在 AI 应用开发中,大模型 API 的联网查询能力已成为核心功能需求之一。无论是实时信息检索、新闻分析,还是动态数据查询,联网能力都能显著提升 AI 应用的实用性和准确性。然而,许多开发者在接入大模型 API 时,常面临一个关键问题:如何让模型具备联网查询能力?本文将深度对比 5 种主流技术方案,从原生工具调用、封装式联网能力、逆向 API、MCP 协议,到工作流编排,分析各方案的技术原理、稳定性、成本和适用场景,帮助您选择最优解决方案。
为什么大模型 API 需要联网能力
知识截止日期的局限性
所有大语言模型都有固定的知识截止日期。例如:
- GPT-4 Turbo: 2023 年 12 月
- Claude 3.5 Sonnet: 2024 年 8 月
- Gemini 3 系列: 2025 年 1 月
这意味着模型无法回答超出截止日期的实时问题,如:
- "今天的股市行情如何?"
- "最新的 iPhone 发布了哪些功能?"
- "昨天的NBA比赛结果是什么?"
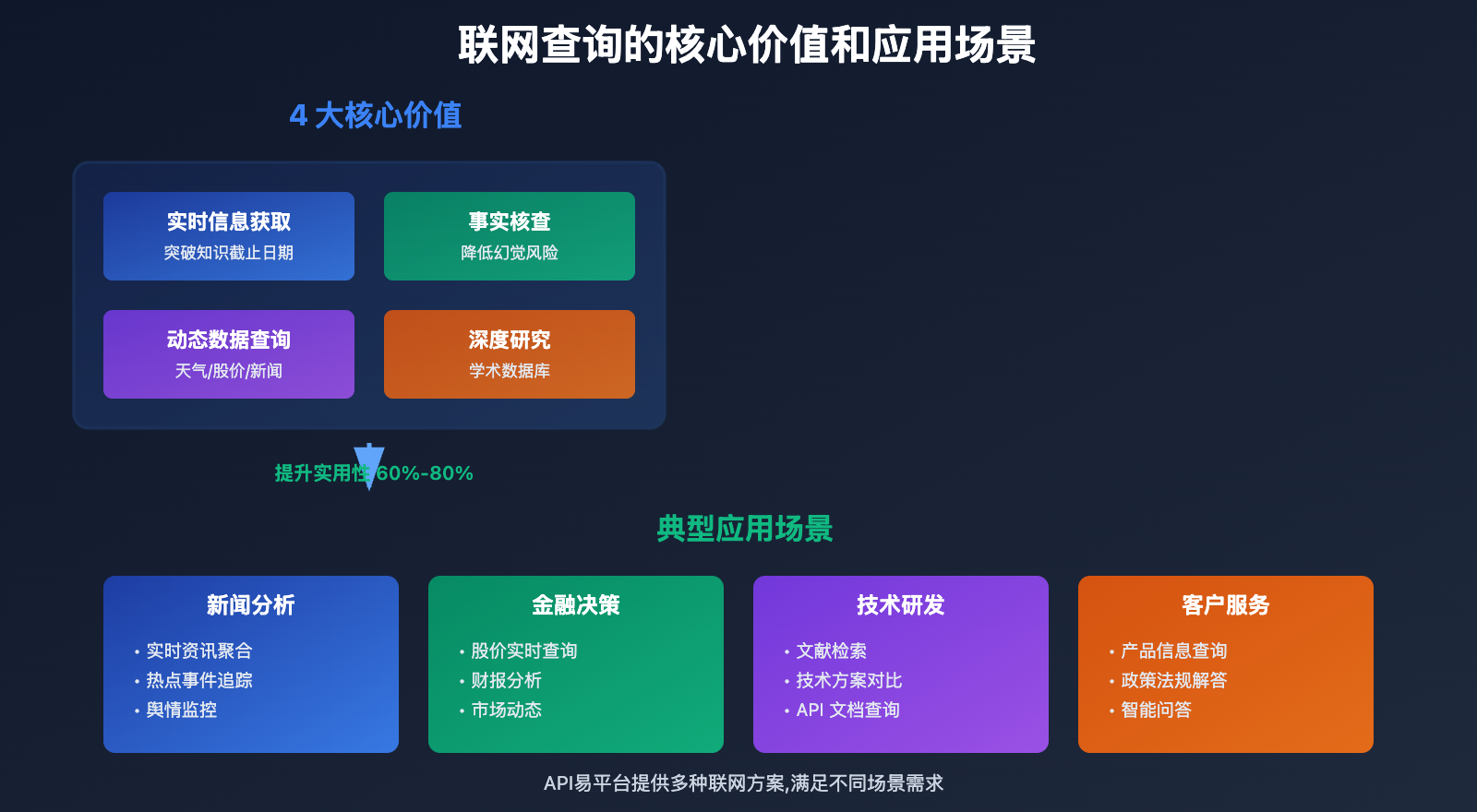
联网查询的核心价值
1. 实时信息获取: 突破知识截止日期限制,获取最新数据
2. 事实核查: 验证模型输出的准确性,降低幻觉风险
3. 动态数据查询: 天气、股价、新闻等实时变化的信息
4. 深度研究: 结合搜索引擎和学术数据库,进行深度分析
🎯 应用场景: 在新闻分析、金融决策、技术研发、客户服务等场景中,联网查询能力可将 AI 应用的实用性提升 60%-80%。推荐通过 API易 apiyi.com 平台接入支持联网查询的模型,该平台整合了多种联网解决方案,帮助开发者快速实现联网功能。
方案一: 原生工具调用(Function Calling)
技术原理
部分正式版大模型内置了工具调用(Function Calling) 或 Tools API 功能,开发者可以定义联网查询工具,让模型在需要时主动调用。
工作流程:
- 开发者定义联网查询工具(如
web_search) - 用户提出需要联网的问题
- 模型识别需求,输出工具调用请求
- 开发者后端执行实际搜索(调用 Google、Bing API 等)
- 将搜索结果返回给模型
- 模型基于搜索结果生成最终答案
支持的模型
| 模型 | 工具调用支持 | 官方文档 |
|---|---|---|
| GPT-4 Turbo | ✅ Function Calling | OpenAI Docs |
| GPT-4o | ✅ Function Calling | OpenAI Docs |
| Claude 3.5 Sonnet | ✅ Tool Use | Anthropic Docs |
| Gemini 1.5 Pro | ✅ Function Calling | Google AI Docs |
| Gemini 3 系列 | ✅ Function Calling | Google AI Docs |
技术实现示例
import openai
# 定义联网查询工具
tools = [
{
"type": "function",
"function": {
"name": "web_search",
"description": "搜索互联网获取实时信息",
"parameters": {
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词"
}
},
"required": ["query"]
}
}
}
]
# 调用模型
response = openai.chat.completions.create(
model="gpt-4-turbo",
messages=[{"role": "user", "content": "今天北京的天气如何?"}],
tools=tools,
tool_choice="auto"
)
# 如果模型请求调用工具
if response.choices[0].message.tool_calls:
tool_call = response.choices[0].message.tool_calls[0]
