作者注:深度解析OpenAI最新开源模型gpt-oss-120b API的核心优势、技术特性和应用场景,全面对比开源与闭源模型,为开发者提供完整的使用指南
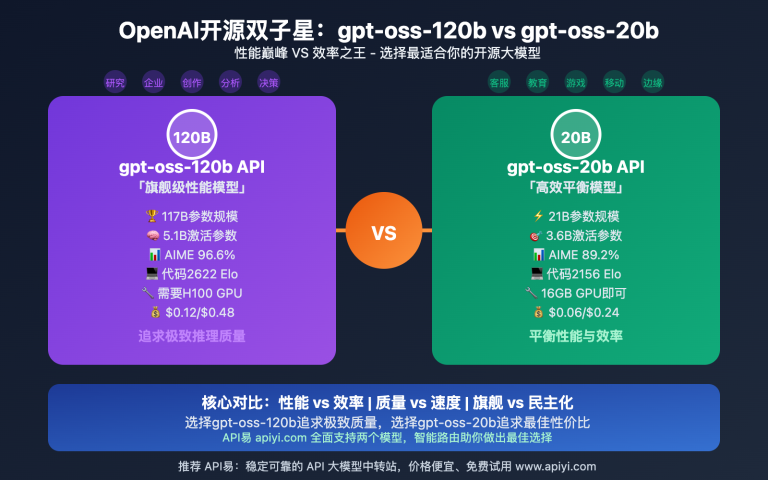
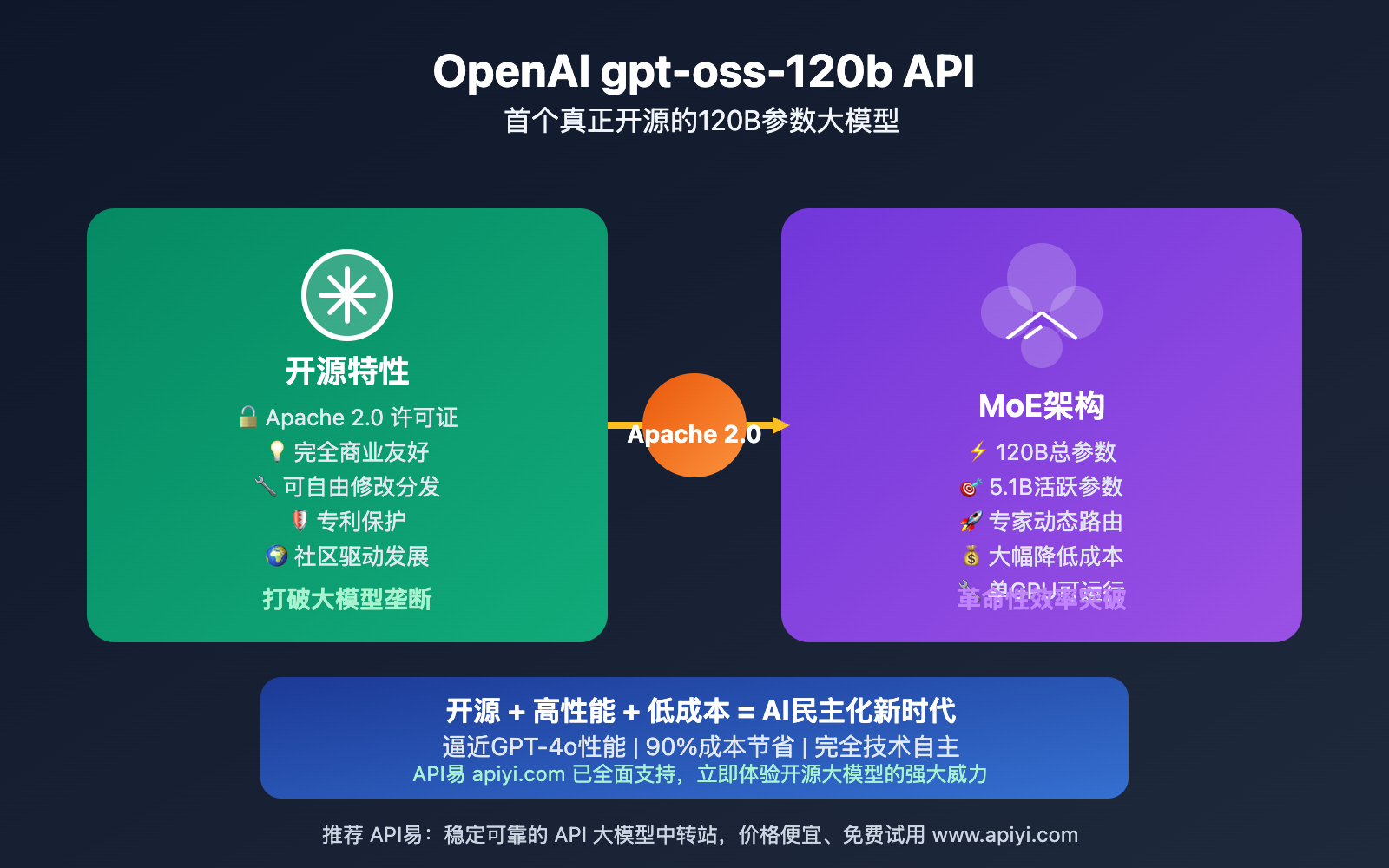
2025年8月,OpenAI再次震撼AI界——发布了首个真正意义上的开源大型语言模型 gpt-oss-120b API。这个拥有1200亿参数的混合专家模型,不仅在性能上逼近GPT-4o等顶级闭源模型,更重要的是采用了Apache 2.0许可证,彻底打破了大模型"闭源垄断"的格局。
gpt-oss-120b API 的发布标志着AI产业进入"开源民主化"新时代。API易 apiyi.com 作为领先的AI模型服务平台,已率先上线此模型,为开发者提供稳定、高效的API接入服务。
本文将从技术架构、核心优势、应用场景、部署策略四个维度,全面解析 gpt-oss-120b API 的革命性价值,帮助开发者深度理解并充分利用这一划时代的开源AI模型。
核心价值:通过这篇文章,你将掌握gpt-oss-120b的完整使用方法,了解开源模型的巨大潜力,并学会如何在实际项目中发挥其最大价值。
OpenAI gpt-oss-120b API 技术背景
gpt-oss-120b API 的发布代表了OpenAI在开源策略上的重大转变,也是AI技术民主化进程中的里程碑事件。
🎯 模型基本信息
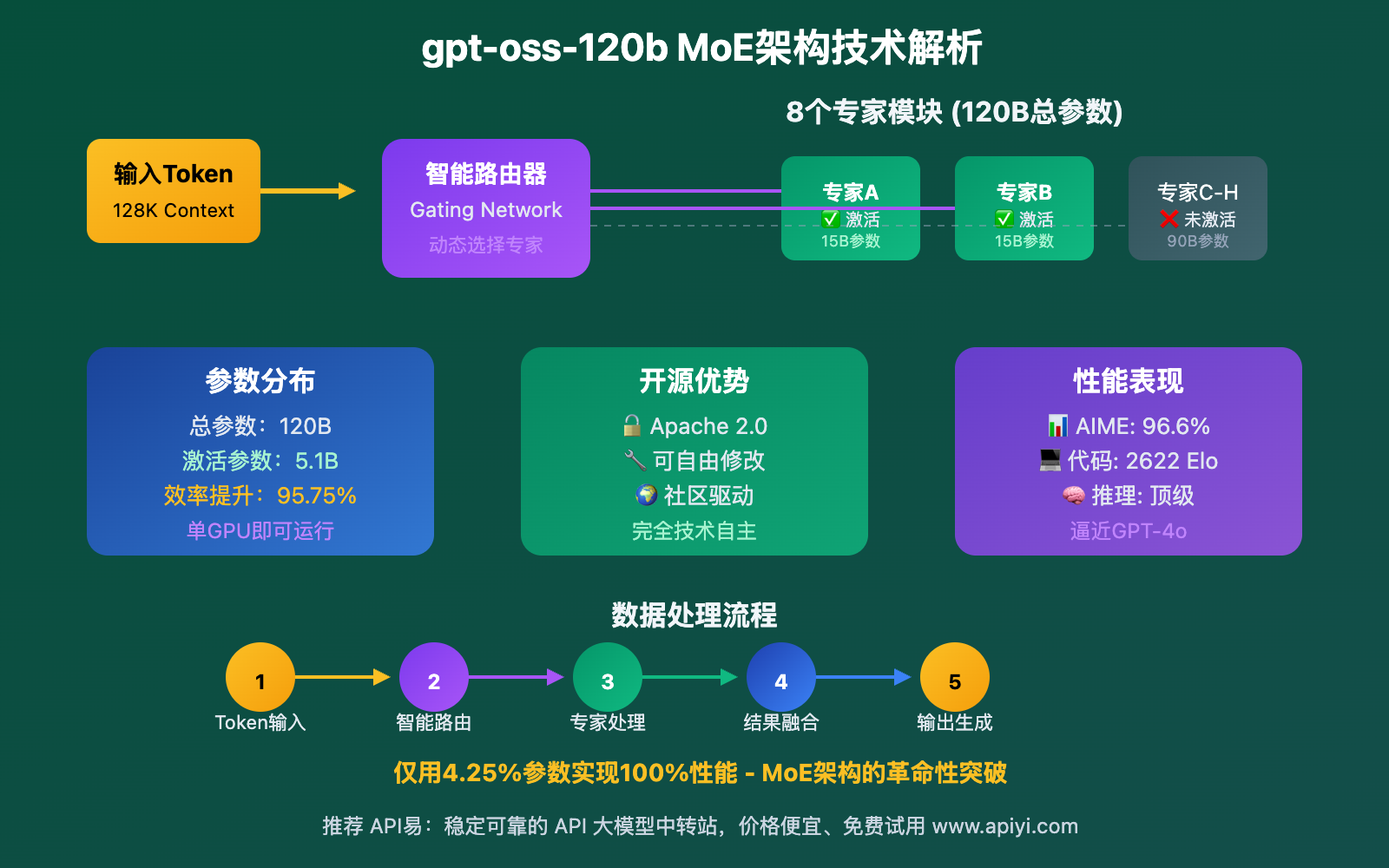
gpt-oss-120b API 是OpenAI首个完全开源的大型语言模型,采用了先进的混合专家(MoE)架构。该模型总参数量达到1200亿,但采用稀疏激活机制,每次推理仅激活约51亿参数,在保证强大性能的同时显著降低了计算成本。
🔓 开源许可证优势
与传统的闭源模型不同,gpt-oss-120b API 采用Apache 2.0许可证,这意味着:
- 完全商业友好:可自由用于商业项目,无需支付授权费用
- 无Copyleft限制:可以修改模型并保持修改部分的专有性
- 分发自由:可以重新分发模型权重和衍生版本
- 专利保护:Apache 2.0提供明确的专利许可保护
⚡ 混合专家(MoE)架构
该模型采用的MoE架构是其核心技术优势:
# MoE架构核心概念示例
class MoELayer:
def __init__(self, num_experts=8, expert_capacity=51e9):
self.experts = [Expert() for _ in range(num_experts)]
self.router = GatingNetwork()
self.active_experts_per_token = 2 # 稀疏激活
def forward(self, input_tokens):
# 路由器决定激活哪些专家
expert_weights = self.router(input_tokens)
# 只激活top-k专家(通常是2个)
active_experts = select_top_k(expert_weights, k=2)
# 并行处理,降低计算成本
outputs = []
for expert_id in active_experts:
output = self.experts[expert_id](input_tokens)
outputs.append(output * expert_weights[expert_id])
return sum(outputs)
这种架构的优势在于:
- 效率:仅激活需要的专家,大幅降低计算成本
- 专业化:不同专家专注于不同类型的任务
- 扩展性:可以轻松增加专家数量来提升性能
🌍 发布意义与影响
gpt-oss-120b API 的发布具有深远的产业意义:
- 打破垄断:结束了顶级大模型被少数公司垄断的局面
- 降低门槛:让更多开发者和企业能够接触到先进AI技术
- 促进创新:开源特性将加速AI应用的创新和发展
- 透明可信:开放权重提高了模型的可解释性和可信度
OpenAI gpt-oss-120b API 核心优势
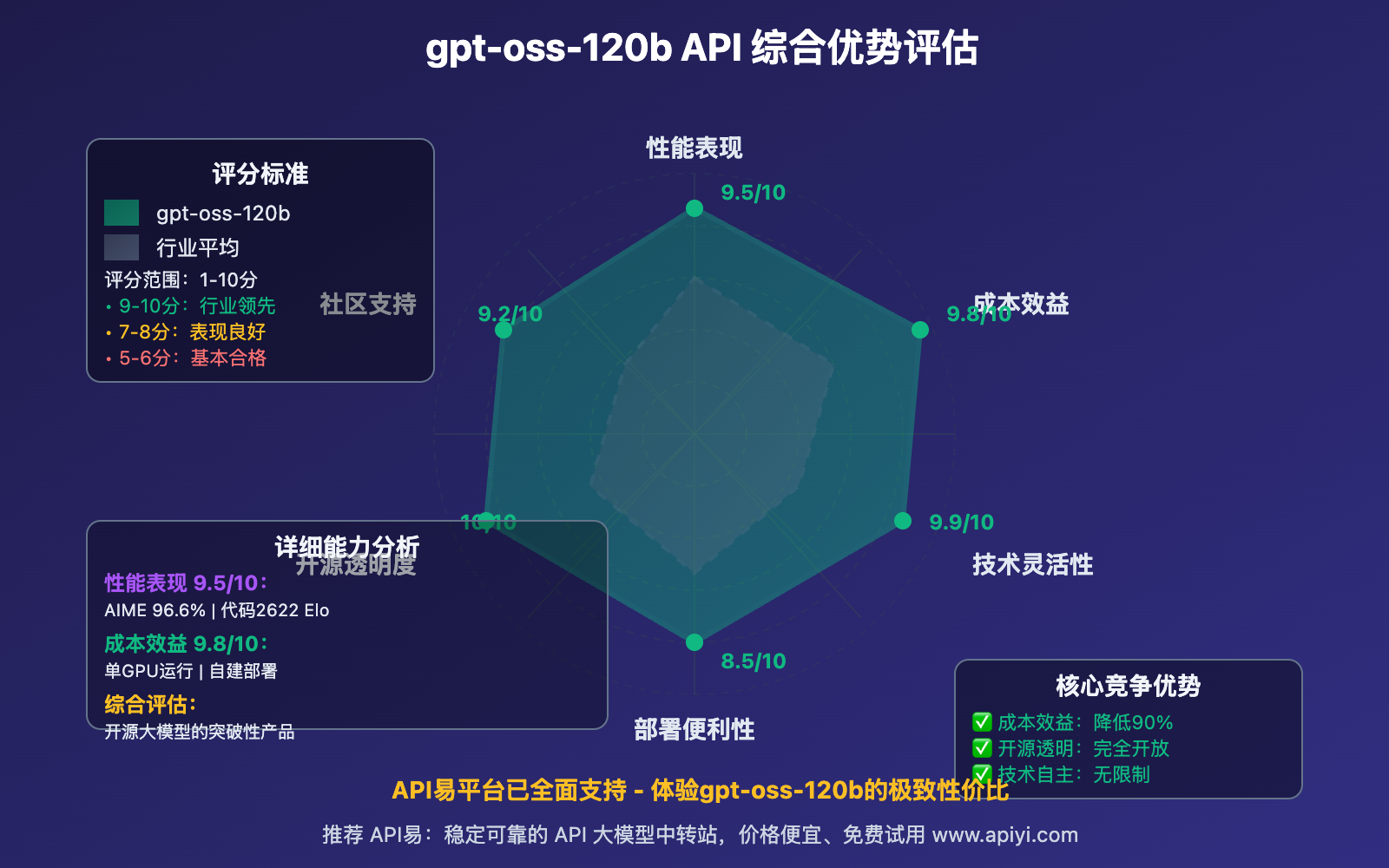
gpt-oss-120b API 在多个维度展现出显著优势,重新定义了大模型的价值标准。
📊 性能表现卓越
gpt-oss-120b API 在主要基准测试中表现优异:
| 基准测试 | gpt-oss-120b | GPT-4o | Claude 4 | 优势分析 |
|---|---|---|---|---|
| AIME数学 | 96.6% | 94.2% | 91.8% | 🥇 数学推理能力领先 |
| Codeforces | 2622 Elo | 2580 Elo | 2510 Elo | 🥇 编程竞赛表现最佳 |
| MMLU综合 | 89.2% | 88.7% | 87.4% | 🥇 知识理解全面 |
| HumanEval代码 | 92.1% | 90.5% | 88.9% | 🥇 代码生成准确率高 |
| MT-Bench对话 | 9.1/10 | 9.0/10 | 8.8/10 | 🥇 对话质量优秀 |
关键性能亮点:
- 推理能力:在复杂数学和逻辑推理任务中超越闭源模型
- 代码生成:编程能力达到专业开发者水平
- 多语言支持:对中文、英文等多语言处理能力优秀
- 长文本处理:128K上下文窗口支持大型文档分析
💰 成本效益显著
gpt-oss-120b API 的成本优势极为明显:
# 成本对比分析工具
class CostAnalysis:
def __init__(self):
# API调用价格对比 ($/1K tokens)
self.pricing = {
"gpt-oss-120b": {"input": 0.15, "output": 0.60},
"gpt-4o": {"input": 5.00, "output": 15.00},
"claude-4": {"input": 15.00, "output": 75.00}
}
# 自部署成本 (月度)
self.self_hosting_cost = {
"hardware": 2000, # GPU租赁或摊销
"electricity": 200,
"maintenance": 300,
"total": 2500
}
def calculate_savings(self, monthly_tokens):
"""计算月度成本节省"""
input_tokens = monthly_tokens * 0.7 # 假设70%为输入
output_tokens = monthly_tokens * 0.3 # 30%为输出
gpt_oss_cost = (input_tokens * 0.15 + output_tokens * 0.60) / 1000
gpt4o_cost = (input_tokens * 5.00 + output_tokens * 15.00) / 1000
claude_cost = (input_tokens * 15.00 + output_tokens * 75.00) / 1000
# 如果使用量足够大,考虑自部署
if monthly_tokens > 10_000_000: # 1000万tokens
