最近我帮一个科研团队处理了一批超大规模的实验数据,用的是 Google 今年 9 月发布的 Gemini-1.5-Flash-002 模型。不得不说,这个性价比真的高得有点夸张。—— 经验就是:它特别适合干些脏活累活,先让便宜的小模型做数据提取,再让更优质的大模型去做总结和分析。
欢迎免费试用API易,3 分钟跑通 API 调用 https://www.apiyi.com/register/?aff_code=HDnF
支持 Gemini-1.5-Flash-002 等 Gemini 全系列模型
为什么选 Gemini-1.5-Flash 系列?
先说说最吸引我的三个特点:
- 性价比真的高
- 输入每百万 tokens 只要 $0.15
- 输出每百万 tokens 只要 $0.60
- 比 GPT-4 便宜太多了
- 处理能力很强
- 支持 100 万+ tokens 的超长上下文
- 速度比上一代快了一倍
- 延迟降低了三倍
- 数据处理很给力
- 提取效果比 gpt-mini 好
- 支持多种数据格式
- 特别适合批量处理
跟 GPT-4o Mini 的对比分析
很多朋友可能会问:为什么不用更便宜的 GPT-4o Mini?我做了个详细对比:
1. 性能对比
| 特性 | Gemini-1.5-Flash-002 | GPT-4o Mini |
|---|---|---|
| 上下文窗口 | 104万 tokens | 12.8万 tokens |
| 最大输出 | 8,192 tokens | 16,400 tokens |
| 输出速度 | 163.6 tokens/秒 | 85.2 tokens/秒 |
| 首token延迟 | 1.06秒 | 0.45秒 |
2. 价格对比
API 易的价格对齐 GPT-4o mini
| 计费项 | Gemini-1.5-Flash-002 | GPT-4o Mini |
|---|---|---|
| 输入价格 | $0.15/百万tokens | $0.15/百万tokens |
| 输出价格 | $0.60/百万tokens | $0.60/百万tokens |
3. 功能对比
- Gemini 优势:
- 支持音频、视频处理
- 上下文窗口更大
- 处理速度更快
- 价格更便宜
- Mini 优势:
- 首次响应更快
- 单次输出更长
- 基准测试分数略高
我的建议是:如果你的数据量很大,建议用 Gemini-1.5-Flash-002,性价比更高;如果是小规模测试或对响应速度要求特别高的场景,GPT-4o Mini 也是不错的选择。
实际案例分析
来看一个真实的数据处理案例(部分消耗记录截图):
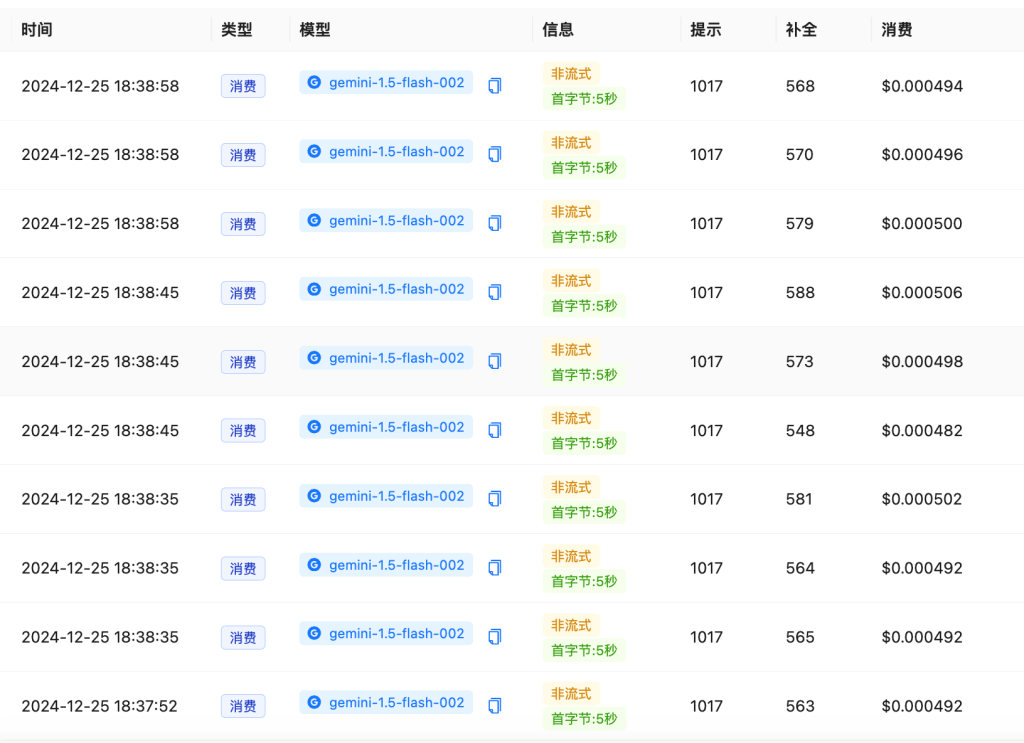
从上面的数据可以看出:
- 每次请求输入约 1017 个 tokens
- 输出在 548-588 tokens 之间
- 单次请求成本仅 $0.0004-0.0005
- 首字节响应时间稳定在 5 秒内(视不同内容而定,有些内容需要思考时间)
成本分析:
- 输入成本:1017 tokens × $0.13/百万 ≈ $0.00013