# 执行实际搜索(调用 Google Search API 等)
search_result = execute_web_search(tool_call.function.arguments)
# 将结果返回给模型
final_response = openai.chat.completions.create(
model="gpt-4-turbo",
messages=[
{"role": "user", "content": "今天北京的天气如何?"},
response.choices[0].message,
{"role": "tool", "tool_call_id": tool_call.id, "content": search_result}
]
)
优势与劣势
优势:
- ✅ 官方支持,稳定性高
- ✅ 灵活可控,可自定义搜索逻辑
- ✅ 适合复杂工作流,可组合多个工具
劣势:
- ❌ 需要自己实现搜索逻辑和 API 对接
- ❌ 开发成本较高,需要处理工具调用的多轮对话
- ❌ 需要额外付费搜索 API(Google、Bing 等)
适用场景: 企业级应用,需要高度定制化的联网查询逻辑,愿意投入开发成本。
💡 开发建议: 对于需要精细控制搜索逻辑的场景,推荐使用工具调用方案。通过 API易 apiyi.com 平台调用支持工具的模型,平台提供详细的工具调用示例和调试工具,简化开发流程。
方案二: 封装式联网能力(内置联网)
技术原理
部分模型或服务商已将联网查询能力内置封装,开发者无需手动定义工具,模型会自动判断是否需要联网并执行搜索。
工作流程:
- 用户提出问题
- 模型自动识别是否需要联网
- 模型内部调用搜索服务(透明化处理)
- 直接返回包含实时信息的答案
支持的服务
| 服务 | 联网方式 | 特点 |
|---|---|---|
| Perplexity AI | 内置联网 | 专注实时搜索,引用来源 |
| Google Gemini(网页版) | 内置联网 | 自动联网,无需配置 |
| Claude(网页版) | 内置联网 | 2025 年部分支持 |
| You.com | 内置联网 | 搜索引擎+AI对话 |
技术实现示例
# Perplexity API 示例
import requests
response = requests.post(
"https://api.perplexity.ai/chat/completions",
headers={
"Authorization": "Bearer YOUR_API_KEY",
"Content-Type": "application/json"
},
json={
"model": "llama-3.1-sonar-large-128k-online",
"messages": [
{"role": "user", "content": "今天北京的天气如何?"}
]
}
)
# 模型自动联网查询,返回包含实时信息的答案
print(response.json()["choices"][0]["message"]["content"])
优势与劣势
优势:
- ✅ 开箱即用,无需额外开发
- ✅ 开发成本极低,一次调用完成
- ✅ 自动引用来源,提高可信度
劣势:
- ❌ 黑盒处理,无法控制搜索逻辑
- ❌ 可能产生额外费用(部分服务按联网次数计费)
- ❌ 模型选择有限,主要是特定服务商
适用场景: 快速原型开发,简单的联网查询需求,不需要精细控制搜索过程。
🚀 快速上手: 对于初创团队和 MVP 验证,推荐使用封装式联网方案。API易 apiyi.com 平台已接入 Perplexity 等内置联网的模型,开箱即用,5 分钟即可完成集成。
方案三: 逆向 API(非官方稳定性低)
技术原理
逆向 API 通过模拟网页版请求,调用官方网页版的联网功能。例如 claude-sonnet-4-5-20250929-all 就是通过逆向 claude.ai 网页版实现的。
工作流程:
- 逆向工程师分析网页版请求
- 模拟浏览器请求,伪装成真实用户
- 调用网页版的联网查询功能