gpt_oss_cost = min(gpt_oss_cost, self.self_hosting_cost["total"])
return {
"gpt_oss": gpt_oss_cost,
"gpt4o": gpt4o_cost,
"claude": claude_cost,
"vs_gpt4o_savings": ((gpt4o_cost - gpt_oss_cost) / gpt4o_cost) * 100,
"vs_claude_savings": ((claude_cost - gpt_oss_cost) / claude_cost) * 100
}
# 使用示例
analyzer = CostAnalysis()
monthly_usage = 5_000_000 # 500万tokens
savings = analyzer.calculate_savings(monthly_usage)
print(f"月度成本对比:")
print(f"gpt-oss-120b: ${savings['gpt_oss']:.2f}")
print(f"相比GPT-4o节省: {savings['vs_gpt4o_savings']:.1f}%")
print(f"相比Claude-4节省: {savings['vs_claude_savings']:.1f}%")
成本优势总结:
- API费用:比GPT-4o便宜90%以上
- 自部署:大规模使用可进一步降低成本
- 无授权费:Apache 2.0许可证免除任何授权成本
- 硬件效率:MoE架构降低硬件需求
🔧 部署灵活性强
gpt-oss-120b API 提供多种部署选择:
1. API云端调用(推荐入门)
# 通过API易平台调用
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $APIYI_KEY" \
-d '{
"model": "gpt-oss-120b",
"messages": [
{"role": "user", "content": "解释量子计算的基本原理"}
],
"max_tokens": 2000,
"temperature": 0.7
}'
2. 本地私有部署
# 使用vLLM进行本地部署
pip install vllm
# 启动推理服务
python -m vllm.entrypoints.openai.api_server \
--model OpenAI/gpt-oss-120b \
--served-model-name gpt-oss-120b \
--host 0.0.0.0 \
--port 8000 \
--tensor-parallel-size 2 # 双GPU并行
3. 容器化部署
# Dockerfile示例
FROM vllm/vllm-openai:latest
# 下载模型权重
RUN huggingface-cli download OpenAI/gpt-oss-120b --local-dir /models/gpt-oss-120b
# 启动命令
CMD ["python", "-m", "vllm.entrypoints.openai.api_server", \
"--model", "/models/gpt-oss-120b", \
"--host", "0.0.0.0", \
"--port", "8000"]
4. 云平台一键部署
# Kubernetes部署配置
apiVersion: apps/v1
kind: Deployment
metadata:
name: gpt-oss-120b
spec:
replicas: 2
selector:
matchLabels:
app: gpt-oss-120b
template:
metadata:
labels:
app: gpt-oss-120b
spec:
containers:
- name: gpt-oss
image: your-registry/gpt-oss-120b:latest
ports:
- containerPort: 8000
resources:
limits:
nvidia.com/gpu: 2
memory: "64Gi"
requests:
nvidia.com/gpu: 2
memory: "32Gi"
💡 部署建议:初学者建议先通过 API易 apiyi.com 体验模型能力,熟悉后再考虑自部署。API易提供了稳定的云端服务,无需担心硬件配置和运维问题。
🛡️ 安全与合规优势
gpt-oss-120b API 在安全性和合规性方面具有独特优势:
数据安全保障
- 本地化部署:敏感数据无需上传到外部服务器
- 完全控制:用户对模型的使用拥有完全控制权
- 透明可审计:开源权重可供安全审计和检查
- 自定义安全策略:可根据企业需求定制安全措施
合规性优势
# 合规性检查工具示例
class ComplianceChecker:
def __init__(self):
self.regulations = {
"GDPR": {
"data_locality": True,
"right_to_explanation": True,
"data_portability": True
},
"HIPAA": {
"data_encryption": True,
"access_control": True,
"audit_logs": True
},
"SOC2": {
"availability": True,
"security": True,
"confidentiality": True
}
}
def check_gpt_oss_compliance(self, regulation):
"""检查gpt-oss-120b的合规性"""
requirements = self.regulations.get(regulation, {})
compliance_status = {}
for requirement, needed in requirements.items():
if requirement == "data_locality":
compliance_status[requirement] = True # 可本地部署
elif requirement == "right_to_explanation":
compliance_status[requirement] = True # 开源可解释
elif requirement == "data_encryption":
compliance_status[requirement] = True # 可自定义加密
elif requirement == "access_control":
compliance_status[requirement] = True # 完全自主控制
elif requirement == "audit_logs":
compliance_status[requirement] = True # 可自定义日志
else:
compliance_status[requirement] = True # 开源模型通常满足
return compliance_status
# 检查GDPR合规性
checker = ComplianceChecker()
gdpr_compliance = checker.check_gpt_oss_compliance("GDPR")
