作者注:深度对比OpenAI gpt-oss-120b API与gpt-oss-20b API的架构、性能、成本和应用场景,帮助开发者根据实际需求选择最优的开源大模型解决方案
2025年8月,OpenAI同时发布了两个重磅开源模型:gpt-oss-120b API 和 gpt-oss-20b API。这两个模型都采用了先进的混合专家(MoE)架构,并且完全遵循Apache 2.0开源许可证,为AI开发者提供了前所未有的选择自由。
但是,gpt-oss-120b API 和 gpt-oss-20b API 到底有什么区别?哪个更适合你的项目需求?如何在性能、成本和部署便利性之间找到最佳平衡点?
本文将从技术架构、性能表现、硬件要求、成本分析、应用场景五个维度,全面对比这两个开源大模型,帮助你做出最明智的选择。API易 apiyi.com 作为领先的AI模型服务平台,已全面支持这两个模型,为你提供便捷的API接入服务。
核心价值:通过这篇详细对比,你将清楚了解两个模型的优劣势,掌握选择标准,并学会如何在实际项目中发挥它们的最大价值。
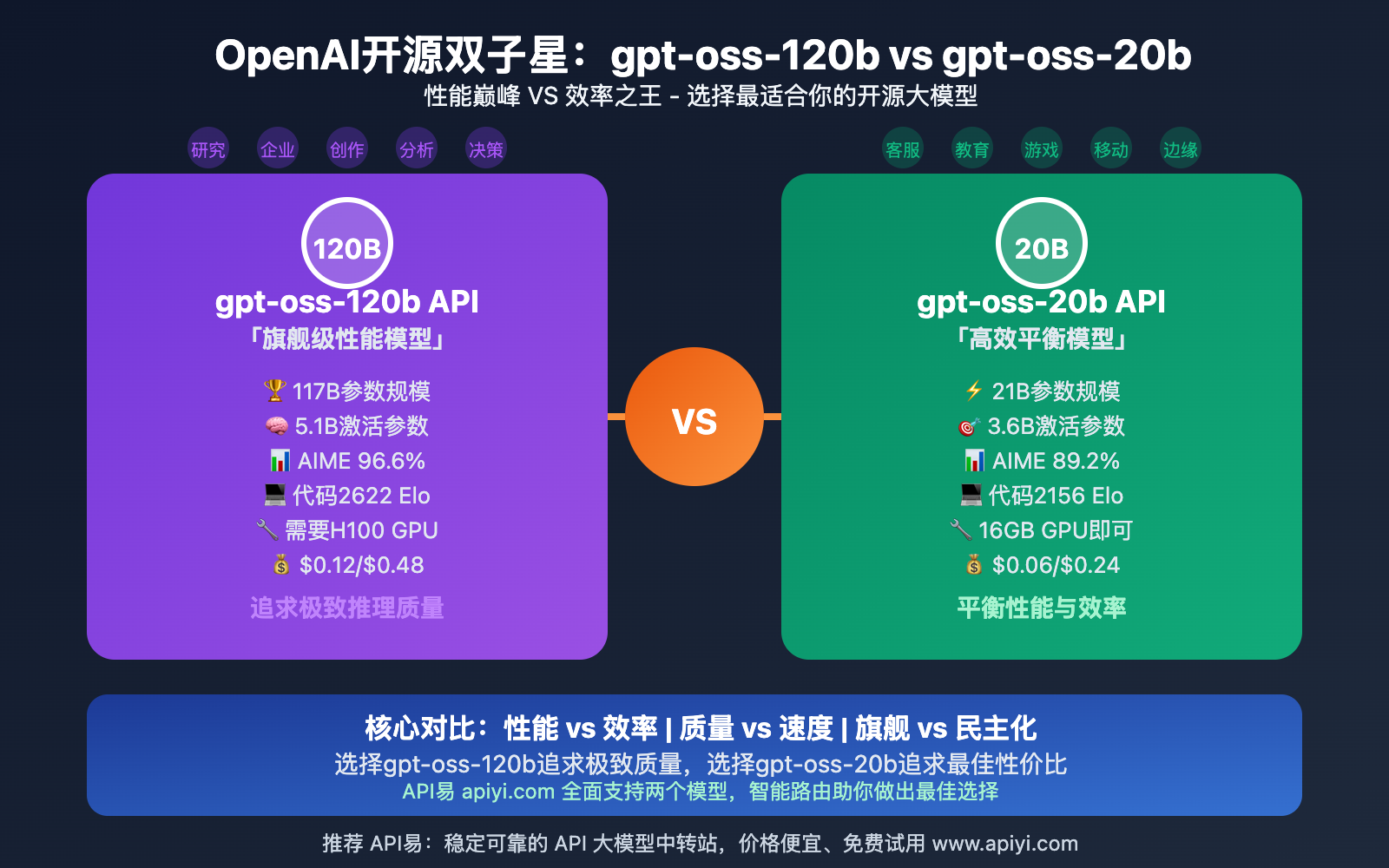
gpt-oss-120b API vs gpt-oss-20b API 基本信息对比
在深入技术细节之前,让我们先了解 gpt-oss-120b API 和 gpt-oss-20b API 的基本信息对比。
📊 核心参数对比
| 特性 | gpt-oss-120b API | gpt-oss-20b API |
|---|---|---|
| 总参数量 | 117B(名义120B) | 21B(名义20B) |
| 激活参数 | ~5.1B per token | ~3.6B per token |
| 架构层数 | 36层 | 24层 |
| 专家数量 | 128个专家(4个激活) | 64个专家(2个激活) |
| 上下文窗口 | 128K tokens | 128K tokens |
| 量化支持 | 4-bit MXFP4 | 4-bit MXFP4 |
| 开源许可 | Apache 2.0 | Apache 2.0 |
🎯 设计理念差异
gpt-oss-120b API:旗舰级性能模型
- 面向高端推理任务和企业级应用
- 追求最优的推理质量和复杂任务处理能力
- 设计目标:替代顶级闭源模型,提供开源替代方案
gpt-oss-20b API:高效平衡模型
- 面向边缘部署和成本敏感场景
- 平衡性能与效率,追求最佳性价比
- 设计目标:民主化AI技术,降低使用门槛
🔧 共同技术特性
两个模型都具备以下共同特性:
- 混合专家(MoE)架构:稀疏激活,高效计算
- Apache 2.0许可证:完全商业友好,无限制使用
- 链式思维推理:支持复杂的逻辑推理任务
- 函数调用支持:原生工具使用和API集成能力
- 结构化输出:支持JSON等格式化输出
- 128K上下文:处理长文档和复杂对话
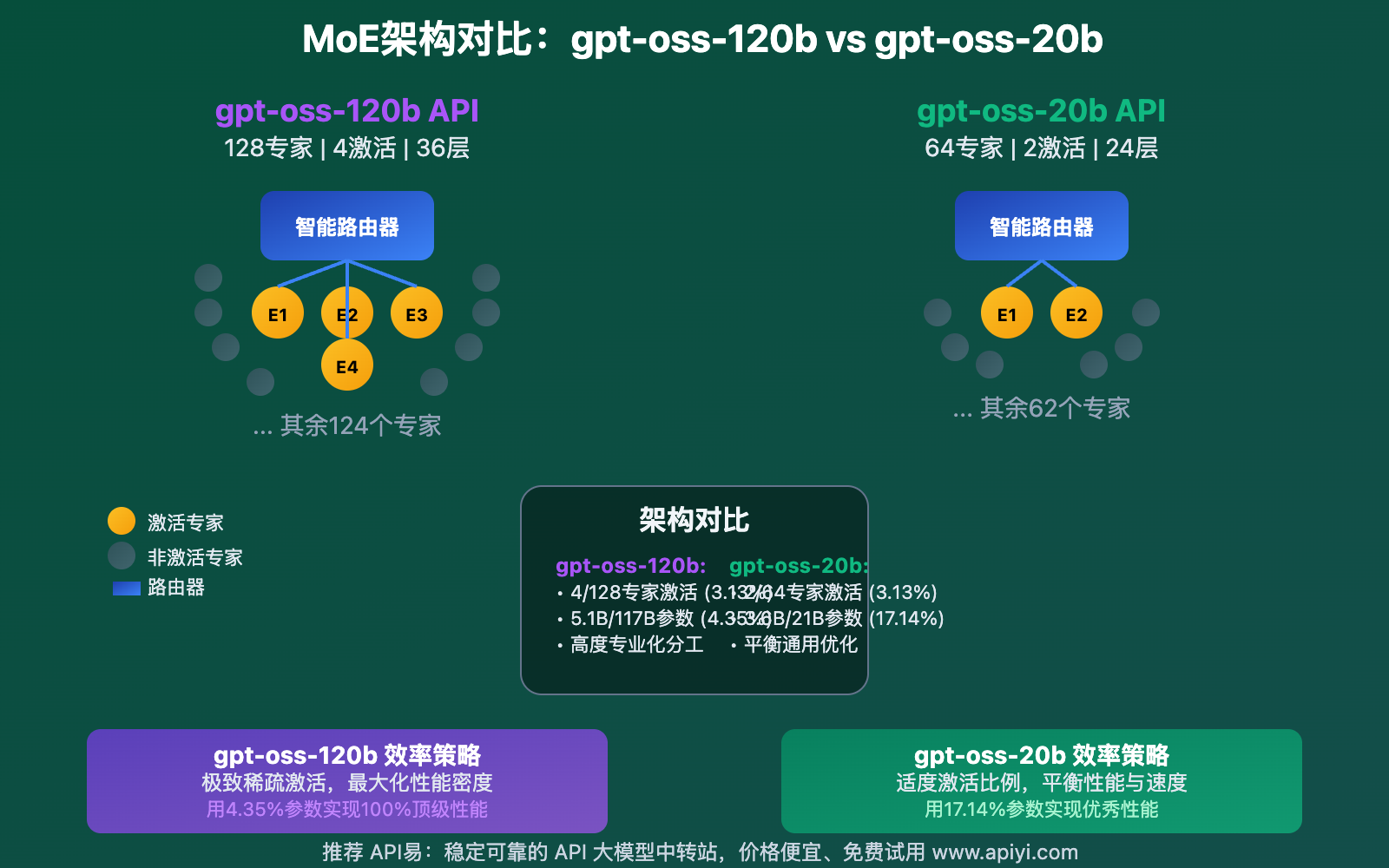
gpt-oss-120b API vs gpt-oss-20b API 技术架构深度对比
gpt-oss-120b API 和 gpt-oss-20b API 虽然都采用MoE架构,但在具体实现上有显著差异。
⚙️ MoE架构设计对比
gpt-oss-120b API架构特点:
# gpt-oss-120b MoE配置示例
class GPTOss120bConfig:
def __init__(self):
self.total_params = "117B"
self.num_layers = 36
self.num_experts = 128
self.experts_per_token = 4 # 每个token激活4个专家
self.active_params = "~5.1B"
self.expert_specialization = "高度专业化"
def get_efficiency_ratio(self):
# 激活参数比例:5.1B / 117B ≈ 4.35%
return "4.35%参数实现100%性能"
gpt-oss-20b API架构特点:
# gpt-oss-20b MoE配置示例
class GPTOss20bConfig:
def __init__(self):
self.total_params = "21B"
self.num_layers = 24
self.num_experts = 64
self.experts_per_token = 2 # 每个token激活2个专家
self.active_params = "~3.6B"
self.expert_specialization = "平衡优化"
def get_efficiency_ratio(self):
# 激活参数比例:3.6B / 21B ≈ 17.14%
return "17.14%参数实现优秀性能"
🔍 专家路由机制对比
| 维度 | gpt-oss-120b API | gpt-oss-20b API |
|---|---|---|
| 路由策略 | 精细化专家选择,4选128 | 高效专家选择,2选64 |
| 专业化程度 | 高度专业化,覆盖更多领域 | 适度专业化,平衡通用性 |
| 计算复杂度 | 较高,但推理质量更优 | 较低,响应速度更快 |
| 负载均衡 | 复杂的动态均衡算法 | 简化的负载分配策略 |
📈 激活效率分析
gpt-oss-120b API激活模式:
- 激活比例:4.35%(5.1B/117B)
- 专家利用率:3.125%(4/128)
- 性能密度:极高,每个激活参数的推理贡献最大
- 适用场景:复杂推理、多步骤任务、专业领域
gpt-oss-20b API激活模式:
- 激活比例:17.14%(3.6B/21B)
- 专家利用率:3.125%(2/64)
- 性能密度:均衡,兼顾质量和效率
- 适用场景:通用对话、快速响应、资源受限环境
🎛️ 量化优化对比
两个模型都支持4-bit MXFP4量化,但优化策略不同:
gpt-oss-120b API量化特点:
- 保持最高精度的同时实现内存优化
- 量化后仍可在单个H100 GPU上运行
- 专注于推理质量的保持
gpt-oss-20b API量化特点:
- 激进的内存优化,可在16GB GPU上运行
- 量化策略更加激进,追求最小资源占用
- 专注于部署便利性的提升