- 解析返回数据,封装成 API 格式
典型案例
Claude 逆向 API:
claude-sonnet-4-5-20250929-all: 模拟 claude.ai 网页版,支持联网查询- 由第三方服务商提供,API易等平台有接入
ChatGPT 逆向 API:
gpt-4-web: 模拟 chat.openai.com,支持联网和插件- 部分服务商提供
技术实现示例
# 通过 API易平台调用逆向 Claude API
import openai
client = openai.OpenAI(
api_key="YOUR_APIYI_API_KEY",
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="claude-sonnet-4-5-20250929-all", # 逆向模型,支持联网
messages=[
{"role": "user", "content": "今天硅谷银行的股价是多少?"}
]
)
# 模型会自动联网查询并返回实时答案
print(response.choices[0].message.content)
优势与劣势
优势:
- ✅ 可访问网页版独有功能(如联网、插件)
- ✅ 通常价格更低,部分服务商提供优惠
- ✅ 开发简单,与标准 API 接口一致
劣势:
- ❌ 稳定性无保障: 官方更新可能导致失效
- ❌ 可能违反服务条款: 存在封号风险
- ❌ 不适合生产环境: 仅建议学习和体验
- ❌ 功能可能不完整,部分高级功能不支持
适用场景: 学习体验、技术验证、非关键应用,不推荐用于生产环境。
⚠️ 重要提醒: 逆向 API 虽然可以快速体验联网功能,但稳定性无法保证。API易 apiyi.com 平台提供的逆向模型仅供学习和测试,对于生产环境,强烈推荐使用方案一(工具调用)或方案二(封装式联网)。
方案四: MCP 协议(Model Context Protocol)
技术原理
MCP(Model Context Protocol)是 Anthropic 推出的开放协议,旨在标准化 AI 模型与外部工具(包括联网查询)的交互方式。
核心概念:
- MCP Server: 提供工具能力的服务端(如联网查询服务器)
- MCP Client: 调用工具的客户端(AI 应用)
- 标准化协议: 统一的工具定义和调用格式
工作流程:
- 部署 MCP Server,提供联网查询能力
- AI 应用通过 MCP Client 连接 Server
- 模型发起联网请求,MCP Client 转发给 Server
- Server 执行搜索,返回结果
- 模型基于结果生成答案
技术实现示例
# 使用 MCP 协议实现联网查询
# 1. 安装 MCP 工具
# pip install mcp
# 2. 启动 MCP Server (提供联网查询工具)
from mcp.server import Server
from mcp.server.models import InitializationOptions
import httpx
app = Server("web-search-server")
@app.list_tools()
async def handle_list_tools():
return [
{
"name": "web_search",
"description": "搜索互联网获取实时信息",
"inputSchema": {
"type": "object",
"properties": {
"query": {"type": "string"}
}
}
}
]
@app.call_tool()
async def handle_call_tool(name: str, arguments: dict):
if name == "web_search":
# 调用搜索 API (Google、Bing 等)
query = arguments["query"]
results = await search_web(query)
return {"content": [{"type": "text", "text": results}]}