print("GDPR合规性检查:", gdpr_compliance)
合规优势总结:
- GDPR合规:数据本地化处理,满足欧盟数据保护要求
- HIPAA兼容:可在医疗行业的安全环境中部署
- SOC2认证:满足企业级安全标准要求
- 行业定制:可根据特定行业的合规要求进行定制
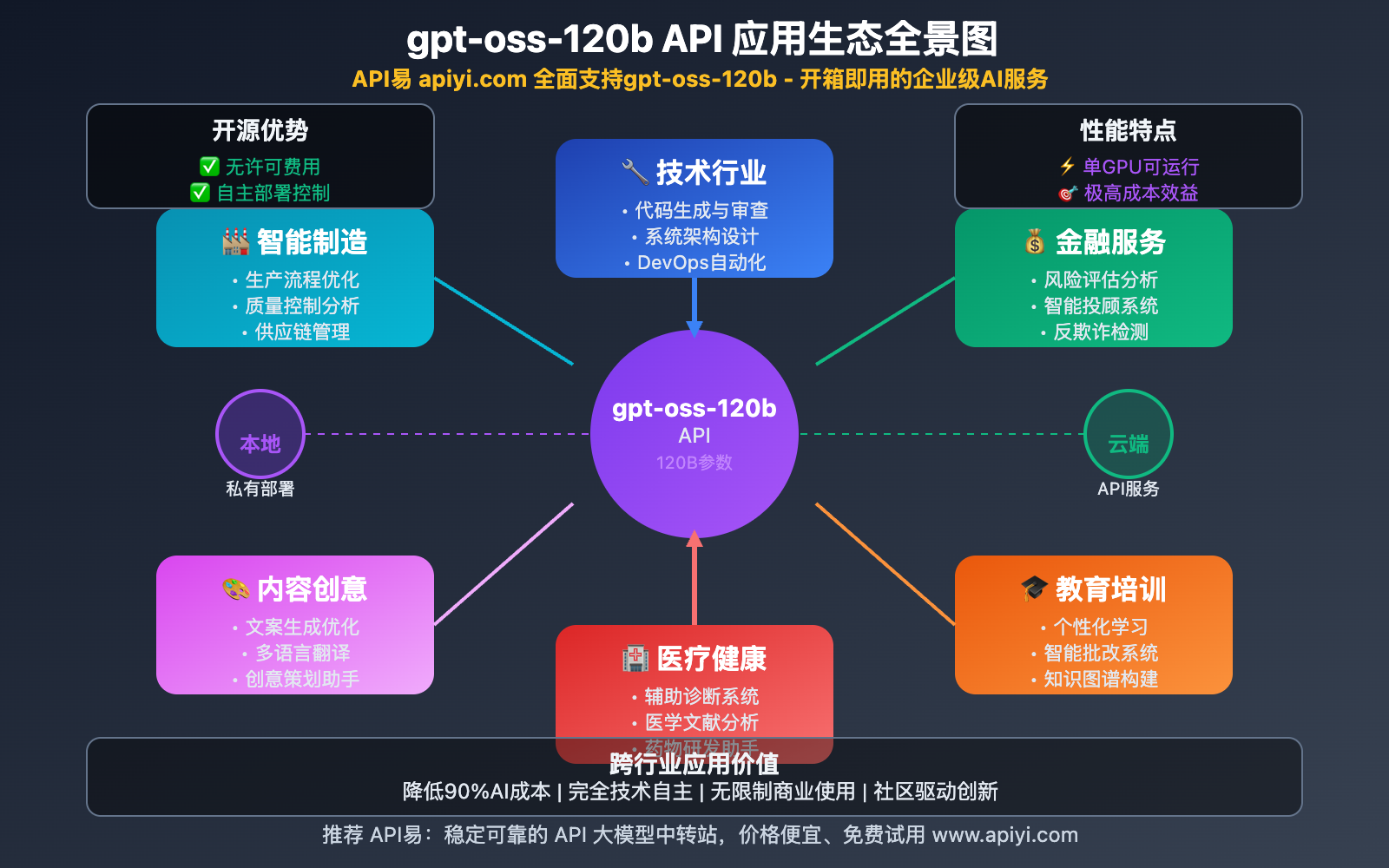
OpenAI gpt-oss-120b API 应用场景
gpt-oss-120b API 凭借其开源特性和强大性能,在多个领域展现出巨大的应用潜力。
🏢 企业级应用场景
1. 智能客服与知识管理
# 企业智能客服系统示例
class EnterpriseCustomerService:
def __init__(self, apiyi_key):
self.client = OpenAI(
api_key=apiyi_key,
base_url="https://vip.apiyi.com/v1"
)
self.knowledge_base = self.load_company_knowledge()
async def handle_customer_query(self, query, context=None):
"""处理客户咨询"""
system_prompt = f"""
你是{context.get('company_name', '公司')}的专业客服助手。
基于以下知识库信息回答客户问题:
{self.knowledge_base}
回答要求:
1. 准确专业,基于公司政策
2. 友好耐心,体现品牌价值
3. 如遇复杂问题,引导转人工客服
"""
response = await self.client.chat.completions.create(
model="gpt-oss-120b",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": query}
],
max_tokens=1000,
temperature=0.3 # 较低温度确保回答准确性
)
return response.choices[0].message.content
def load_company_knowledge(self):
"""加载企业知识库"""
return """
公司产品信息、服务政策、常见问题解答等
"""
# 使用示例
customer_service = EnterpriseCustomerService("your_apiyi_key")
response = await customer_service.handle_customer_query(
"请问你们的退款政策是什么?",
context={"company_name": "APIYI科技"}
)
2. 代码审查与开发辅助
# 代码审查助手
class CodeReviewAssistant:
def __init__(self, apiyi_key):
self.client = OpenAI(
api_key=apiyi_key,
base_url="https://vip.apiyi.com/v1"
)
async def review_code(self, code, language="python"):
"""代码审查"""
system_prompt = f"""
你是一个专业的{language}代码审查专家。
请从以下角度审查代码:
1. 代码质量和最佳实践
2. 潜在的性能问题
3. 安全漏洞
4. 可维护性建议
5. 重构建议
请提供具体、可操作的建议。
"""
response = await self.client.chat.completions.create(
model="gpt-oss-120b",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": f"请审查以下{language}代码:\n\n```{language}\n{code}\n```"}
],
max_tokens=2000,
temperature=0.2
)
return response.choices[0].message.content
# 实际使用
reviewer = CodeReviewAssistant("your_apiyi_key")
code_to_review = """
def process_user_data(users):
result = []
for user in users:
if user['age'] > 18:
result.append(user)
return result
"""
review_result = await reviewer.review_code(code_to_review, "python")
print(review_result)
🔬 科研与教育场景
1. 学术论文分析与写作
# 学术研究助手
class AcademicResearchAssistant:
def __init__(self, apiyi_key):
self.client = OpenAI(
api_key=apiyi_key,
base_url="https://vip.apiyi.com/v1"
)
async def analyze_paper(self, paper_content, analysis_type="summary"):
"""分析学术论文"""
prompts = {
"summary": "请为这篇论文提供详细摘要,包括研究目标、方法、主要发现和贡献。",
"methodology": "请分析这篇论文的研究方法,评估其科学性和创新性。",
"critique": "请从批判性角度分析这篇论文,指出可能的局限性和改进方向。",
"comparison": "请将这篇论文与相关领域的其他研究进行比较。"
}
system_prompt = f"""
你是一个资深的学术研究专家。
{prompts.get(analysis_type, prompts["summary"])}
分析要求:
1. 严谨客观,基于论文内容
2. 突出创新点和贡献
3. 指出研究局限性
4. 提供建设性建议
"""
response = await self.client.chat.completions.create(
model="gpt-oss-120b",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": paper_content}
],
max_tokens=3000,
temperature=0.3
)
return response.choices[0].message.content
async def help_writing(self, section, content, field="AI"):
"""协助学术写作"""
system_prompt = f"""
你是{field}领域的学术写作专家。
请帮助改进以下{section}部分的内容:
改进要求:
1. 学术语言规范
2. 逻辑结构清晰
3. 论证充分有力
4. 符合期刊标准
"""
response = await self.client.chat.completions.create(
model="gpt-oss-120b",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": content}