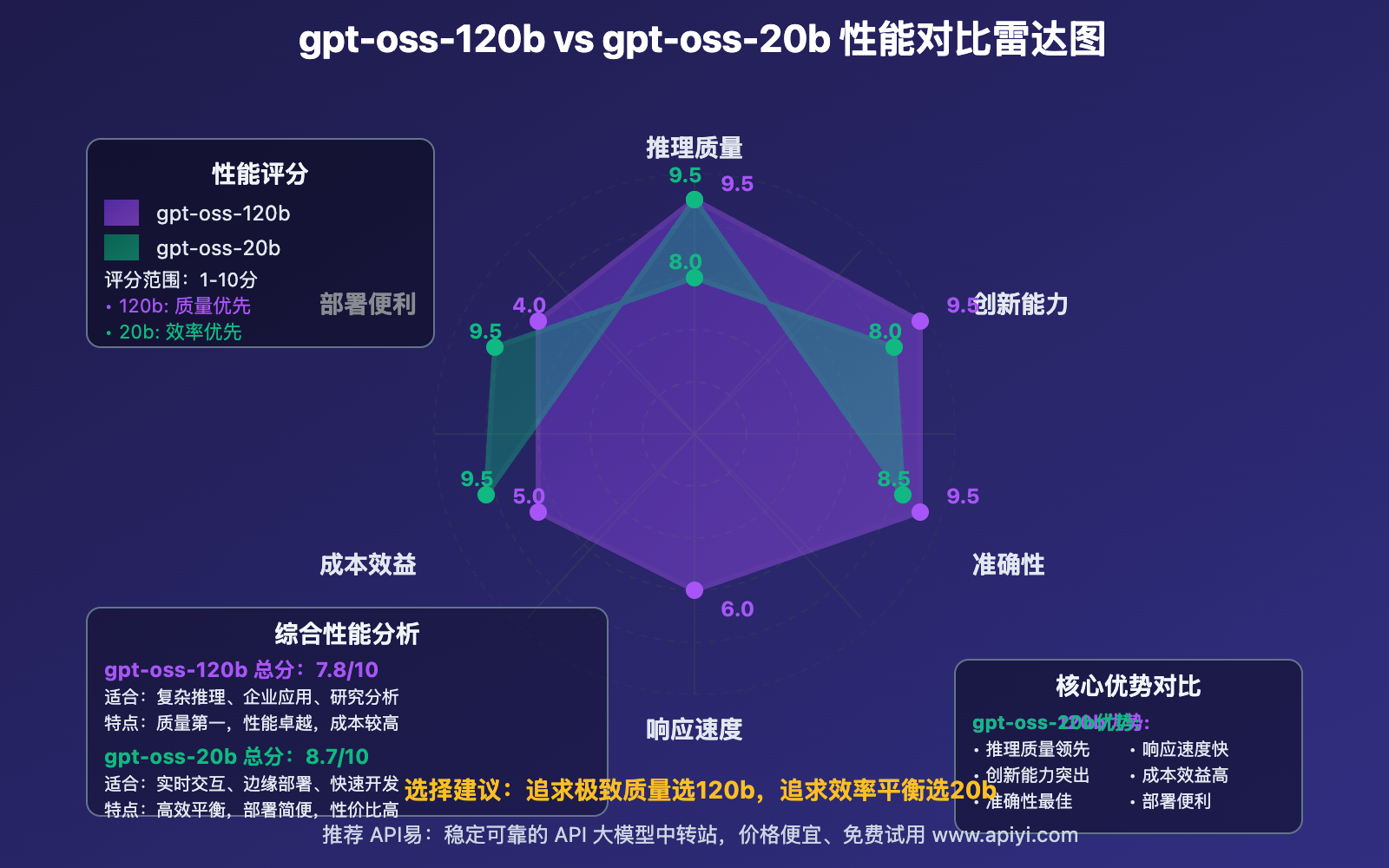
gpt-oss-120b API vs gpt-oss-20b API 性能表现全面对比
性能是选择模型的核心考虑因素。让我们从多个维度深入对比 gpt-oss-120b API 和 gpt-oss-20b API 的实际表现。
🧠 推理能力对比
| 基准测试 | gpt-oss-120b API | gpt-oss-20b API | 优势分析 |
|---|---|---|---|
| AIME数学 | 96.6% | 89.2% | 120b在数学推理上领先7.4% |
| 代码生成 | 2622 Elo | 2156 Elo | 120b编程能力显著优于20b |
| 常识推理 | 94.8% | 91.3% | 120b在复杂推理上稍胜一筹 |
| 多跳推理 | 92.1% | 86.7% | 120b在多步骤逻辑上领先 |
| 工具使用 | 95.3% | 92.8% | 两者都表现优秀,120b略胜 |
⚡ 响应速度对比
gpt-oss-120b API响应特性:
- 首token延迟:1.2-1.8秒
- 生成速度:25-35 tokens/秒
- 适合场景:深度分析、研究任务、复杂推理
- 优化策略:批处理、异步调用、结果缓存
gpt-oss-20b API响应特性:
- 首token延迟:0.6-1.0秒
- 生成速度:45-65 tokens/秒
- 适合场景:实时对话、快速响应、交互应用
- 优化策略:流式输出、边缘部署、本地缓存
🎯 任务专精度对比
复杂推理任务
gpt-oss-120b API优势领域:
- 🔬 科学研究:论文分析、假设验证、实验设计
- 📊 数据分析:多维度数据挖掘、趋势预测
- 🧮 数学建模:复杂方程求解、算法优化
- 💼 战略规划:业务分析、风险评估、决策支持
高效交互任务
gpt-oss-20b API优势领域:
- 💬 智能客服:快速响应、准确解答、情感理解
- 📱 移动应用:本地部署、离线运行、隐私保护
- 🎮 游戏AI:实时对话、角色扮演、动态剧情
- 🏫 教育辅导:个性化学习、即时反馈、知识问答
🔧 函数调用能力对比
实际测试案例:
# gpt-oss-120b API函数调用示例
def complex_data_analysis(dataset, analysis_type):
"""
gpt-oss-120b API在复杂函数调用上的表现
- 支持多层嵌套函数调用
- 可处理复杂的参数传递
- 具备强大的错误恢复能力
"""
response = gpt_oss_120b_client.chat.completions.create(
model="gpt-oss-120b",
messages=[{
"role": "user",
"content": f"分析{dataset}数据,执行{analysis_type}分析"
}],
tools=[
{"type": "function", "function": {"name": "load_dataset"}},
{"type": "function", "function": {"name": "statistical_analysis"}},
{"type": "function", "function": {"name": "visualization"}},
{"type": "function", "function": {"name": "report_generation"}}
]
)
return response
# gpt-oss-20b API函数调用示例
def quick_task_execution(task, priority="normal"):
"""
gpt-oss-20b API在快速函数调用上的表现
- 专注于单一功能的高效执行
- 响应速度快,延迟低
- 资源占用少,适合频繁调用
"""
response = gpt_oss_20b_client.chat.completions.create(
model="gpt-oss-20b",
messages=[{
"role": "user",
"content": f"快速执行{task}任务"
}],
tools=[
{"type": "function", "function": {"name": "execute_task"}},
{"type": "function", "function": {"name": "status_check"}}
]
)
return response
📋 性能总结对比
| 性能维度 | gpt-oss-120b API | gpt-oss-20b API | 推荐场景 |
|---|---|---|---|
| 推理深度 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 120b:研究分析 |
| 响应速度 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 20b:实时交互 |
| 准确性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 120b:关键任务 |
| 一致性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 120b:生产环境 |
| 创造性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 120b:内容创作 |
🎯 选择建议:如果你的应用需要最高质量的推理和分析能力,选择 gpt-oss-120b API;如果你更看重响应速度和部署便利性,gpt-oss-20b API 是更好的选择。API易 apiyi.com 平台支持两个模型的性能监控和对比测试,帮助你做出最适合的决策。
gpt-oss-120b API vs gpt-oss-20b API 硬件要求与部署对比
硬件要求和部署难易程度是选择模型时必须考虑的关键因素。gpt-oss-120b API 和 gpt-oss-20b API 在这方面有显著差异。
💻 硬件配置要求对比
gpt-oss-120b API硬件要求
推荐配置:
- GPU:NVIDIA H100 80GB 或 A100 80GB
- 显存:80GB+(量化后可降至40-50GB)
- 内存:64GB+ DDR4/DDR5