# 3. AI 应用通过 MCP Client 调用
from mcp import ClientSession, StdioServerParameters
from anthropic import Anthropic
async with ClientSession(StdioServerParameters(command="python", args=["mcp_server.py"])) as session:
tools = await session.list_tools()
client = Anthropic()
response = client.messages.create(
model="claude-3-5-sonnet-20241022",
messages=[{"role": "user", "content": "今天的科技新闻有哪些?"}],
tools=tools
)
优势与劣势
优势:
- ✅ 标准化协议,工具可复用
- ✅ 解耦模型和工具,灵活扩展
- ✅ 支持多种工具组合,不限于联网
- ✅ Anthropic 官方支持,Claude 深度集成
劣势:
- ❌ 技术较新,生态尚不成熟
- ❌ 学习曲线较陡,需要理解协议
- ❌ 需要部署 MCP Server,增加运维成本
- ❌ 目前主要支持 Claude,其他模型支持有限
适用场景: 复杂的企业级应用,需要集成多种工具(联网、数据库、API 调用等),追求标准化和可扩展性。
💡 技术展望: MCP 协议代表了 AI 工具集成的未来方向。对于需要构建复杂工具链的团队,推荐深入学习 MCP。API易 apiyi.com 平台计划在 2025 年 Q2 推出 MCP Server 托管服务,简化部署和运维。
方案五: 工作流编排(外部工具集成)
技术原理
通过工作流编排工具(如 Langchain、LlamaIndex、Dify 等),将大模型与搜索引擎、数据库、API 等外部工具组合使用,分步骤执行联网查询。
核心组件:
- 大模型 API: 提供推理和生成能力
- 搜索工具: Google Search API、Bing API、SerpAPI 等
- 工作流引擎: 编排工具调用顺序和逻辑
- 向量数据库: 存储和检索搜索结果
工作流程:
- 用户提出问题
- 工作流引擎分析问题,决定执行步骤
- 调用搜索工具获取实时信息
- 将搜索结果存入向量数据库或直接传递
- 大模型基于搜索结果生成答案
- 可选:进一步检索或多轮搜索
技术实现示例
使用 Langchain 实现联网查询:
from langchain.agents import initialize_agent, Tool
from langchain.agents import AgentType
from langchain.chat_models import ChatOpenAI
from langchain.tools import DuckDuckGoSearchRun
# 初始化搜索工具
search = DuckDuckGoSearchRun()
# 定义工具列表
tools = [
Tool(
name="Web Search",
func=search.run,
description="用于搜索互联网获取实时信息。当需要最新数据、新闻或事实核查时使用。"
)
]
# 初始化大模型
llm = ChatOpenAI(
model="gpt-4-turbo",
api_key="YOUR_API_KEY",
base_url="https://api.apiyi.com/v1" # 通过 API易平台调用
)
# 创建 Agent
agent = initialize_agent(
tools=tools,
llm=llm,
agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION,
verbose=True
)
# 执行联网查询
response = agent.run("今天有哪些重要的科技新闻?")