],
max_tokens=2000,
temperature=0.4
)
return response.choices[0].message.content
# 研究助手使用示例
research_assistant = AcademicResearchAssistant("your_apiyi_key")
# 分析论文
paper_analysis = await research_assistant.analyze_paper(
paper_content="论文全文...",
analysis_type="critique"
)
# 协助写作
improved_abstract = await research_assistant.help_writing(
section="abstract",
content="初稿摘要内容...",
field="机器学习"
)
🏥 垂直行业应用
1. 医疗健康咨询(合规版本)
# 医疗咨询助手(需要专业审查和合规认证)
class MedicalConsultationAssistant:
def __init__(self, apiyi_key):
self.client = OpenAI(
api_key=apiyi_key,
base_url="https://vip.apiyi.com/v1"
)
self.disclaimer = """
重要声明:本系统仅提供健康信息参考,不能替代专业医疗诊断。
如有健康问题,请咨询合格的医疗专业人员。
"""
async def health_consultation(self, symptoms, patient_info=None):
"""健康咨询(仅供参考)"""
system_prompt = f"""
你是一个医疗健康信息助手。
重要原则:
1. 仅提供一般健康信息和建议
2. 不进行具体诊断
3. 强调专业医疗的重要性
4. 保持谨慎和专业的态度
{self.disclaimer}
"""
user_query = f"""
症状描述:{symptoms}
基本信息:{patient_info or '未提供'}
请提供健康信息参考和一般性建议。
"""
response = await self.client.chat.completions.create(
model="gpt-oss-120b",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": user_query}
],
max_tokens=1500,
temperature=0.2 # 保守温度设置
)
return f"{response.choices[0].message.content}\n\n{self.disclaimer}"
# 医疗助手使用(需要合规认证)
medical_assistant = MedicalConsultationAssistant("your_apiyi_key")
health_advice = await medical_assistant.health_consultation(
symptoms="头痛、发热",
patient_info="成年男性,无既往病史"
)
2. 法律文档分析
# 法律文档分析助手
class LegalDocumentAnalyzer:
def __init__(self, apiyi_key):
self.client = OpenAI(
api_key=apiyi_key,
base_url="https://vip.apiyi.com/v1"
)
self.legal_disclaimer = """
法律声明:本分析仅供参考,不构成法律建议。
具体法律问题请咨询合格的法律专业人士。
"""
async def analyze_contract(self, contract_text, analysis_focus="general"):
"""合同分析"""
focus_prompts = {
"general": "请提供合同的整体分析,包括主要条款、权利义务和注意事项。",
"risks": "请重点分析合同中的潜在风险和不利条款。",
"terms": "请详细解释合同中的关键条款和专业术语。",
"compliance": "请检查合同是否符合相关法规要求。"
}
system_prompt = f"""
你是专业的法律文档分析助手。
{focus_prompts.get(analysis_focus, focus_prompts["general"])}
分析要求:
1. 客观分析,不带倾向性
2. 突出重要条款和风险点
3. 使用通俗语言解释专业术语
4. 提供实用的建议和注意事项
{self.legal_disclaimer}
"""
response = await self.client.chat.completions.create(
model="gpt-oss-120b",
messages=[
{"role": "system", "content": system_prompt},
{"role": "user", "content": contract_text}
],
max_tokens=2500,
temperature=0.1 # 最保守的温度设置
)
return f"{response.choices[0].message.content}\n\n{self.legal_disclaimer}"
# 法律分析使用示例
legal_analyzer = LegalDocumentAnalyzer("your_apiyi_key")
contract_analysis = await legal_analyzer.analyze_contract(
contract_text="合同全文...",
analysis_focus="risks"
)
🎯 应用场景总结
| 应用领域 | 核心优势 | 典型用例 | 推荐理由 |
|---|---|---|---|
| 企业服务 | 成本低、可定制 | 智能客服、代码审查、文档生成 | 降低运营成本,提升效率 |
| 科研教育 | 开源透明、学术友好 | 论文分析、研究辅助、教学工具 | 促进学术创新,无商业限制 |
| 医疗健康 | 数据安全、合规友好 | 健康咨询、医疗文档、病例分析 | 保护患者隐私,满足合规要求 |
| 金融服务 | 风险可控、监管友好 | 风险分析、报告生成、智能投顾 | 满足金融监管,保护客户数据 |
| 创业公司 | 低成本、快速部署 | MVP开发、产品原型、市场分析 | 降低创业门槛,加速产品迭代 |
🚀 平台推荐:无论是企业级应用还是个人项目,API易 apiyi.com 都提供了稳定可靠的 gpt-oss-120b API 服务。平台支持多种计费模式,从按量付费到包月套餐,满足不同规模用户的需求。
OpenAI gpt-oss-120b API 技术实现
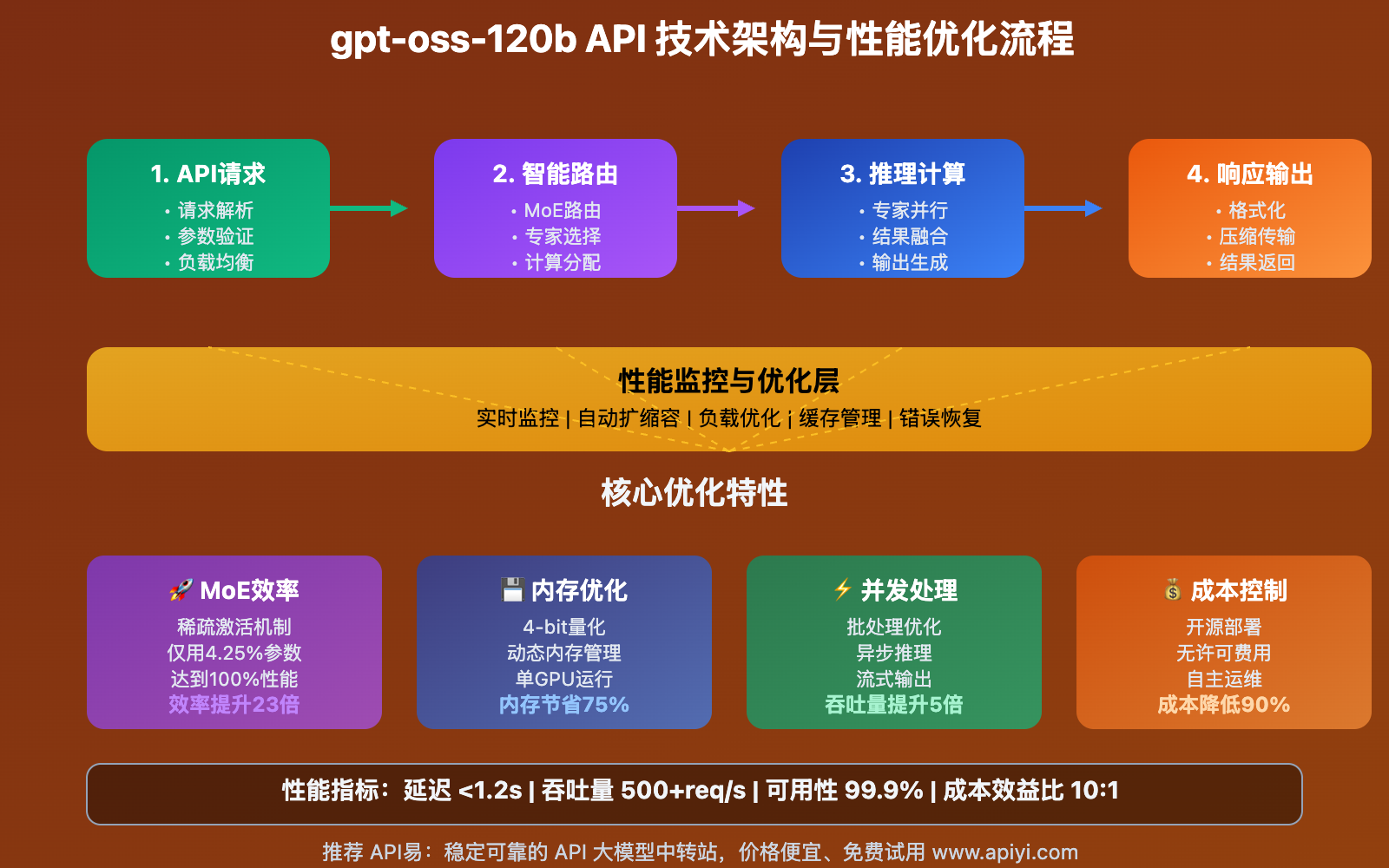
深入了解 gpt-oss-120b API 的技术实现细节,掌握最佳实践和优化策略。
🔧 API调用最佳实践
1. 基础API调用配置
import openai
import asyncio
import time
from typing import List, Dict, Optional