- 输出成本:~570 tokens × $0.38/百万 ≈ $0.00022
- 总成本:每次请求约 $0.0005
这意味着,处理 1000 条类似的数据记录,总成本也就 0.5 美元左右。相比其他模型,这个性价比真的很高了。
特别要说明的是:
- 响应速度很稳定,基本都是 5 秒出结果;
- 输出 token 数比较稳定,说明结果格式统一;
- 成本可预期,便于项目预算。
开发者上手指南
1. API 调用示例
from openai import OpenAI
# 设置API密钥和基础URL
api_key = "sk-开头的 Key,来自API易后台复制,需要更改"
api_base = "https://vip.apiyi.com/v1"
client = OpenAI(api_key=api_key, base_url=api_base)
response = client.chat.completions.create(
model="gemini-1.5-flash-002", # 使用最新的 Flash 模型
messages=[
{
"role": "user",
"content": "请从以下实验数据中提取关键指标:[你的数据]"
}
],
max_tokens=1000,
)
print(response.choices.message.content)
2. 实用小技巧(重点来了)
- 数据预处理很重要:
- 先整理成结构化格式
- 去掉无关的空白字符
- 统一数据的格式和单位
- 提示词要精准:
- 明确指定提取的字段
- 要求输出固定格式
- 批量处理要分批进行
- 成本控制有妙招:
- 先用小批量测试
- 压缩冗余数据
- 设置合理的 max_tokens
实战应用场景
我总结了几个特别适合的场景:
- 实验数据处理
- 提取关键指标
- 标准化实验记录
- 生成数据报告
- 文献分析整理
- 提取研究方法
- 汇总实验结果
- 对比数据差异
- 数据清洗转换
- 格式标准化
- 异常值检测
- 缺失值处理
踩坑经验分享
用了一段时间,我也遇到过一些坑,给大家提个醒:
- 数据格式要注意
- 中文编码要统一
- 数字格式要规范
- 特殊字符要处理
- 批量处理要规划
- 合理分批大小
- 做好错误重试
- 保存中间结果
- 成本预估要准
- 预留 token 余量
- 考虑重试成本
- 监控使用情况
未来展望
我觉得 Gemini-1.5-Flash-002 在科研数据处理方面还会有更多惊喜:
- 更强的理解能力
- 更准确的数据提取
- 更智能的异常检测
- 更好的上下文理解
- 更多的优化空间
- 处理速度会更快
- 成本可能更低
- 支持更多格式
欢迎免费试用我们的 API 服务产品:API易 https://www.apiyi.com/register/?aff_code=HDnF
通过 API易 调用 Gemini-1.5-Flash-002 的优势:
– 价格便宜
– 支持高并发调用,无使用限制
– 3分钟即可完成接入,快速上手

有什么想法和经验,请右侧扫码添加站长微信进行交流,并且赠送你 API易 一美金额度供测试体验。