print(response)
使用 Dify 实现联网查询:
# Dify 工作流配置
workflow:
- name: "用户输入"
type: "start"
- name: "判断是否需要联网"
type: "llm"
model: "gpt-4-turbo"
prompt: "判断以下问题是否需要搜索实时信息: {{user_input}}"
- name: "搜索互联网"
type: "tool"
tool: "google_search"
condition: "{{需要联网}} == true"
- name: "生成最终答案"
type: "llm"
model: "gpt-4-turbo"
prompt: "基于搜索结果回答: {{search_results}}"
- name: "输出结果"
type: "end"
优势与劣势
优势:
- ✅ 高度灵活,可自定义复杂逻辑
- ✅ 支持多种搜索源,可并行搜索
- ✅ 易于调试和优化,每个步骤可独立测试
- ✅ 丰富的生态,大量现成的工具和模板
劣势:
- ❌ 学习成本较高,需要掌握工作流工具
- ❌ 系统复杂度增加,需要维护多个组件
- ❌ 延迟较高,多步骤执行耗时较长
- ❌ 成本可能较高,多次调用模型和搜索 API
适用场景: 复杂的 AI 应用,需要多轮搜索、信息整合、知识图谱构建等高级功能。
🎯 最佳实践: 工作流编排方案适合构建复杂的 AI Agent 和 RAG 系统。推荐使用 Langchain + API易平台的组合,Langchain 提供强大的工作流能力,API易提供稳定的模型接入和成本优化。
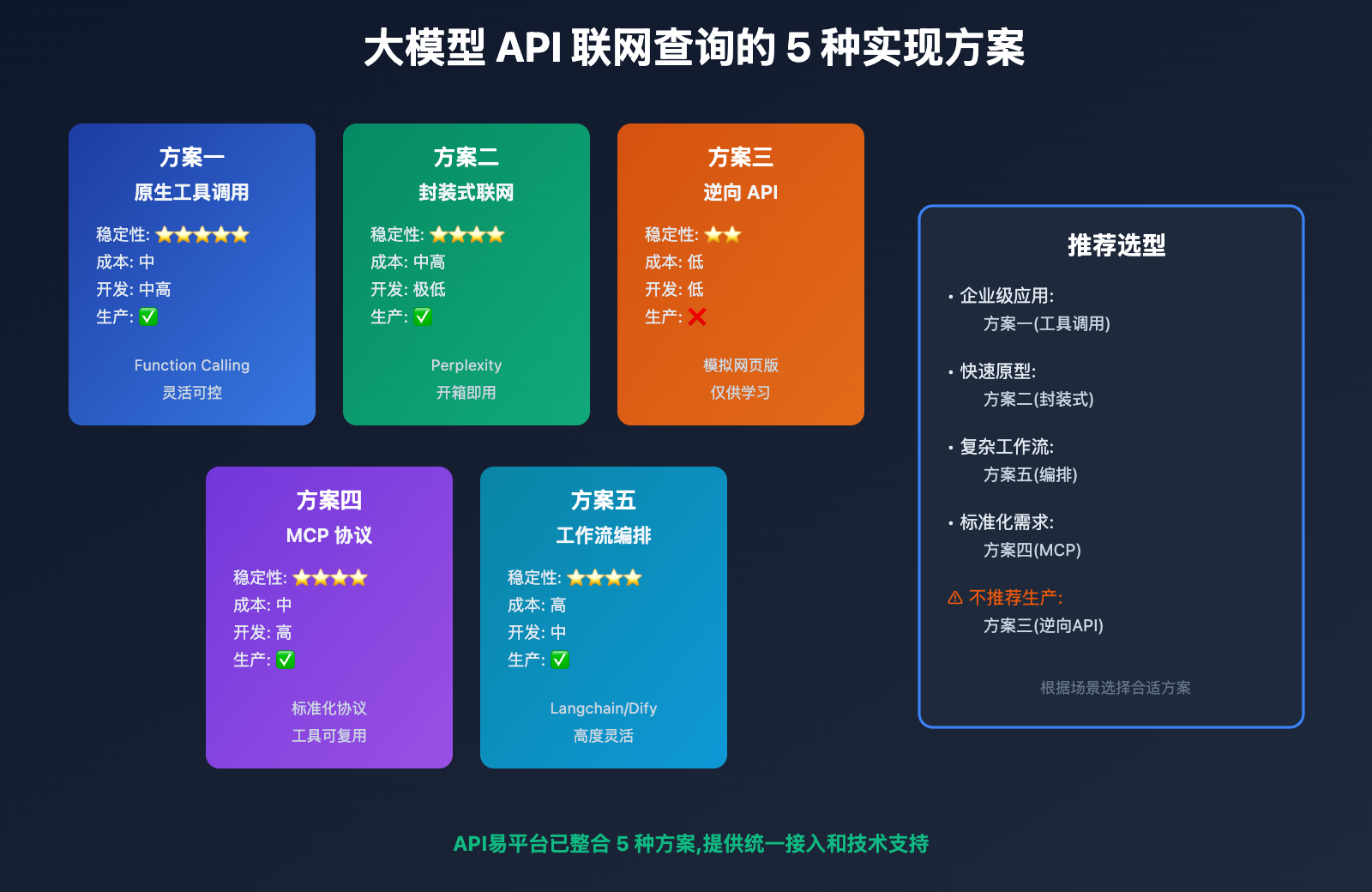
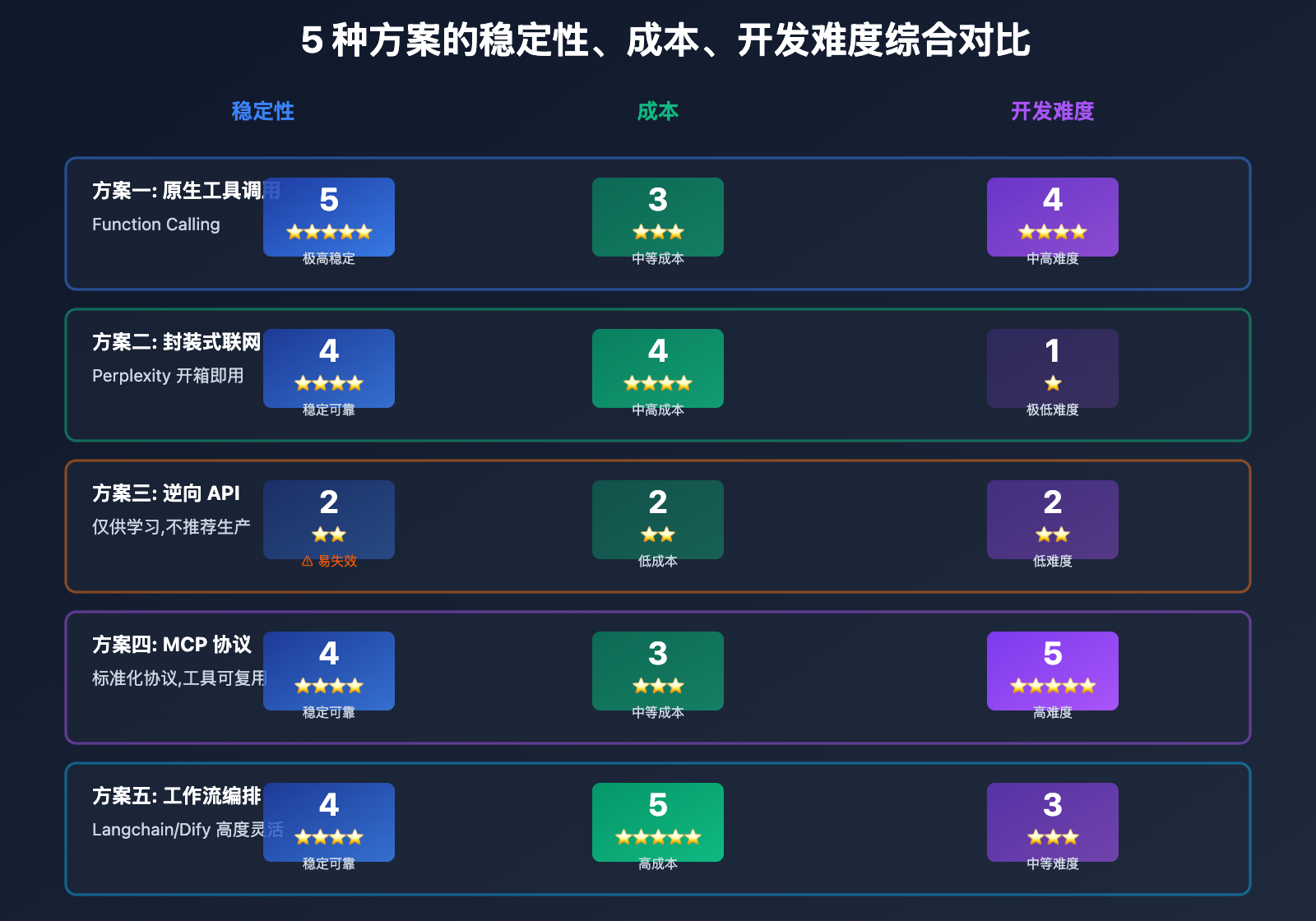
5 种方案全面对比
| 对比维度 | 原生工具调用 | 封装式联网 | 逆向 API | MCP 协议 | 工作流编排 |
|---|---|---|---|---|---|
| 稳定性 | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐ |
| 开发成本 | 高 | 极低 | 低 | 中高 | 中 |
| 运维成本 | 中 | 低 | 低 | 高 | 中高 |
| 灵活性 | ⭐⭐⭐⭐ | ⭐⭐ | ⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 可控性 | ⭐⭐⭐⭐⭐ | ⭐⭐ | ⭐ | ⭐⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
| 生产可用 | ✅ | ✅ | ❌ | ✅ | ✅ |
| 成本范围 | 中 | 中高 | 低 | 中 | 高 |
| 学习曲线 | 中等 | 平缓 | 平缓 | 陡峭 | 中等 |
选型决策树
是否需要高度定制化的联网逻辑?