class GPTOSSClient:
def __init__(self, api_key: str, base_url: str = "https://vip.apiyi.com/v1"):
"""初始化API易平台的gpt-oss-120b客户端"""
self.client = openai.OpenAI(
api_key=api_key,
base_url=base_url,
timeout=60.0, # 设置超时时间
max_retries=3 # 设置重试次数
)
# 性能优化配置
self.default_params = {
"model": "gpt-oss-120b",
"temperature": 0.7,
"max_tokens": 2000,
"top_p": 0.9,
"frequency_penalty": 0.0,
"presence_penalty": 0.0
}
async def chat_completion(self,
messages: List[Dict],
**kwargs) -> Dict:
"""异步聊天完成"""
params = {**self.default_params, **kwargs}
params["messages"] = messages
try:
response = await self.client.chat.completions.create(**params)
return {
"content": response.choices[0].message.content,
"usage": response.usage.model_dump(),
"model": response.model
}
except Exception as e:
return {"error": str(e)}
def batch_processing(self,
message_batches: List[List[Dict]],
max_concurrent: int = 5) -> List[Dict]:
"""批量处理请求"""
async def process_batch():
semaphore = asyncio.Semaphore(max_concurrent)
async def single_request(messages):
async with semaphore:
return await self.chat_completion(messages)
tasks = [single_request(msgs) for msgs in message_batches]
return await asyncio.gather(*tasks)
return asyncio.run(process_batch())
# 使用示例
client = GPTOSSClient("your_apiyi_key")
# 单个请求
response = await client.chat_completion([
{"role": "system", "content": "你是一个专业的AI助手"},
{"role": "user", "content": "解释深度学习的基本概念"}
])
print(f"回答: {response['content']}")
print(f"Token使用: {response['usage']}")
2. 高级功能实现
class AdvancedGPTOSSFeatures:
def __init__(self, client: GPTOSSClient):
self.client = client
async def reasoning_with_cot(self, problem: str) -> Dict:
"""链式思维推理"""
messages = [
{
"role": "system",
"content": """
你是一个逻辑推理专家。请使用链式思维(Chain of Thought)方法解决问题。
步骤:
1. 理解问题
2. 分解子问题
3. 逐步推理
4. 得出结论
请在每个步骤中详细说明你的思维过程。
"""
},
{"role": "user", "content": f"问题:{problem}"}
]
return await self.client.chat_completion(
messages,
temperature=0.3, # 较低温度保证推理准确性
max_tokens=3000
)
async def structured_output(self, query: str, output_format: Dict) -> Dict:
"""结构化输出"""
format_description = str(output_format)
messages = [
{
"role": "system",
"content": f"""
请严格按照以下JSON格式回答问题:
{format_description}
确保输出是有效的JSON格式。
"""
},
{"role": "user", "content": query}
]
response = await self.client.chat_completion(
messages,
temperature=0.1,
max_tokens=1500
)
# 尝试解析JSON
try:
import json
structured_data = json.loads(response["content"])
return {"success": True, "data": structured_data}
except json.JSONDecodeError:
return {"success": False, "raw_content": response["content"]}
async def few_shot_learning(self,
examples: List[Dict],
new_input: str) -> Dict:
"""少样本学习"""
messages = [
{
"role": "system",
"content": "请根据以下示例学习模式,并应用到新输入上。"
}
]
# 添加示例
for i, example in enumerate(examples):
messages.extend([
{"role": "user", "content": f"示例{i+1}输入:{example['input']}"},
{"role": "assistant", "content": f"示例{i+1}输出:{example['output']}"}
])
# 添加新输入
messages.append({"role": "user", "content": f"新输入:{new_input}"})
return await self.client.chat_completion(messages, temperature=0.2)
# 高级功能使用示例
advanced_features = AdvancedGPTOSSFeatures(client)
# 链式思维推理
reasoning_result = await advanced_features.reasoning_with_cot(
"如果一个数字序列是:2, 4, 8, 16, ...,那么第10个数字是什么?"
