显退化,就不要保留。
如果删除它后,模型稳定犯同类错误,再把它作为明确规则加回。
这样可以避免 Prompt 越迁移越臃肿。
GPT 5.5 提示词指南迁移示例
旧写法:
你必须一步一步思考。
你必须先分析用户需求。
你必须拆成多个阶段。
你必须按照第一步、第二步、第三步执行。
你必须最后总结。
GPT 5.5 新写法:
交付一份可执行的迁移计划。
成功标准:
- 说明当前问题
- 给出最小修改路径
- 标注风险和验证方法
- 最后输出 blockers
旧写法把注意力放在过程。
新写法把注意力放在结果。
GPT 5.5 更适合后一种方式。
GPT 5.5 提示词指南对工具型 Agent 的影响
GPT 5.5 提示词指南并不意味着工具型 Agent 可以删除所有流程规则。
相反,工具型 Agent 仍然需要明确的工具边界。
OpenAI 官方指南提到,preambles、phase handling 和 assistant-item replay 对工具密集型 Responses 工作流仍然重要。
这说明 GPT 5.5 的短提示词策略,主要针对无效流程噪音。
它不是鼓励开发者删除必要的状态管理和工具协议。
对于会搜索网页、读取文件、调用数据库、提交表单、生成补丁或执行 shell 的 Agent,提示词必须保留以下内容:
-
工具何时可以使用。
-
工具何时不能使用。
-
调用工具前是否需要确认。
-
工具失败后如何恢复。
-
什么时候停止继续调用。
-
最终回答要如何交代已执行动作。
工具型 Agent 的关键不是流程越少越好。
而是流程要有决策意义。
如果一个规则决定了安全边界、数据边界或成本边界,就应该保留。
如果一个规则只是历史上为了让旧模型不跑偏而写的冗余步骤,就应该删除。
选择建议:如果你的 GPT 5.5 Agent 需要联网搜索、调用数据库或多工具协作,建议在 API易 apiyi.com 之外保留一套独立日志系统,记录 prompt 版本、工具调用、token 使用和失败原因,方便定位是模型问题、提示词问题还是工具问题。

GPT 5.5 提示词指南在不同场景怎么落地?
不同业务场景需要的 Prompt 长度并不一样。
客服助手不应该照搬研究代理的 Prompt。
内容生成系统也不应该照搬代码代理的 Prompt。
GPT 5.5 提示词指南的真正价值,是帮助你判断哪些规则属于任务契约,哪些规则只是旧模型时代遗留的拐杖。
GPT 5.5 提示词指南场景落地表
| 场景 | 推荐 Prompt 重心 | 要避免的问题 | 验证方法 |
|---|---|---|---|
| 客服助手 | 结果、权限、升级条件 | 机械话术和过度共情 | 工单解决率 |
| 知识库问答 | 证据、引用、未知处理 | 无来源编造 | 抽样核对引用 |
| 内容生成 | 受众、结构、质量标准 | 空泛长文 | 人工评分和 SEO 检查 |
| 代码代理 | 修改范围、测试、完成定义 | 只改局部不验证 | 单测和 diff review |
| 研究代理 | 检索预算、证据等级、冲突处理 | 引用堆砌 | 来源质量和结论一致性 |
以内容生成为例。
旧 Prompt 往往会要求模型「先写引言、再写背景、再写特点、再写总结」。
GPT 5.5 更适合的方式是定义受众、核心观点、必须覆盖的问题、不能出现的误导、最终格式和质量检查标准。
以代码代理为例。
旧 Prompt 可能要求模型先输出完整计划。
GPT 5.5 更适合的方式是定义改动范围、验证命令、不能碰的文件、完成标准和遇到 blocker 时的处理方式。
以知识库问答为例。
关键不是让模型「仔细阅读资料」。
关键是告诉模型:只能基于检索资料回答,缺资料时如何说明,不确定信息如何标注,最终答案必须包含哪些来源。
选择建议:如果你运营多个站点、多个产品或多个模型入口,建议把 Prompt 管理当作版本化资产。通过 API易 apiyi.com 统一接入模型后,可以为不同站点维护独立 Prompt 版本,降低模型升级时的回归风险。
GPT 5.5 提示词指南的 API 调用示例
下面是一个极简示例,重点不是代码复杂度,而是展示结果优先 Prompt 如何放进 API 调用。