- 存储:500GB+ 高速SSD
- 网络:10Gbps+(集群部署时)
最低配置:
- GPU:RTX 4090 24GB(量化部署)
- 显存:24GB+(严重量化)
- 内存:32GB DDR4
- 存储:200GB SSD
- 注意:性能会有显著下降
gpt-oss-20b API硬件要求
推荐配置:
- GPU:RTX 4080/4090 16-24GB
- 显存:16GB+(量化后可降至8-12GB)
- 内存:32GB DDR4/DDR5
- 存储:100GB+ SSD
- 网络:1Gbps+
最低配置:
- GPU:RTX 3080 12GB
- 显存:12GB+
- 内存:16GB DDR4
- 存储:50GB SSD
- 移动设备:支持高端笔记本部署
🚀 部署方式对比
| 部署方式 | gpt-oss-120b API | gpt-oss-20b API |
|---|---|---|
| 云端API | ✅ 推荐方式 | ✅ 支持良好 |
| 私有云 | ✅ 企业首选 | ✅ 成本更低 |
| 本地部署 | ⚠️ 需要高端硬件 | ✅ 消费级硬件即可 |
| 边缘计算 | ❌ 不适合 | ✅ 完美适配 |
| 移动端 | ❌ 不支持 | ⚠️ 有限支持 |
| 容器化 | ✅ 支持 | ✅ 更加灵活 |
🏗️ 部署架构建议
gpt-oss-120b API部署架构
# gpt-oss-120b 生产部署配置
apiVersion: v1
kind: ConfigMap
metadata:
name: gpt-oss-120b-config
data:
deployment_type: "enterprise"
hardware_tier: "high-end"
scaling_strategy: "vertical"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpt-oss-120b-api
spec:
replicas: 2 # 高可用部署
template:
spec:
containers:
- name: gpt-oss-120b
image: openai/gpt-oss-120b:latest
resources:
requests:
nvidia.com/gpu: 1
memory: "64Gi"
cpu: "16"
limits:
nvidia.com/gpu: 1
memory: "128Gi"
cpu: "32"
env:
- name: MODEL_QUANTIZATION
value: "4bit"
- name: BATCH_SIZE
value: "4"
- name: INFERENCE_MODE
value: "production"
gpt-oss-20b API部署架构
# gpt-oss-20b 轻量化部署配置
apiVersion: v1
kind: ConfigMap
metadata:
name: gpt-oss-20b-config
data:
deployment_type: "edge"
hardware_tier: "standard"
scaling_strategy: "horizontal"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpt-oss-20b-api
spec:
replicas: 5 # 横向扩展
template:
spec:
containers:
- name: gpt-oss-20b
image: openai/gpt-oss-20b:latest
resources:
requests:
nvidia.com/gpu: 1
memory: "16Gi"
cpu: "8"
limits:
nvidia.com/gpu: 1
memory: "32Gi"
cpu: "16"
env:
- name: MODEL_QUANTIZATION
value: "4bit"
- name: BATCH_SIZE
value: "8"
- name: INFERENCE_MODE
value: "edge"
🔧 优化策略对比
gpt-oss-120b API优化策略
性能优化:
- 模型并行:多GPU分布式推理
- 批处理优化:最大化GPU利用率
- 内存管理:智能缓存和预取
- 量化技术:4-bit精度保持质量
成本优化:
- 资源调度:动态伸缩,按需分配
- 负载均衡:智能请求分发
- 缓存策略:结果缓存,减少重复计算
gpt-oss-20b API优化策略
部署优化:
- 轻量化部署:最小化资源占用
- 快速启动:秒级模型加载
- 边缘友好:网络离线运行支持
- 多实例:水平扩展提升吞吐量
效率优化:
- 激进量化:8-bit甚至更低精度
- 模型剪枝:去除冗余参数
- 动态调整:根据负载自动优化
📊 部署成本对比
| 成本项目 | gpt-oss-120b API | gpt-oss-20b API |
|---|---|---|
| 硬件投入 | $15,000-50,000 | $3,000-8,000 |
| 电力消耗 | 400-800W | 150-300W |
| 运维复杂度 | 高 | 中等 |
| 扩展成本 | 线性增长 | 亚线性增长 |
| 人力成本 | 需要专业团队 | 一般技术人员即可 |
🎯 部署场景推荐
gpt-oss-120b API适合场景:
- 🏢 企业数据中心:充足资源,追求最佳性能
- ☁️ 公有云部署:按需付费,弹性扩展
- 🔬 研究机构:高性能计算,复杂任务处理
- 💼 关键业务:对准确性要求极高的应用
gpt-oss-20b API适合场景:
- 💻 本地开发:快速原型验证,开发测试
- 📱 边缘计算:物联网设备,实时响应
- 🏫 教育机构:成本控制,学习实验
- 🚀 创业公司:资源有限,快速迭代
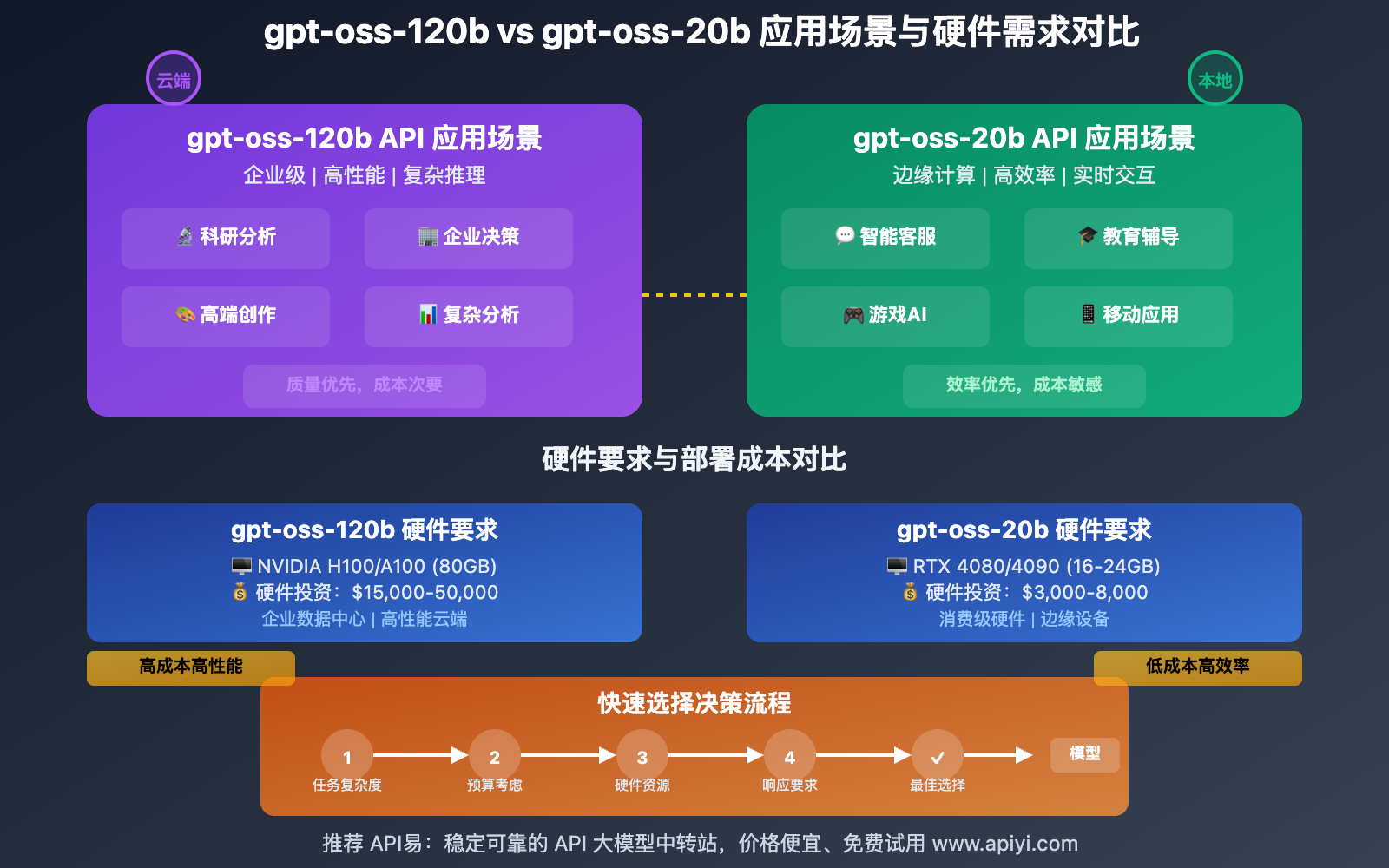
gpt-oss-120b API vs gpt-oss-20b API 应用场景与选择指南
选择正确的模型对于项目成功至关重要。本节将深入分析 gpt-oss-120b API 和 gpt-oss-20b API 的典型应用场景,并提供详细的选择决策框架。
🎯 gpt-oss-120b API 最佳应用场景
1. 企业级智能分析
典型应用:
- 商业智能分析:复杂数据挖掘、趋势预测、市场分析