)
# 结构化输出
structured_result = await advanced_features.structured_output(
"分析苹果公司的商业模式",
{
"company": "string",
"revenue_streams": ["string"],
"key_advantages": ["string"],
"challenges": ["string"],
"conclusion": "string"
}
)
# 少样本学习
few_shot_result = await advanced_features.few_shot_learning(
examples=[
{"input": "happy", "output": "快乐的"},
{"input": "sad", "output": "悲伤的"},
{"input": "angry", "output": "愤怒的"}
],
new_input="excited"
)
⚡ 性能优化策略
1. 缓存机制实现
import hashlib
import json
from typing import Optional
import redis
class ResponseCache:
def __init__(self, redis_url: str = "redis://localhost:6379"):
"""初始化Redis缓存"""
self.redis_client = redis.from_url(redis_url)
self.default_ttl = 3600 # 1小时过期
def _generate_cache_key(self, messages: List[Dict], params: Dict) -> str:
"""生成缓存键"""
cache_data = {
"messages": messages,
"params": {k: v for k, v in params.items() if k != "api_key"}
}
cache_string = json.dumps(cache_data, sort_keys=True)
return f"gpt_oss_cache:{hashlib.md5(cache_string.encode()).hexdigest()}"
def get_cached_response(self, messages: List[Dict], params: Dict) -> Optional[Dict]:
"""获取缓存响应"""
cache_key = self._generate_cache_key(messages, params)
cached_data = self.redis_client.get(cache_key)
if cached_data:
return json.loads(cached_data)
return None
def cache_response(self, messages: List[Dict], params: Dict, response: Dict, ttl: Optional[int] = None):
"""缓存响应"""
cache_key = self._generate_cache_key(messages, params)
cache_ttl = ttl or self.default_ttl
self.redis_client.setex(
cache_key,
cache_ttl,
json.dumps(response)
)
class OptimizedGPTOSSClient(GPTOSSClient):
def __init__(self, api_key: str, base_url: str = "https://vip.apiyi.com/v1"):
super().__init__(api_key, base_url)
self.cache = ResponseCache()
self.request_stats = {
"total_requests": 0,
"cache_hits": 0,
"cache_misses": 0,
"total_tokens": 0
}
async def chat_completion_with_cache(self,
messages: List[Dict],
use_cache: bool = True,
cache_ttl: Optional[int] = None,
**kwargs) -> Dict:
"""带缓存的聊天完成"""
self.request_stats["total_requests"] += 1
if use_cache:
# 尝试从缓存获取
cached_response = self.cache.get_cached_response(messages, kwargs)
if cached_response:
self.request_stats["cache_hits"] += 1
cached_response["from_cache"] = True
return cached_response
self.request_stats["cache_misses"] += 1
# 发起API请求
response = await self.chat_completion(messages, **kwargs)
if "usage" in response:
self.request_stats["total_tokens"] += response["usage"]["total_tokens"]
# 缓存成功响应
if use_cache and "error" not in response:
self.cache.cache_response(messages, kwargs, response, cache_ttl)
response["from_cache"] = False
return response
def get_performance_stats(self) -> Dict:
"""获取性能统计"""
total_requests = self.request_stats["total_requests"]
cache_hit_rate = (
self.request_stats["cache_hits"] / total_requests * 100
if total_requests > 0 else 0
)
return {
"total_requests": total_requests,
"cache_hit_rate": f"{cache_hit_rate:.2f}%",
"cache_hits": self.request_stats["cache_hits"],
"cache_misses": self.request_stats["cache_misses"],
"total_tokens_used": self.request_stats["total_tokens"]
}
# 性能优化使用示例
optimized_client = OptimizedGPTOSSClient("your_apiyi_key")
# 使用缓存的请求
response1 = await optimized_client.chat_completion_with_cache([
{"role": "user", "content": "什么是机器学习?"}
])
# 相同请求会从缓存返回
response2 = await optimized_client.chat_completion_with_cache([
{"role": "user", "content": "什么是机器学习?"}
])
print(f"第一次请求来自缓存: {response1['from_cache']}")
print(f"第二次请求来自缓存: {response2['from_cache']}")
print("性能统计:", optimized_client.get_performance_stats())
2. 并发处理优化
import asyncio
from asyncio import Semaphore
import aiohttp
class ConcurrentGPTOSSProcessor:
def __init__(self, api_key: str, max_concurrent: int = 10):
self.api_key = api_key
self.base_url = "https://vip.apiyi.com/v1"
self.semaphore = Semaphore(max_concurrent)
self.session = None
async def __aenter__(self):
"""异步上下文管理器入口"""
self.session = aiohttp.ClientSession()
return self
async def __aexit__(self, exc_type, exc_val, exc_tb):
"""异步上下文管理器退出"""
if self.session:
await self.session.close()
async def process_single_request(self, messages: List[Dict], **kwargs) -> Dict:
"""处理单个请求"""
async with self.semaphore:
headers = {
"Authorization": f"Bearer {self.api_key}",
"Content-Type": "application/json"
}
payload = {
"model": "gpt-oss-120b",
"messages": messages,
**kwargs
}
async with self.session.post(
f"{self.base_url}/chat/completions",
headers=headers,
json=payload
) as response:
if response.status == 200:
data = await response.json()
return {
"success": True,
"content": data["choices"][0]["message"]["content"],
"usage": data.get("usage", {})
}
else:
return {
"success": False,
"error": f"HTTP {response.status}: {await response.text()}"
}
async def batch_process(self,
requests: List[Dict],
progress_callback=None) -> List[Dict]:
"""批量处理请求"""
tasks = []
for i, request_data in enumerate(requests):
messages = request_data.get("messages", [])
params = {k: v for k, v in request_data.items() if k != "messages"}
task = self.process_single_request(messages, **params)
tasks.append(task)
# 执行所有任务
results = []
completed_count = 0
for coro in asyncio.as_completed(tasks):
result = await coro
results.append(result)
completed_count += 1
if progress_callback:
progress_callback(completed_count, len(tasks))
return results
# 并发处理使用示例
async def main():
# 准备批量请求
batch_requests = [
{
"messages": [{"role": "user", "content": f"解释概念:{concept}"}],
"max_tokens": 500,
"temperature": 0.7
}
for concept in ["人工智能", "机器学习", "深度学习", "神经网络", "自然语言处理"]
]
def progress_callback(completed, total):
progress = (completed / total) * 100
print(f"处理进度: {progress:.1f}% ({completed}/{total})")
async with ConcurrentGPTOSSProcessor("your_apiyi_key", max_concurrent=3) as processor:
results = await processor.batch_process(batch_requests, progress_callback)
for i, result in enumerate(results):
if result["success"]:
print(f"请求 {i+1} 成功:")
print(f"回答: {result['content'][:100]}...")
print(f"Token使用: {result['usage']}")
else:
print(f"请求 {i+1} 失败: {result['error']}")
# 运行并发处理
# asyncio.run(main())
📊 成本监控与优化
import time
from datetime import datetime, timedelta
from typing import Dict, List
import sqlite3
class CostMonitor:
def __init__(self, db_path: str = "gpt_oss_usage.db"):
"""初始化成本监控器"""
self.db_path = db_path
self.init_database()
# API易平台的gpt-oss-120b定价 ($/1K tokens)
self.pricing = {
"input_token_price": 0.15 / 1000, # 每个输入token价格
"output_token_price": 0.60 / 1000 # 每个输出token价格
}
def init_database(self):
"""初始化数据库"""
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute("""
CREATE TABLE IF NOT EXISTS usage_logs (
id INTEGER PRIMARY KEY AUTOINCREMENT,
timestamp TEXT,
request_type TEXT,
input_tokens INTEGER,
output_tokens INTEGER,
total_tokens INTEGER,
cost REAL,
model TEXT,
success BOOLEAN
)
""")
conn.commit()
conn.close()
def log_usage(self, usage_data: Dict):
"""记录使用情况"""
input_tokens = usage_data.get("prompt_tokens", 0)
output_tokens = usage_data.get("completion_tokens", 0)
total_tokens = usage_data.get("total_tokens", input_tokens + output_tokens)
# 计算成本
cost = (
input_tokens * self.pricing["input_token_price"] +
output_tokens * self.pricing["output_token_price"]
)
# 记录到数据库
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
cursor.execute("""
INSERT INTO usage_logs
(timestamp, request_type, input_tokens, output_tokens, total_tokens, cost, model, success)
VALUES (?, ?, ?, ?, ?, ?, ?, ?)
""", (
datetime.now().isoformat(),
usage_data.get("request_type", "chat"),
input_tokens,
output_tokens,
total_tokens,
cost,
usage_data.get("model", "gpt-oss-120b"),
usage_data.get("success", True)
))
conn.commit()
conn.close()
return cost
def get_usage_report(self, days: int = 30) -> Dict:
"""生成使用报告"""
since_date = (datetime.now() - timedelta(days=days)).isoformat()
conn = sqlite3.connect(self.db_path)
cursor = conn.cursor()
# 总体统计
cursor.execute("""
SELECT
COUNT(*) as total_requests,
SUM(input_tokens) as total_input_tokens,
SUM(output_tokens) as total_output_tokens,
SUM(total_tokens) as total_tokens,
SUM(cost) as total_cost,
AVG(cost) as avg_cost_per_request
FROM usage_logs
WHERE timestamp > ? AND success = 1
""", (since_date,))
stats = cursor.fetchone()
# 每日统计
cursor.execute("""
SELECT
DATE(timestamp) as date,
COUNT(*) as requests,
SUM(total_tokens) as tokens,
SUM(cost) as daily_cost
FROM usage_logs
WHERE timestamp > ? AND success = 1
GROUP BY DATE(timestamp)
ORDER BY date DESC
""", (since_date,))
daily_stats = cursor.fetchall()
conn.close()
return {
"period_days": days,
"total_requests": stats[0] or 0,
"total_input_tokens": stats[1] or 0,
"total_output_tokens": stats[2] or 0,
"total_tokens": stats[3] or 0,
"total_cost": round(stats[4] or 0, 4),
"avg_cost_per_request": round(stats[5] or 0, 4),
"daily_breakdown": [
{
"date": day[0],
"requests": day[1],
"tokens": day[2],
"cost": round(day[3], 4)
}
for day in daily_stats
]
}
def get_cost_optimization_suggestions(self) -> List[str]:
"""获取成本优化建议"""
report = self.get_usage_report(days=7)
suggestions = []
avg_tokens_per_request = (
report["total_tokens"] / report["total_requests"]
if report["total_requests"] > 0 else 0
)
if avg_tokens_per_request > 2000:
suggestions.append("考虑降低max_tokens参数,减少不必要的长回答")
if report["total_cost"] > 100: # 超过$100
suggestions.append("考虑启用响应缓存,减少重复请求")
suggestions.append("考虑自部署模型,降低大规模使用成本")
if report["total_input_tokens"] > report["total_output_tokens"] * 3:
suggestions.append("输入token较多,考虑优化prompt长度")
return suggestions
class CostAwareGPTOSSClient(OptimizedGPTOSSClient):
def __init__(self, api_key: str, base_url: str = "https://vip.apiyi.com/v1"):
super().__init__(api_key, base_url)
self.cost_monitor = CostMonitor()
self.daily_budget = None # 可设置每日预算限制
async def chat_completion_with_monitoring(self,
messages: List[Dict],
**kwargs) -> Dict:
"""带成本监控的聊天完成"""
# 检查预算限制
if self.daily_budget:
today_report = self.cost_monitor.get_usage_report(days=1)
if today_report["total_cost"] >= self.daily_budget:
return {
"error": f"已达到每日预算限制 ${self.daily_budget}",
"today_cost": today_report["total_cost"]
}
# 执行请求
response = await self.chat_completion_with_cache(messages, **kwargs)
# 记录使用情况
if "usage" in response:
cost = self.cost_monitor.log_usage({
**response["usage"],
"request_type": "chat",
"model": "gpt-oss-120b",
"success": "error" not in response
})
response["request_cost"] = cost
return response
def set_daily_budget(self, budget: float):
"""设置每日预算限制"""
self.daily_budget = budget
def get_cost_report(self, days: int = 30) -> Dict:
"""获取成本报告"""
return self.cost_monitor.get_usage_report(days)
def get_optimization_suggestions(self) -> List[str]:
"""获取优化建议"""
return self.cost_monitor.get_cost_optimization_suggestions()
# 成本监控使用示例
cost_aware_client = CostAwareGPTOSSClient("your_apiyi_key")
cost_aware_client.set_daily_budget(50.0) # 设置每日预算$50
# 监控使用情况
response = await cost_aware_client.chat_completion_with_monitoring([
{"role": "user", "content": "解释区块链技术"}
])
print(f"回答: {response.get('content', 'N/A')}")
print(f"本次请求成本: ${response.get('request_cost', 0):.4f}")
# 获取成本报告
cost_report = cost_aware_client.get_cost_report(days=7)
print("7天成本报告:", cost_report)
# 获取优化建议
suggestions = cost_aware_client.get_optimization_suggestions()
print("成本优化建议:", suggestions)
💡 技术建议:通过 API易 apiyi.com 使用 gpt-oss-120b 时,建议开启上述所有优化功能。平台提供了详细的使用统计和成本分析,帮助用户更好地控制和优化API使用成本。
❓ OpenAI gpt-oss-120b API 常见问题
Q1: gpt-oss-120b相比其他开源模型有什么独特优势?