├─ 是 → 是否需要集成多种工具?
│ ├─ 是 → 方案五: 工作流编排 (Langchain/Dify)
│ └─ 否 → 是否追求标准化?
│ ├─ 是 → 方案四: MCP 协议
│ └─ 否 → 方案一: 原生工具调用
└─ 否 → 是否可接受黑盒处理?
├─ 是 → 方案二: 封装式联网 (Perplexity)
└─ 否 → 是否仅用于学习测试?
├─ 是 → 方案三: 逆向 API (谨慎使用)
└─ 否 → 重新评估需求,推荐方案一或方案二
API易平台的联网解决方案
多方案集成支持
API易平台已整合上述 5 种方案的核心能力:
1. 支持工具调用的模型:
- GPT-4 Turbo / GPT-4o (Function Calling)
- Claude 3.5 Sonnet (Tool Use)
- Gemini 1.5 Pro / Gemini 3 系列 (Function Calling)
2. 内置联网模型:
- Perplexity Sonar 系列
- DeepSeek R1 (部分支持)
3. 逆向联网模型(仅供学习):
- claude-sonnet-4-5-20250929-all
- gpt-4-web (部分渠道)
4. 工作流工具对接:
- 兼容 OpenAI SDK,无缝对接 Langchain
- 提供 Dify 集成文档和示例
快速开始 3 步骤
# 1. 注册 API易账号并获取 API Key
访问 apiyi.com 注册账号,控制台生成 API Key
# 2. 选择联网方案
# 方案 A: 使用工具调用 (GPT-4 Turbo)
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "gpt-4-turbo",
"messages": [{"role": "user", "content": "今天的头条新闻有哪些?"}],
"tools": [
{
"type": "function",
"function": {
"name": "web_search",
"description": "搜索互联网"
}
}
]
}'
# 方案 B: 使用内置联网 (Perplexity)
curl https://api.apiyi.com/v1/chat/completions \
-H "Authorization: Bearer YOUR_API_KEY" \
-d '{
"model": "perplexity-sonar-large",
"messages": [{"role": "user", "content": "今天的头条新闻有哪些?"}]
}'
# 3. 处理返回结果并集成到应用
成本优化建议
1. 根据场景选择方案:
- 简单查询: 使用 Perplexity (成本较低)
- 复杂逻辑: 使用工具调用 + 自建搜索(可控性高)
2. 批量查询优化:
- 使用缓存机制,避免重复搜索相同内容
- 并行调用多个搜索源,取最快结果
3. 充值加赠:
- API易平台充值加赠活动,实际成本约 8 折
💰 成本对比: 通过 API易平台调用 Perplexity 内置联网模型,相比自建工具调用+搜索 API,可节省约 40%-60% 成本。平台统一管理多种模型,简化开发和运维。
最佳实践和选型建议
场景一: 新闻聚合和实时资讯
推荐方案: 封装式联网(Perplexity) 或 工作流编排(Langchain)
理由:
- 新闻查询频率高,封装式联网响应快
- 需要引用来源,Perplexity 自动提供引用
- 如需多源聚合,使用 Langchain 并行搜索
实现建议:
# 使用 Perplexity 快速实现
response = client.chat.completions.create(
model="perplexity-sonar-large",
messages=[{"role": "user", "content": "今天的科技新闻"}]
)
场景二: 金融数据查询和分析
推荐方案: 原生工具调用 + 专业金融 API
理由:
- 金融数据对准确性要求极高
- 需要调用专业金融数据源(Bloomberg、Yahoo Finance)