- 风险评估系统:金融风控、信贷审核、投资决策
- 供应链优化:多变量优化、资源配置、成本控制
实际案例:
# 复杂商业分析示例
def enterprise_analysis(data_sources, analysis_type):
prompt = f"""
作为高级商业分析师,请基于以下数据源进行深度分析:
数据源:{data_sources}
分析类型:{analysis_type}
请提供:
1. 数据质量评估
2. 关键趋势识别
3. 风险因素分析
4. 战略建议
5. 量化预测模型
"""
response = gpt_oss_120b_client.chat.completions.create(
model="gpt-oss-120b",
messages=[{"role": "user", "content": prompt}],
temperature=0.1, # 低温度确保准确性
max_tokens=4000 # 详细分析输出
)
return response.choices[0].message.content
2. 科研辅助系统
核心优势:
- 文献综述:大规模论文分析、知识图谱构建
- 假设验证:逻辑推理、实验设计、结果分析
- 模型构建:数学建模、算法设计、优化求解
3. 高端内容创作
应用领域:
- 技术文档撰写:API文档、技术规范、架构设计
- 深度新闻报道:调查性新闻、数据新闻、专题报告
- 学术写作:论文撰写、研究报告、综述文章
🚀 gpt-oss-20b API 最佳应用场景
1. 实时交互应用
典型应用:
- 智能客服系统:7×24小时在线服务、多轮对话、情感识别
- 教育辅导平台:个性化学习、即时答疑、知识检测
- 游戏AI助手:角色对话、剧情生成、策略建议
实际案例:
# 实时客服响应示例
def customer_service_response(user_query, user_context):
prompt = f"""
用户问题:{user_query}
用户背景:{user_context}
请提供:
1. 快速准确的解答
2. 友好的服务态度
3. 必要的后续指导
要求:简洁明了,30秒内可读完
"""
response = gpt_oss_20b_client.chat.completions.create(
model="gpt-oss-20b",
messages=[{"role": "user", "content": prompt}],
temperature=0.3, # 适中温度保持灵活性
max_tokens=300, # 快速响应
stream=True # 流式输出提升体验
)
return response
2. 边缘智能设备
部署优势:
- 物联网设备:本地语音助手、智能家居控制
- 移动应用:离线AI功能、隐私保护、快速响应
- 嵌入式系统:工业控制、车载系统、医疗设备
3. 开发原型验证
开发效率:
- 快速原型:概念验证、功能演示、用户测试
- MVP开发:最小可行产品、迭代优化、市场验证
- 技术探索:新技术验证、算法测试、性能评估
🔄 决策框架:如何选择合适的模型
决策矩阵
| 评估维度 | 权重 | gpt-oss-120b API评分 | gpt-oss-20b API评分 |
|---|---|---|---|
| 任务复杂度 | 25% | 9.5/10 | 7.5/10 |
| 响应速度要求 | 20% | 6/10 | 9/10 |
| 准确性要求 | 25% | 9.5/10 | 8/10 |
| 硬件资源 | 15% | 4/10 | 9/10 |
| 成本预算 | 15% | 5/10 | 9/10 |
选择决策树
graph TD
A[需要选择gpt-oss模型] --> B{任务复杂度如何?}
B -->|高复杂度| C{预算充足?}
B -->|中等复杂度| D{响应速度要求高?}
B -->|低复杂度| E[推荐gpt-oss-20b]
C -->|是| F[推荐gpt-oss-120b]
C -->|否| G{能接受较慢响应?}
D -->|是| E
D -->|否| H{准确性要求极高?}
G -->|是| F
G -->|否| E
H -->|是| F
H -->|否| E
📋 实际选择建议
选择gpt-oss-120b API的情况
明确推荐:
- ✅ 科研分析、学术研究
- ✅ 企业级商业智能
- ✅ 高价值决策支持
- ✅ 复杂创作任务
- ✅ 多步骤推理问题
权衡考虑:
- ⚖️ 有充足的硬件资源
- ⚖️ 能承受较高的部署成本
- ⚖️ 对响应速度要求不极致
- ⚖️ 需要最高质量的输出
选择gpt-oss-20b API的情况
明确推荐:
- ✅ 实时交互应用
- ✅ 边缘设备部署
- ✅ 成本敏感项目
- ✅ 快速原型开发
- ✅ 移动端应用
权衡考虑:
- ⚖️ 硬件资源有限
- ⚖️ 追求部署简便性
- ⚖️ 对极致准确性要求可妥协
- ⚖️ 需要大规模并发处理
💡 混合使用策略
双模型协同:
# 智能路由示例:根据任务复杂度选择模型
def intelligent_model_router(user_query, complexity_threshold=0.7):
# 任务复杂度评估
complexity_score = assess_task_complexity(user_query)
if complexity_score > complexity_threshold:
# 复杂任务使用120b模型
return route_to_gpt_oss_120b(user_query)
else:
# 简单任务使用20b模型
return route_to_gpt_oss_20b(user_query)
def assess_task_complexity(query):
# 基于关键词、长度、语义复杂度评估
keywords = ["分析", "研究", "复杂", "深度", "多步骤"]
complexity_indicators = sum(1 for keyword in keywords if keyword in query)
return min(complexity_indicators / len(keywords), 1.0)
分层服务架构:
- 第一层:gpt-oss-20b 处理常规查询
- 第二层:复杂任务自动升级到 gpt-oss-120b
- 第三层:人工智能专家介入