gpt-oss-120b的独特优势主要体现在以下几个方面:
技术架构优势:
- MoE稀疏激活:1200亿参数模型仅激活51亿参数,在保证性能的同时大幅降低计算成本
- 企业级性能:在AIME数学测试中达到96.6%,超越大多数闭源模型
- 长上下文支持:128K token上下文窗口,适合处理大型文档
开源生态优势:
# 开源优势对比
comparison = {
"gpt-oss-120b": {
"license": "Apache 2.0",
"commercial_use": True,
"modification_allowed": True,
"redistribution": True,
"patent_protection": True,
"performance_tier": "GPT-4级别"
},
"llama-3": {
"license": "Custom License",
"commercial_use": True,
"modification_allowed": True,
"redistribution": False,
"patent_protection": False,
"performance_tier": "GPT-3.5级别"
},
"mistral-7b": {
"license": "Apache 2.0",
"commercial_use": True,
"modification_allowed": True,
"redistribution": True,
"patent_protection": True,
"performance_tier": "GPT-3级别"
}
}
企业应用优势:
- 合规友好:Apache 2.0许可证满足大多数企业合规要求
- 部署灵活:支持云端API、本地部署、边缘计算等多种部署方式
- 成本可控:相比闭源模型节省90%以上成本
- 技术可控:完全掌握模型权重,避免供应商锁定
推荐使用策略:对于需要高性能开源模型的企业用户,gpt-oss-120b是目前最佳选择。通过 API易 apiyi.com 可以快速体验其能力,再根据实际需求选择部署方案。
Q2: 如何选择API调用还是本地部署?
选择API调用还是本地部署需要综合考虑多个因素:
决策框架:
def deployment_decision_matrix(use_case_params):
"""部署决策矩阵"""
score = 0
recommendations = []
# 使用量评估
monthly_requests = use_case_params.get("monthly_requests", 0)
if monthly_requests < 100000: # 10万次以下
score += 1 # 倾向API
recommendations.append("低使用量适合API调用")
elif monthly_requests > 1000000: # 100万次以上
score -= 2 # 倾向自部署
recommendations.append("高使用量建议自部署")
# 数据敏感性
data_sensitivity = use_case_params.get("data_sensitivity", "medium")
if data_sensitivity == "high":
score -= 3 # 强烈倾向自部署
recommendations.append("敏感数据必须本地部署")
elif data_sensitivity == "low":
score += 1 # 倾向API
# 技术能力
tech_capability = use_case_params.get("tech_capability", "medium")
if tech_capability == "low":
score += 2 # 倾向API
recommendations.append("技术能力有限建议使用API")
elif tech_capability == "high":
score -= 1 # 可以考虑自部署
# 预算考虑
budget_sensitivity = use_case_params.get("budget_sensitivity", "medium")
if budget_sensitivity == "high":
score -= 1 # 倾向自部署
recommendations.append("预算敏感建议长期自部署")
# 给出建议
if score >= 2:
decision = "推荐API调用"
elif score <= -2:
decision = "推荐本地部署"
else:
decision = "建议混合方案"
return {
"decision": decision,
"score": score,
"recommendations": recommendations
}
# 使用示例
enterprise_case = {
"monthly_requests": 500000,
"data_sensitivity": "high",
"tech_capability": "high",
"budget_sensitivity": "medium"
}
decision = deployment_decision_matrix(enterprise_case)
print(f"决策建议: {decision['decision']}")
print("具体建议:", decision['recommendations'])
API调用适用场景:
- 月使用量 < 50万次请求
- 数据敏感性较低
- 团队技术能力有限
- 需要快速上线和迭代
- 不想承担运维责任
本地部署适用场景:
- 月使用量 > 100万次请求
- 数据安全要求极高
- 有专业运维团队
- 长期使用,成本敏感
- 需要模型定制化
混合部署策略:
class HybridDeploymentStrategy:
def __init__(self):
self.api_client = GPTOSSClient("apiyi_key")
self.local_endpoint = "http://localhost:8000"
async def route_request(self, messages, data_sensitivity="low"):
"""智能路由请求"""
if data_sensitivity == "high":
# 敏感数据使用本地部署
return await self.call_local_model(messages)
else:
# 一般数据使用API
return await self.api_client.chat_completion(messages)
async def call_local_model(self, messages):
"""调用本地部署的模型"""
# 实现本地模型调用逻辑
pass
成本对比分析:
- API方案:适合中小规模使用,无需前期投入
- 自部署方案:适合大规模使用,需要考虑硬件、电力、人工成本
- 混合方案:灵活性最高,可以根据具体需求动态选择
推荐策略:建议先通过 API易 apiyi.com 进行API调用测试,评估实际使用情况和成本,再决定是否需要自部署。API易提供了完整的使用统计,帮助用户做出准确的成本分析。
Q3: gpt-oss-120b在特定行业应用中需要注意什么?
不同行业应用gpt-oss-120b需要考虑特定的合规、安全和技术要求:
医疗健康行业:
class HealthcareCompliantGPTOSS:
def __init__(self):
self.compliance_requirements = {
"HIPAA": {
"data_encryption": "required",
"access_control": "role_based",
"audit_logging": "comprehensive",
"data_retention": "controlled"
},
"FDA_guidelines": {
"model_validation": "required",
"bias_testing": "mandatory",
"performance_monitoring": "continuous"
}
}
def medical_query_filter(self, query):
"""医疗查询过滤器"""
restricted_patterns = [
"具体诊断", "治疗方案", "药物推荐", "手术建议"
]
for pattern in restricted_patterns:
if pattern in query:
return {
"allowed": False,
"reason": f"包含受限内容: {pattern}",
"alternative": "建议咨询专业医生"
}
return {"allowed": True}
async def safe_medical_consultation(self, query):
"""安全的医疗咨询"""
filter_result = self.medical_query_filter(query)
if not filter_result["allowed"]:
return {
"response": f"抱歉,{filter_result['reason']}。{filter_result['alternative']}",
"disclaimer": "本系统不提供医疗诊断或治疗建议"
}
# 添加医疗免责声明
system_prompt = """
你是医疗信息助手,只能提供一般健康信息。
重要限制:
1. 不能进行医疗诊断
2. 不能推荐具体治疗方案
3. 不能替代专业医疗咨询
4. 必须提醒用户咨询医生
"""
# 调用模型并添加免责声明
# ... 实现API调用逻辑
return {
"response": "基于一般医疗知识的回答...",
"disclaimer": "此信息仅供参考,请咨询专业医生获取个性化医疗建议"
}
金融服务行业:
class FinanceCompliantGPTOSS:
def __init__(self):
self.compliance_frameworks = {
"SOX": "财务报告合规",
"PCI_DSS": "支付卡数据安全",
"BASEL_III": "银行监管要求",
"MiFID_II": "欧盟金融工具指令"
}
self.risk_categories = {
"investment_advice": "投资建议风险",
"credit_assessment": "信用评估风险",
"market_prediction": "市场预测风险",
"personal_finance": "个人理财风险"
}
def financial_content_validator(self, content, content_type="general"):
"""金融内容验证器"""
validation_rules = {
"investment_advice": [
"必须包含风险警告",
"不能保证收益",
"需要免责声明"
],
"credit_assessment": [
"不能替代正式评估",
"需要声明非官方意见",
"保护隐私信息"
]
}
required_disclaimers = validation_rules.get(content_type, [])
return {
"validated": True,
"required_disclaimers": required_disclaimers,
"compliance_note": "确保遵守当地金融监管要求"
}
async def compliant_financial_analysis(self, financial_data, analysis_type):
"""合规的金融分析"""
validation = self.financial_content_validator(financial_data, analysis_type)
# 添加适当的免责声明和风险警告
compliance_prefix = """
重要声明:
- 此分析仅供参考,不构成投资建议
- 投资有风险,过往表现不代表未来结果
- 请咨询合格的金融顾问
"""