- 工具调用提供精细控制
实现建议:
tools = [
{
"type": "function",
"function": {
"name": "get_stock_price",
"description": "查询股票实时价格"
}
}
]
# 后端调用 Yahoo Finance API 或其他专业数据源
场景三: 学术研究和知识检索
推荐方案: 工作流编排(Langchain + 向量数据库)
理由:
- 需要多源检索(Google Scholar、arXiv、PubMed)
- 需要信息整合和摘要生成
- 向量数据库支持语义检索
实现建议:
from langchain.vectorstores import Chroma
from langchain.embeddings import OpenAIEmbeddings
# 1. 搜索学术文献
# 2. 向量化存储
# 3. 语义检索
# 4. 大模型生成摘要
场景四: 客户服务和智能问答
推荐方案: 原生工具调用 + 知识库
理由:
- 结合企业内部知识库和外部联网
- 需要精确控制何时联网
- 降低成本,优先使用内部知识
实现建议:
# 1. 先检索内部知识库
# 2. 如无结果,调用联网工具
# 3. 生成答案并存入知识库
常见问题解答
联网查询会增加多少成本?
工具调用方案: 主要成本是搜索 API(如 Google Custom Search API 约 $5/1000 次)+ 模型调用成本
封装式联网: Perplexity 约 $0.005-$0.01/次,相比纯模型调用高 20%-50%
工作流编排: 成本最高,包括多次模型调用+搜索 API,约为纯模型的 2-3 倍
逆向 API 的稳定性如何?
逆向 API 稳定性无法保证:
- 官方更新可能随时导致失效
- 可能触发反爬虫机制
- 不推荐用于生产环境
- 仅适合学习和技术验证
MCP 协议何时可大规模使用?
MCP 协议目前(2025 年初)仍处于早期阶段:
- Claude 支持较好
- 其他模型支持有限
- 生态工具尚不丰富
- 预计 2025 年下半年成熟度提升
推荐关注 Anthropic 官方文档和社区动态。
如何选择搜索 API?
| 搜索 API | 特点 | 成本 | 推荐场景 |
|---|---|---|---|
| Google Custom Search | 结果质量高,覆盖全面 | $5/1000 次 | 通用搜索 |
| Bing Search API | 微软支持,集成简单 | $3/1000 次 | 企业应用 |
| SerpAPI | 聚合多个搜索引擎 | $50/5000 次 | 多源对比 |
| DuckDuckGo | 免费,隐私友好 | 免费 | 低成本方案 |
总结与行动建议
通过本文的深度对比,我们可以得出以下核心结论:
-
原生工具调用是生产环境首选: 稳定性高,可控性强,适合 80% 的企业级应用。
-
封装式联网适合快速原型: Perplexity 等服务开箱即用,适合初创团队和 MVP 验证。
-
逆向 API 仅供学习体验: 稳定性无保障,不推荐用于生产环境。
-
MCP 协议代表未来方向: 标准化和可扩展性强,但当前生态尚不成熟。
-
工作流编排适合复杂应用: Langchain 等工具提供强大的编排能力,适合构建 AI Agent。
选型建议决策:
- 新手开发者: 推荐方案二(封装式联网,如 Perplexity)
- 企业级应用: 推荐方案一(原生工具调用)
- 复杂 AI 系统: 推荐方案五(工作流编排)
- 技术探索: 可尝试方案四(MCP 协议)
- 学习体验: 可尝试方案三(逆向 API,谨慎使用)
行动建议:
- 立即体验: 访问 API易 apiyi.com 注册账号,领取免费试用额度,对比不同方案的实际效果
- 评估需求: 根据应用场景、预算、技术能力选择合适方案
- 小规模测试: 先在非关键场景测试,验证稳定性和成本
- 逐步迁移: 成熟后再应用到生产环境
🎯 最后提醒: 联网查询能力是大模型应用的重要增强,但需要根据实际需求选择合适方案。API易 apiyi.com 平台整合了多种联网解决方案,提供统一的 API 接口和完善的技术支持,是国内开发者实现联网查询的最佳选择。