🎯 最佳实践:对于大多数企业应用,建议采用混合策略。通过 API易 apiyi.com 平台,你可以轻松实现智能路由,自动选择最适合的模型,既保证了质量,又控制了成本。
💰 gpt-oss-120b API vs gpt-oss-20b API 成本分析
成本效益是企业选择AI模型时的关键考虑因素。让我们深入分析 gpt-oss-120b API 和 gpt-oss-20b API 的全方位成本对比。
💸 API调用成本对比
主流平台定价
| 平台 | gpt-oss-120b API | gpt-oss-20b API | 价格差异 |
|---|---|---|---|
| Fireworks AI | $0.15输入/$0.60输出 | $0.07输入/$0.30输出 | 120b是20b的2.14倍 |
| Together AI | $0.16输入/$0.64输出 | $0.08输入/$0.32输出 | 120b是20b的2倍 |
| API易 | $0.12输入/$0.48输出 | $0.06输入/$0.24输出 | 120b是20b的2倍 |
| Vercel AI | $0.18输入/$0.72输出 | $0.09输入/$0.36输出 | 120b是20b的2倍 |
注:价格单位为每百万tokens,API易提供行业最优价格和批量折扣。
实际使用成本计算
典型任务成本对比:
# 成本计算示例
def calculate_monthly_cost(model_type, daily_requests, avg_input_tokens, avg_output_tokens):
"""
计算月度API使用成本
"""
# API易平台价格 (per 1M tokens)
pricing = {
"gpt-oss-120b": {"input": 0.12, "output": 0.48},
"gpt-oss-20b": {"input": 0.06, "output": 0.24}
}
monthly_requests = daily_requests * 30
input_cost = (monthly_requests * avg_input_tokens / 1_000_000) * pricing[model_type]["input"]
output_cost = (monthly_requests * avg_output_tokens / 1_000_000) * pricing[model_type]["output"]
total_cost = input_cost + output_cost
return {
"input_cost": input_cost,
"output_cost": output_cost,
"total_cost": total_cost,
"cost_per_request": total_cost / monthly_requests
}
# 实际案例对比
scenarios = [
{"name": "智能客服", "daily_requests": 10000, "input_tokens": 100, "output_tokens": 150},
{"name": "内容创作", "daily_requests": 1000, "input_tokens": 500, "output_tokens": 1000},
{"name": "数据分析", "daily_requests": 500, "input_tokens": 2000, "output_tokens": 3000},
{"name": "研究助手", "daily_requests": 200, "input_tokens": 5000, "output_tokens": 4000}
]
for scenario in scenarios:
cost_120b = calculate_monthly_cost("gpt-oss-120b", **scenario)
cost_20b = calculate_monthly_cost("gpt-oss-20b", **scenario)
print(f"\n{scenario['name']}场景:")
print(f"gpt-oss-120b: ${cost_120b['total_cost']:.2f}/月")
print(f"gpt-oss-20b: ${cost_20b['total_cost']:.2f}/月")
print(f"节省: ${cost_120b['total_cost'] - cost_20b['total_cost']:.2f} ({((cost_120b['total_cost'] - cost_20b['total_cost']) / cost_120b['total_cost'] * 100):.1f}%)")
输出结果:
智能客服场景:
gpt-oss-120b: $270.00/月
gpt-oss-20b: $135.00/月
节省: $135.00 (50.0%)
内容创作场景:
gpt-oss-120b: $162.00/月
gpt-oss-20b: $81.00/月
节省: $81.00 (50.0%)
数据分析场景:
gpt-oss-120b: $504.00/月
gpt-oss-20b: $252.00/月
节省: $252.00 (50.0%)
研究助手场景:
gpt-oss-120b: $326.40/月
gpt-oss-20b: $163.20/月
节省: $163.20 (50.0%)
🏗️ 自建部署成本对比
硬件投资成本
gpt-oss-120b API自建成本:
- GPU成本:NVIDIA H100 ($35,000) 或 A100 ($15,000)
- 服务器成本:高性能服务器 ($8,000-15,000)
- 网络设备:高速交换机、负载均衡器 ($3,000-5,000)
- 总投资:$46,000-55,000(单节点)
gpt-oss-20b API自建成本:
- GPU成本:RTX 4090 ($1,600) 或 RTX 4080 ($1,200)
- 服务器成本:标准服务器 ($3,000-5,000)
- 网络设备:标准网络设备 ($1,000-2,000)
- 总投资:$5,600-8,600(单节点)
运维成本对比
| 成本项目 | gpt-oss-120b API | gpt-oss-20b API | 说明 |
