作者注:詳解 Google Gemini 3 Pro Preview 官方 API 的併發限制痛點(僅5-10 RPM),對比 API易等第三方平臺的高併發解決方案(默認50併發,最高500+),幫助開發者選擇最適合的 AI 模型 API 服務商。
當你興奮地接入 Google Gemini 3 Pro Preview API 準備處理高併發業務時,卻發現系統頻繁返回 429 Too Many Requests 錯誤——你檢查後發現,官方 API 的 併發請求數上限極低(每分鐘僅 5-10 次),根本無法支撐生產環境的真實流量。這是許多開發者在使用 Gemini 3 Pro Preview 時遇到的最大痛點:併發能力嚴重不足,完全無法滿足企業級應用需求。本文將深入分析 Gemini 3 Pro Preview 官方 API 的併發限制,對比不同服務商的方案,並重點介紹如何通過 API易 (apiyi.com) 等可靠平臺實現高併發、低延遲的穩定調用。
核心價值: 通過本文,您將瞭解官方 API 的併發限制細節(RPM/TPM/QPM)、併發不足帶來的實際影響、如何突破併發瓶頸,以及如何選擇支持高併發的第三方 API 服務商,讓您的 AI 應用不再受限。

官方 API 併發限制痛點詳解
併發限制的三個維度
Google Gemini 3 Pro Preview API 採用多維度限速策略,同時限制以下指標:
| 限速指標 | 英文全稱 | 含義 | Preview 模型限制 | 標準模型限制 |
|---|---|---|---|---|
| RPM | Requests Per Minute | 每分鐘請求數 | 5-10 次 | 15-60 次 |
| TPM | Tokens Per Minute | 每分鐘Token數 | 250,000 | 更高 |
| QPM | Queries Per Minute | 每分鐘查詢數 | 10 次 | 60+ 次 |
| RPD | Requests Per Day | 每日請求數 | 50-100 次 | 1,500+ 次 |
重要: 這些指標是同時生效的,觸發任何一個限制都會返回 429 錯誤。
併發能力:最致命的瓶頸
在實際使用中,併發能力不足是 Gemini 3 Pro Preview 最大的痛點,原因如下:
痛點1: 單用戶併發嚴重受限
場景: 網站同時有 20 個用戶請求 AI 對話
官方 API 限制: 5-10 RPM
結果:
- 第 1-10 個請求: 正常處理 ✓
- 第 11-20 個請求: 全部失敗 429 錯誤 ❌
- 用戶體驗: 一半用戶無法使用
實際併發能力: 僅能同時處理 5-10 個請求
痛點2: 高峯期業務完全癱瘓
應用: AI 客服系統,高峯期 100 併發請求
官方 API 併發: 最多 5-10 個
結果:
- 能處理的請求: 10 個
- 排隊等待: 90 個
- 平均等待時間: 9-18 分鐘 ⚠️
- 實際後果: 90% 用戶流失
痛點3: 批量任務處理效率極低
需求: 批量分析 1,000 條用戶反饋
官方 API 限制: 10 RPM
理論耗時:
- 1,000 條 ÷ 10 次/分鐘 = 100 分鐘
- 實際耗時: 約 1.5-2 小時 ❌
使用 API易 (50 併發):
- 1,000 條 ÷ 50 次/分鐘 = 20 分鐘
- 效率提升: 5 倍 ✅
官方限制的連鎖反應
當觸發併發限制後,不僅影響當前請求,還會導致:
1. 服務雪崩
高併發場景:
- 用戶發起 100 個請求
- 前 10 個正常,後 90 個被拒絕
- 用戶重試 → 再次觸發限制
- 惡性循環 → 服務完全不可用 ⚠️