示例使用 OpenAI 兼容接口风格。
如果你使用 API易 apiyi.com,可以把 base_url 配置为兼容入口,便于统一调用和切换模型。
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1"
)
prompt = """
任务:把以下旧 Prompt 迁移为 GPT 5.5 风格。
成功标准:
- 删除无效流程噪音
- 保留安全和格式硬约束
- 补充成功标准和停止条件
- 输出新 Prompt 和修改说明
"""
response = client.responses.create(
model="gpt-5.5",
input=prompt,
reasoning={"effort": "low"}
)
print(response.output_text)
这个示例里没有要求模型一步一步思考。
它只定义了任务目标和成功标准。
如果评测发现 low 不够,再考虑 medium。
如果评测发现输出结构不稳定,先补输出格式,而不是直接提高推理档位。
选择建议:使用 API易 apiyi.com 做 GPT 5.5 Prompt 迁移测试时,可以把旧 Prompt、新 Prompt、模型参数和输出结果保存成对比表。这样团队讨论时有样本依据,而不是只凭单次体验判断。
GPT 5.5 提示词指南迁移检查清单
在正式上线 GPT 5.5 Prompt 前,建议按下面清单检查。
不要只看一次对话是否满意。
要看它在不同输入、不同边界条件、不同失败场景下是否稳定。
GPT 5.5 提示词指南上线前检查表
| 检查项 | 合格标准 | 不合格表现 |
|---|---|---|
| 目标清晰 | 一句话能说明交付物 | 模型不知道最终要产出什么 |
| 约束明确 | 硬规则单独列出 | 规则混在长段落里 |
| 成功标准 | 能判断是否完成 | 输出看起来完整但不可验收 |
| 工具边界 | 写清何时用、何时停 | 工具调用过多或过少 |
| 推理档位 | 有样本对比依据 | 默认 high 或 xhigh |
| 输出格式 | 与产品界面匹配 | 文本过长或结构不稳定 |
| 失败处理 | 能处理缺资料和冲突 | 编造、硬答、跳过 blocker |
如果检查表中有三项以上不合格,不建议直接上线。
这说明 Prompt 还没有从旧模型思维迁移出来。
上线前至少要准备一个小型评测集。
评测集不一定很大。
但必须真实。
真实样本比人工构造的完美样本更能暴露问题。
GPT 5.5 提示词指南总结
GPT 5.5 提示词指南不是在否定 Prompt Engineering。
它是在提醒开发者:更强模型需要新的控制方式。
旧模型时代的提示词,经常通过流程堆叠来换稳定性。
GPT 5.5 更适合通过目标、约束、证据、成功标准、验证闭环和输出契约来控制结果。
所以,迁移 GPT 5.5 Prompt 的第一步,不是把旧提示词改短。
而是重新判断每条指令是否还有控制价值。
没有控制价值的流程,删除。
涉及安全、格式、权限和工具边界的规则,保留。
缺失的成功标准、停止条件和验证方式,补上。
最后,用真实样本评测,而不是凭感觉上线。
对开发者来说,GPT 5.5 的提示词升级是一项产品工程工作。
对企业来说,它也是一次模型成本、质量和稳定性的综合优化机会。
如果你需要稳定接入 GPT 5.5,并同时保留多模型切换能力,可以通过 API易 apiyi.com 进行统一接口管理、Prompt 对比测试和调用成本观察。
参考资料:
- OpenAI GPT 5.5 Prompt guidance: developers.openai.com/api/docs/guides/prompt-guidance?model=gpt-5.5
- OpenAI Using GPT 5.5: developers.openai.com/api/docs/guides/latest-model
- OpenAI Introducing GPT 5.5: openai.com/index/introducing-gpt-5-5