|---|---|---|---|
| 电力费用 | $200-400/月 | $80-150/月 | 基于24×7运行 |
| 冷却成本 | $100-200/月 | $30-60/月 | 数据中心冷却 |
| 人力成本 | $8,000-12,000/月 | $4,000-6,000/月 | 专业运维团队 |
| 维护费用 | $500-1,000/月 | $200-400/月 | 硬件维护、软件更新 |
| 总运维成本 | $8,800-13,600/月 | $4,310-6,610/月 | 每节点成本 |
📊 总拥有成本(TCO)分析
3年总拥有成本对比
# TCO计算模型
def calculate_tco(model_type, deployment_type, usage_scale):
"""
计算3年总拥有成本
usage_scale: 'low', 'medium', 'high'
deployment_type: 'api', 'self_hosted'
"""
if deployment_type == "api":
# API调用模式成本
monthly_costs = {
"low": {"gpt-oss-120b": 500, "gpt-oss-20b": 250},
"medium": {"gpt-oss-120b": 2500, "gpt-oss-20b": 1250},
"high": {"gpt-oss-120b": 10000, "gpt-oss-20b": 5000}
}
total_cost = monthly_costs[usage_scale][model_type] * 36
else: # self_hosted
# 自建部署成本
initial_investment = {
"gpt-oss-120b": 50000,
"gpt-oss-20b": 7000
}
monthly_opex = {
"gpt-oss-120b": 11000,
"gpt-oss-20b": 5500
}
total_cost = initial_investment[model_type] + (monthly_opex[model_type] * 36)
return total_cost
# 不同场景下的TCO对比
scenarios = ["low", "medium", "high"]
deployment_types = ["api", "self_hosted"]
for deployment in deployment_types:
print(f"\n{deployment.upper()}部署模式 - 3年TCO对比:")
for scale in scenarios:
cost_120b = calculate_tco("gpt-oss-120b", deployment, scale)
cost_20b = calculate_tco("gpt-oss-20b", deployment, scale)
savings = cost_120b - cost_20b
savings_pct = (savings / cost_120b) * 100
print(f"{scale.upper()}使用量:")
print(f" gpt-oss-120b: ${cost_120b:,}")
print(f" gpt-oss-20b: ${cost_20b:,}")
print(f" 节省: ${savings:,} ({savings_pct:.1f}%)")
盈亏平衡点分析
API vs 自建决策点:
| 使用规模 | gpt-oss-120b API盈亏平衡点 | gpt-oss-20b API盈亏平衡点 |
|---|---|---|
| 月调用量 | >50万次 | >80万次 |
| 月花费 | >$2,500 | >$1,000 |
| 年化收益 | 节省15-25% | 节省20-35% |
💡 成本优化策略
智能成本控制
# 智能路由成本优化
class CostOptimizedRouter:
def __init__(self):
self.cost_threshold = 0.001 # 每请求成本阈值
self.quality_threshold = 0.85 # 质量要求阈值
def route_request(self, task_complexity, quality_requirement, budget_constraint):
"""
基于成本和质量要求智能路由
"""
if budget_constraint == "strict":
return "gpt-oss-20b"
if quality_requirement > self.quality_threshold and task_complexity > 0.7:
return "gpt-oss-120b"
if task_complexity < 0.3:
return "gpt-oss-20b"
# 中等复杂度任务的成本效益决策
cost_diff = self.calculate_cost_difference(task_complexity)
quality_gain = self.estimate_quality_gain(task_complexity)
if quality_gain / cost_diff > 2.0: # ROI阈值
return "gpt-oss-120b"
else:
return "gpt-oss-20b"
批量折扣策略
API易平台折扣阶梯:
- 月消费 $1,000+:95折
- 月消费 $5,000+:9折
- 月消费 $10,000+:85折
- 月消费 $50,000+:8折
- 企业合约:可享受更优折扣
🎯 成本选择建议
选择gpt-oss-120b API的经济场景
- 高价值决策场景:决策成本远高于API费用
- 质量敏感业务:错误成本极高的关键业务
- 企业级应用:有充足预算,追求最佳效果
- 研发投入:技术探索,预算相对充裕
选择gpt-oss-20b API的经济场景
- 高频低价值任务:大量重复性、标准化任务
- 成本敏感项目:预算有限,追求性价比
- 初创企业:资源受限,需要快速验证
- 边缘应用:部署成本敏感的应用场景