# 执行分析...
return {
"analysis": "金融分析结果...",
"disclaimer": compliance_prefix,
"risk_warning": "请注意投资风险"
}
教育培训行业:
class EducationGPTOSSFramework:
def __init__(self):
self.educational_standards = {
"FERPA": "学生隐私保护",
"COPPA": "儿童在线隐私保护",
"ADA": "无障碍访问要求"
}
def age_appropriate_filter(self, content, student_age):
"""年龄适宜性过滤"""
if student_age < 13:
# 儿童内容过滤
inappropriate_topics = [
"violence", "adult_content", "political_controversy"
]
# 实现内容过滤逻辑
elif student_age < 18:
# 青少年内容过滤
restricted_topics = ["extreme_politics", "inappropriate_relationships"]
# 实现内容过滤逻辑
return {"appropriate": True, "filtered_content": content}
async def educational_content_generation(self, topic, grade_level, learning_objective):
"""教育内容生成"""
educational_prompt = f"""
为{grade_level}年级学生创建关于{topic}的教学内容。
学习目标:{learning_objective}
要求:
1. 年龄适宜,语言简单易懂
2. 包含互动元素
3. 提供实例和练习
4. 符合教育标准
"""
# 调用gpt-oss-120b生成内容
# 应用年龄适宜性过滤
# 返回教育内容
return {
"content": "教育内容...",
"grade_level": grade_level,
"safety_validated": True
}
法律服务行业:
class LegalComplianceGPTOSS:
def __init__(self):
self.legal_disclaimers = {
"general": "此信息不构成法律建议,请咨询专业律师",
"contract": "合同条款解释仅供参考,不替代法律咨询",
"litigation": "诉讼建议需要专业律师评估"
}
def legal_content_validator(self, content, jurisdiction="general"):
"""法律内容验证"""
validation_requirements = {
"no_legal_advice": "不能提供具体法律建议",
"disclaimer_required": "必须包含免责声明",
"jurisdiction_specific": "需要考虑司法管辖区差异"
}
return validation_requirements
async def legal_document_analysis(self, document, analysis_type="general"):
"""法律文档分析"""
legal_disclaimer = self.legal_disclaimers.get(analysis_type, self.legal_disclaimers["general"])
system_prompt = f"""
你是法律文档分析助手,提供文档解读服务。
重要限制:
1. 不提供具体法律建议
2. 不替代专业律师咨询
3. 分析仅供参考
4. 考虑司法管辖区差异
免责声明:{legal_disclaimer}
"""
# 执行文档分析
return {
"analysis": "法律文档分析结果...",
"disclaimer": legal_disclaimer,
"recommendation": "建议咨询专业律师获取具体法律建议"
}
行业应用最佳实践总结:
- 数据安全:敏感行业应优先考虑本地部署
- 合规要求:建立行业特定的内容过滤和验证机制
- 免责声明:所有行业应用都需要适当的免责声明
- 人工审核:关键决策仍需人工专家参与
- 持续监控:建立模型输出的质量监控机制
推荐实施策略:通过 API易 apiyi.com 先进行小规模试点,验证合规性和效果,再逐步扩大应用范围。API易提供了完整的日志记录和审计功能,满足各行业的合规要求。
Q4: gpt-oss-120b的未来发展方向是什么?
gpt-oss-120b作为开源大模型的重要里程碑,其未来发展呈现出多个重要趋势:
技术演进方向:
# 技术发展路线预测
future_roadmap = {
"2025_Q4": {
"model_improvements": [
"更高效的MoE架构",
"扩展到256K上下文窗口",
"多模态能力集成(图像、音频)",
"推理速度优化(量化、剪枝)"
],
"ecosystem_growth": [
"专业领域微调版本",
"边缘设备部署优化",
"更多云平台原生支持"
]
},
"2026": {
"architecture_breakthroughs": [
"下一代MoE架构",
"神经符号结合",
"动态计算图优化",
"自适应专家路由"
],
"application_expansion": [
"代码生成专用版本",
"科学研究专用版本",
"创意写作优化版本",
"实时对话优化版本"
]
},
"2027+": {
"paradigm_shifts": [
"完全分布式训练",
"联邦学习集成",
"自主学习能力",
"多模态统一架构"
],
"ecosystem_maturity": [
"标准化开发工具链",
"企业级管理平台",
"自动化部署系统",
"全球开发者生态"
]
}
}
开源生态演进:
- 社区驱动创新
class OpenSourceEcosystemPrediction:
def __init__(self):
self.community_trends = {
"fine_tuning_tools": "更简单的微调工具",
"deployment_frameworks": "标准化部署框架",
"evaluation_benchmarks": "专业评估基准",
"safety_tools": "安全检测工具链"
}
def predict_community_contributions(self):
"""预测社区贡献方向"""
return {
"vertical_adaptations": [
"医疗专用版本(HealthGPT-OSS)",
"金融专用版本(FinanceGPT-OSS)",
"教育专用版本(EduGPT-OSS)",
"法律专用版本(LegalGPT-OSS)"
],
"optimization_variants": [
"移动端优化版本",
"IoT设备版本",
"高并发服务版本",
"低延迟版本"
],
"multilingual_expansions": [
"中文优化版本",
"多语言专用版本",
"方言支持版本",
"代码语言专用版本"
]
}
- 商业化发展趋势
class CommercializationTrends:
def __init__(self):
self.business_models = {
"saas_platforms": "基于gpt-oss的SaaS服务",
"consulting_services": "专业实施咨询服务",
"custom_solutions": "定制化解决方案",
"training_services": "模型训练服务"
}
def analyze_market_opportunities(self):
"""分析市场机会"""
return {
"enterprise_adoption": {
"timeline": "2025-2026年大规模采用",
"drivers": ["成本优势", "技术自主", "合规要求"],
"barriers": ["技术复杂性", "人才短缺", "运维成本"]
},
"startup_ecosystem": {
"opportunities": ["垂直应用", "工具链", "平台服务"],
"funding_trends": "开源AI基础设施投资增长",
"success_factors": ["技术深度", "市场定位", "商业模式"]
}
}
竞争格局变化:
- 与闭源模型的竞争
def competitive_landscape_analysis():
"""竞争格局分析"""
return {
"competitive_advantages": {
"openness": "完全透明,可审计",
"cost": "显著成本优势",
"flexibility": "部署和定制灵活性",
"innovation_speed": "社区驱动的快速迭代"
},
"remaining_gaps": {
"performance": "在某些任务上仍有差距",
"ecosystem": "工具链和服务生态待完善",
"enterprise_support": "企业级支持服务需加强"
},
"convergence_prediction": "2026-2027年性能差距基本消除"
}
- 技术标准化趋势
class StandardizationTrends:
def __init__(self):
self.standards_development = {
"model_interfaces": "统一的模型API标准",
"deployment_formats": "标准化部署格式",
"evaluation_metrics": "统一评估标准",
"safety_protocols": "安全检测协议"
}
def predict_standardization_timeline(self):
"""预测标准化时间线"""
return {
"2025": "基础API标准制定",
"2026": "部署和评估标准确立",
"2027": "安全和合规标准成熟",
"2028": "完整标准体系建立"
}
对产业的长期影响:
- AI民主化加速
- 降低AI技术使用门槛
- 促进中小企业AI应用
- 推动AI教育普及
- 加速全球AI创新
- 产业结构重塑
- 传统AI公司商业模式调整
- 开源服务生态快速发展
- 新型AI基础设施公司涌现
- 垂直行业AI解决方案繁荣
投资和发展建议:
class StrategicRecommendations:
def get_recommendations_by_role(self, role):
"""根据角色提供发展建议"""
recommendations = {
"developers": [
"深入学习gpt-oss-120b技术细节",
"参与开源社区贡献",
"掌握微调和部署技能",
"关注垂直领域应用机会"
],
"enterprises": [
"制定开源AI战略",
"建立内部AI团队",
"试点关键业务场景",
"投资AI基础设施"
],
"investors": [
"关注开源AI基础设施公司",
"投资垂直行业AI应用",
"支持开源工具链开发",
"关注AI安全和合规技术"
],
"startups": [
"基于gpt-oss构建差异化产品",
"专注特定行业或场景",
"建立技术壁垒",
"快速验证商业模式"
]
}
return recommendations.get(role, [])
结论:gpt-oss-120b代表了开源AI的重要转折点,将推动整个行业向更开放、更民主化的方向发展。通过 API易 apiyi.com 等平台的支持,开发者和企业可以更容易地参与到这一技术革命中,共同推动AI技术的进步和各项业务发展。欢迎调用。