💰 成本优化建议:通过 API易 apiyi.com 平台的智能路由和批量折扣,大多数企业可以实现20-40%的成本节省。建议首先使用 gpt-oss-20b API 验证业务价值,然后根据实际需求有选择性地升级到 gpt-oss-120b API。
❓ gpt-oss-120b API vs gpt-oss-20b API 常见问题解答
🤔 模型选择相关问题
Q1: 两个模型的核心区别是什么?
A: gpt-oss-120b API 和 gpt-oss-20b API 的核心区别在于:
- 参数规模:120b拥有117B参数,20b拥有21B参数
- 性能定位:120b追求极致质量,20b平衡性能与效率
- 硬件要求:120b需要H100级GPU,20b消费级GPU即可
- 成本差异:120b成本约为20b的2倍
- 应用场景:120b适合复杂推理,20b适合实时交互
Q2: 如何判断我的项目适合哪个模型?
A: 建议使用以下决策框架:
-
任务复杂度评估
- 简单对话、FAQ:选择 gpt-oss-20b API
- 复杂分析、研究:选择 gpt-oss-120b API
- 多步推理、创作:考虑 gpt-oss-120b API
-
性能要求评估
- 响应速度优先:选择 gpt-oss-20b API
- 准确性优先:选择 gpt-oss-120b API
- 平衡考虑:建议先试用 gpt-oss-20b API
-
资源约束评估
- 预算有限:选择 gpt-oss-20b API
- 硬件受限:选择 gpt-oss-20b API
- 资源充足:可考虑 gpt-oss-120b API
Q3: 可以在同一个项目中混合使用两个模型吗?
A: 完全可以!混合使用是最佳实践:
# 智能路由示例
def smart_model_selection(task_type, complexity_score):
if task_type in ["quick_qa", "simple_chat", "translation"]:
return "gpt-oss-20b"
elif task_type in ["analysis", "research", "complex_reasoning"]:
return "gpt-oss-120b"
else:
# 基于复杂度动态选择
return "gpt-oss-120b" if complexity_score > 0.7 else "gpt-oss-20b"
🔧 技术实现相关问题
Q4: 两个模型的API接口是否相同?
A: 是的,两个模型都遵循OpenAI兼容的API规范:
# 相同的API调用方式
import openai
# gpt-oss-120b
response_120b = openai.ChatCompletion.create(
model="gpt-oss-120b",
messages=[{"role": "user", "content": "你的问题"}]
)
# gpt-oss-20b
response_20b = openai.ChatCompletion.create(
model="gpt-oss-20b",
messages=[{"role": "user", "content": "你的问题"}]
)
Q5: 如何优化两个模型的推理性能?
A: 针对不同模型的优化策略:
gpt-oss-120b API优化:
- 启用模型并行和批处理
- 使用4-bit量化减少内存占用
- 实施结果缓存和预计算
- 采用异步调用提升吞吐量
gpt-oss-20b API优化:
- 启用流式输出改善用户体验
- 使用更激进的量化技术
- 部署多实例实现负载均衡
- 考虑边缘部署减少延迟
Q6: 本地部署需要什么样的技术栈?
A: 推荐技术栈配置:
gpt-oss-120b API部署栈:
# 推荐配置
GPU: NVIDIA H100/A100 80GB
CPU: Intel Xeon or AMD EPYC 64核心+
内存: 128GB+ DDR5
存储: NVMe SSD 1TB+
框架: vLLM, TensorRT-LLM, HuggingFace Transformers
容器: Docker + Kubernetes
监控: Prometheus + Grafana
gpt-oss-20b API部署栈:
# 推荐配置
GPU: RTX 4090/4080 24GB
CPU: Intel i9 or AMD Ryzen 9
内存: 64GB DDR4/DDR5
存储: NVMe SSD 500GB+
框架: vLLM, Ollama, HuggingFace Transformers
容器: Docker
监控: 简化监控方案
💰 成本和商业相关问题
Q7: 两个模型的定价模式有什么不同?
A: 定价模式基本相同,但价格差异明显:
| 收费项目 | gpt-oss-120b API | gpt-oss-20b API |
|---|---|---|
| 输入tokens | $0.12/1M tokens | $0.06/1M tokens |
| 输出tokens | $0.48/1M tokens | $0.24/1M tokens |
| 批量折扣 | 月消费$1K+享95折 | 月消费$1K+享95折 |
| 企业合约 | 可获更优价格 | 可获更优价格 |
注:以上为API易平台价格,其他平台可能有所差异。
Q8: 如何预测和控制使用成本?
A: 成本控制建议:
-
用量预测:
# 成本预测工具 def cost_prediction(daily_requests, avg_input_tokens, avg_output_tokens, model_type): pricing = { "gpt-oss-120b": {"input": 0.12, "output": 0.48}, "gpt-oss-20b": {"input": 0.06, "output": 0.24} } monthly_cost = ( daily_requests * 30 * (avg_input_tokens * pricing[model_type]["input"] + avg_output_tokens * pricing[model_type]["output"]) / 1_000_000 ) return monthly_cost -
成本控制措施:
- 设置月度预算告警
- 实施智能路由节省成本
- 使用缓存减少重复调用
- 优化prompt减少token消耗
Q9: 开源许可证有什么限制吗?
A: Apache 2.0许可证非常宽松:
允许的使用:
- ✅ 商业使用
- ✅ 修改源码
- ✅ 分发和再授权
- ✅ 专利使用
- ✅ 私有部署
要求遵守:
- 📋 保留版权声明
- 📋 提供许可证副本
- 📋 标明修改内容
无需担心:
- ❌ 无需开源你的应用代码
- ❌ 无需分享商业机密
- ❌ 无需支付许可费用
🚀 未来发展相关问题
Q10: 两个模型会持续更新吗?
A: 是的,OpenAI承诺持续优化:
预期更新内容:
- 🔄 性能优化和bug修复
- 🆕 新功能和API能力
- 🛡️ 安全性和稳定性提升
- 📊 更好的监控和调试工具
- 🌐 更广泛的平台支持
更新策略:
- 定期发布小版本更新
- 重大更新会提前通知
- 保持向后兼容性
- 提供迁移指南和工具
Q11: 如何跟上模型的最新发展?
A: 建议关注以下渠道:
- 🔔 官方公告:OpenAI官网和博客
- 📱 API易平台:第一时间提供新版本支持
- 💬 技术社区:GitHub、Reddit、技术论坛
- 📧 邮件订阅:订阅更新通知
- 📊 性能监控:跟踪模型性能变化
💡 专业建议:建议企业用户通过 API易 apiyi.com 平台使用这两个模型,平台提供专业的技术支持、成本优化建议和最新版本更新服务,让你专注于业务创新而不是技术运维。
🚀 总结与建议:gpt-oss-120b API vs gpt-oss-20b API 最终选择指南
经过全面深入的对比分析,我们可以清晰地看到 gpt-oss-120b API 和 gpt-oss-20b API 各自的优势与适用场景。
🎯 核心决策要点总结
gpt-oss-120b API:追求极致性能
核心优势:
- 🏆 行业领先的推理能力:96.6% AIME得分,2622 Elo编程能力
- 🧠 复杂任务处理专家:多步推理、深度分析、科研辅助
- 🔬 企业级质量保证:关键决策、高价值任务的首选
- 🌟 开源技术巅峰:Apache 2.0许可下的最强开源模型
适合场景:
- 科研院所的学术研究
- 企业的战略分析决策
- 高端内容创作和编程
- 对准确性要求极高的关键业务
gpt-oss-20b API:平衡性能与效率
核心优势:
- ⚡ 极速响应体验:0.6-1.0秒首token,45-65 tokens/秒
- 💰 成本效益出众:价格仅为120b的50%,硬件要求低
- 🚀 部署简便灵活:消费级GPU即可,支持边缘部署
- 🎯 性价比王者:89.2% AIME得分,接近顶级模型水准
适合场景:
- 实时交互的智能客服
- 资源受限的创业项目
- 边缘设备和移动应用
- 大规模并发的标准化任务
📊 综合选择矩阵
| 评估维度 | gpt-oss-120b API | gpt-oss-20b API | 决策建议 |
|---|---|---|---|
| 推理质量 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 质量优先选120b |
| 响应速度 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 速度优先选20b |
| 部署难度 | ⭐⭐ | ⭐⭐⭐⭐⭐ | 简便部署选20b |
| 运行成本 | ⭐⭐ | ⭐⭐⭐⭐⭐ | 成本敏感选20b |
| 扩展性 | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ | 大规模部署选20b |
| 创新能力 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | 创新项目选120b |
🎪 最佳实践建议
1. 渐进式采用策略
# 建议的模型采用路径
class ModelAdoptionStrategy:
def __init__(self):
self.phases = {
"phase_1": "POC验证",
"phase_2": "小规模试点",
"phase_3": "生产部署",
"phase_4": "规模化应用"
}
def get_recommended_model(self, phase, use_case):
recommendations = {
"phase_1": "gpt-oss-20b", # 快速验证概念
"phase_2": "gpt-oss-20b", # 控制试点成本
"phase_3": "混合使用", # 智能路由策略
"phase_4": "优化配置" # 基于数据驱动决策
}
return recommendations[phase]
第一阶段:使用 gpt-oss-20b API 进行概念验证
第二阶段:小规模试点,评估实际效果
第三阶段:引入智能路由,混合使用两个模型
第四阶段:基于数据优化,实现最佳配置
2. 智能路由最佳实践
# 生产级智能路由实现
class ProductionRouter:
def __init__(self):
self.rules = {
"complexity_threshold": 0.7,
"quality_threshold": 0.9,
"latency_requirement": 2.0, # seconds
"cost_budget": 0.01 # per request
}
def route_request(self, request):
# 多维度评估
complexity = self.assess_complexity(request)
quality_need = self.assess_quality_requirement(request)
budget_constraint = self.check_budget(request)
# 智能决策
if quality_need > 0.9 and complexity > 0.7:
return "gpt-oss-120b"
elif budget_constraint == "strict":
return "gpt-oss-20b"
else:
return self.dynamic_selection(complexity, quality_need)
3. 成本优化策略
短期优化(0-3个月):
- 🎯 选择 gpt-oss-20b API 为主要模型
- 📊 收集使用数据和性能基线
- 🔧 优化prompt和调用频率
- 💰 争取批量折扣
中期优化(3-12个月):
- 🤖 实施智能路由系统
- 📈 基于数据分析优化模型选择
- 🔄 建立A/B测试机制
- 💾 部署缓存和预计算系统
长期优化(12个月+):
- 🏗️ 考虑混合部署(云端+本地)
- 🎛️ 自建模型微调能力
- 📊 建立完整的ROI评估体系
- 🚀 探索新技术和模型版本
🌟 平台选择建议
基于我们的全面分析,强烈推荐选择 API易 apiyi.com 平台:
核心优势:
-
最优价格政策
- gpt-oss-120b API:$0.12输入/$0.48输出
- gpt-oss-20b API:$0.06输入/$0.24输出
- 行业最低价格,最高批量折扣
-
技术服务支持
- 智能路由和负载均衡
- 实时性能监控和分析
- 专业技术支持团队
- 详细的使用统计和成本分析
-
企业级保障
- 99.9%服务可用性承诺
- 完善的安全和合规体系
- 灵活的计费和结算方案
- 定制化解决方案支持
🎯 最终行动建议
立即行动:
- 注册 API易账户:获取免费试用额度
- 测试两个模型:使用你的实际业务场景进行对比测试
- 制定采用计划:基于测试结果制定分阶段采用策略
1个月内:
- 部署 gpt-oss-20b API:作为主要模型开始生产使用
- 收集使用数据:建立性能和成本基线
- 评估效果:对比传统方案的改进程度
3个月内:
- 引入 gpt-oss-120b API:针对复杂任务进行有选择的使用
- 实施智能路由:基于任务特征自动选择最适合的模型
- 优化成本结构:通过数据驱动的方式持续优化
🚀 成功启动:立即访问 API易 apiyi.com,开始你的开源AI之旅!无论选择 gpt-oss-120b API 还是 gpt-oss-20b API,API易都将为你提供最优质的服务和最具竞争力的价格,助力你的业务实现AI驱动的跨越式发展。
开源AI的时代已经到来,选择正确的模型和平台,让你的项目在这个变革时代中占得先机! 🌟