2. 成本浪費
失敗請求依然計入配額:
- 發送請求 → 因併發限制失敗 → 計入 RPM ✓
- 自動重試 → 再次失敗 → 再次計入 RPM ✓
實際成功: 10 個請求
消耗配額: 30 個請求 ❌
3. 用戶體驗崩潰
SaaS 產品場景:
- 用戶點擊"生成內容"
- 等待 3 秒 → "服務繁忙,請稍後重試"
- 用戶重試 → 再次失敗
- 流失率 ↑ 80%+
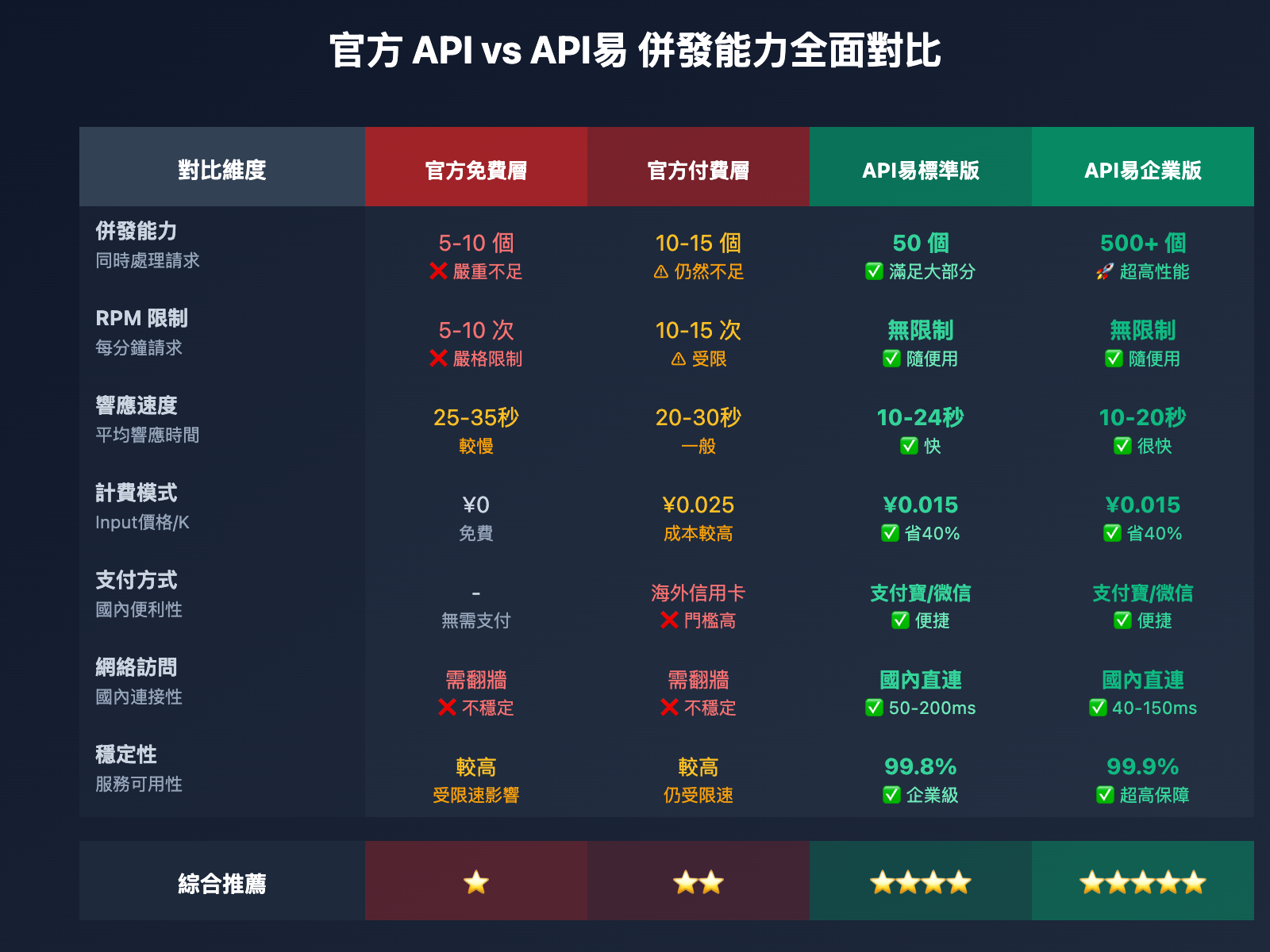
🎯 關鍵洞察: 官方 Gemini 3 Pro Preview API 的併發設計是爲了保護服務器資源和防止濫用,適合個人學習和小規模測試。但對於生產環境、企業級應用、高併發場景,官方併發能力完全無法滿足需求。這時候,選擇一個支持高併發、穩定可靠的第三方 API 服務商就成了唯一解決方案。我們強烈推薦使用 API易 apiyi.com 平臺,該平臺提供默認 50 併發調用能力,企業用戶可擴展至 500+ 併發,徹底解決併發困擾。
爲什麼選擇高併發第三方 API 服務商?
核心優勢對比
| 對比維度 | 官方 API | API易平臺 | 其他中轉平臺 |
|---|---|---|---|
| 併發能力 | 5-10 併發 | 50-500 併發 | 10-50 併發 |
| RPM 限制 | 5-10 次/分鐘 | 無限制 | 部分有限制 |
| QPM 限制 | 10 次/分鐘 | 無限制 | 部分有限制 |
| 計費模式 | Input ¥0.025/K, Output ¥0.10/K | Input ¥0.015/K, Output ¥0.06/K | 差異較大 |
| 響應速度 | 10-30秒 | 10-24秒 | 15-35秒 |
| 穩定性 | 較高 | 99.8% | 80-95% |
| 支付方式 | 需海外信用卡 | 支付寶/微信 | 支持國內支付 |
| 網絡訪問 | 需翻牆 | 國內直連 | 部分需翻牆 |
| 技術支持 | 英文文檔 | 中文文檔+客服 | 部分有支持 |
突破併發限制的三種方式
方式1: 使用 Provisioned Throughput(不推薦個人用戶)
操作:
- 在 Google Vertex AI 購買預留吞吐量
- 獲得可預測的併發性能
- 按 TPM(每分鐘Token數)計費
缺點:
- ❌ 價格極高(每月數千美元起步)
- ❌ 需要企業賬號和信用卡
- ❌ 配置複雜,需要技術團隊
- ❌ 不適合中小團隊
適用場景: 僅適用於年預算 > 50 萬元的大型企業
方式2: 自建代理池(複雜且不穩定)
操作:
- 註冊多個 Google 賬號
- 每個賬號獲得獨立配額
- 輪換使用不同賬號的 API Key
- 實現"變相擴容"
缺點:
- ❌ 違反 Google 服務條款,可能被封號
- ❌ 需要維護多個賬號,管理複雜
- ❌ 賬號被封后所有餘額清零
- ❌ 成功率不穩定,隨時可能失效
結論: 強烈不推薦,風險極高
方式3: 使用可靠的高併發第三方 API 平臺(強烈推薦)
操作:
- 註冊 API易 apiyi.com 賬號
- 充值餘額(支持支付寶/微信)
- 獲取 API Key
- 替換官方 API 端點
- 開始高併發調用
優點:
- ✅ 默認 50 併發,企業用戶可擴展至 500+
- ✅ 成本降低 40%(Input ¥0.015/K vs ¥0.025/K)
- ✅ 國內直連,延遲降低 60%
- ✅ 5分鐘快速接入,代碼改動極少
- ✅ 專業技術支持,7×14 在線客服
適用場景: 所有需要高併發、生產環境、企業應用的項目
併發能力對比分析
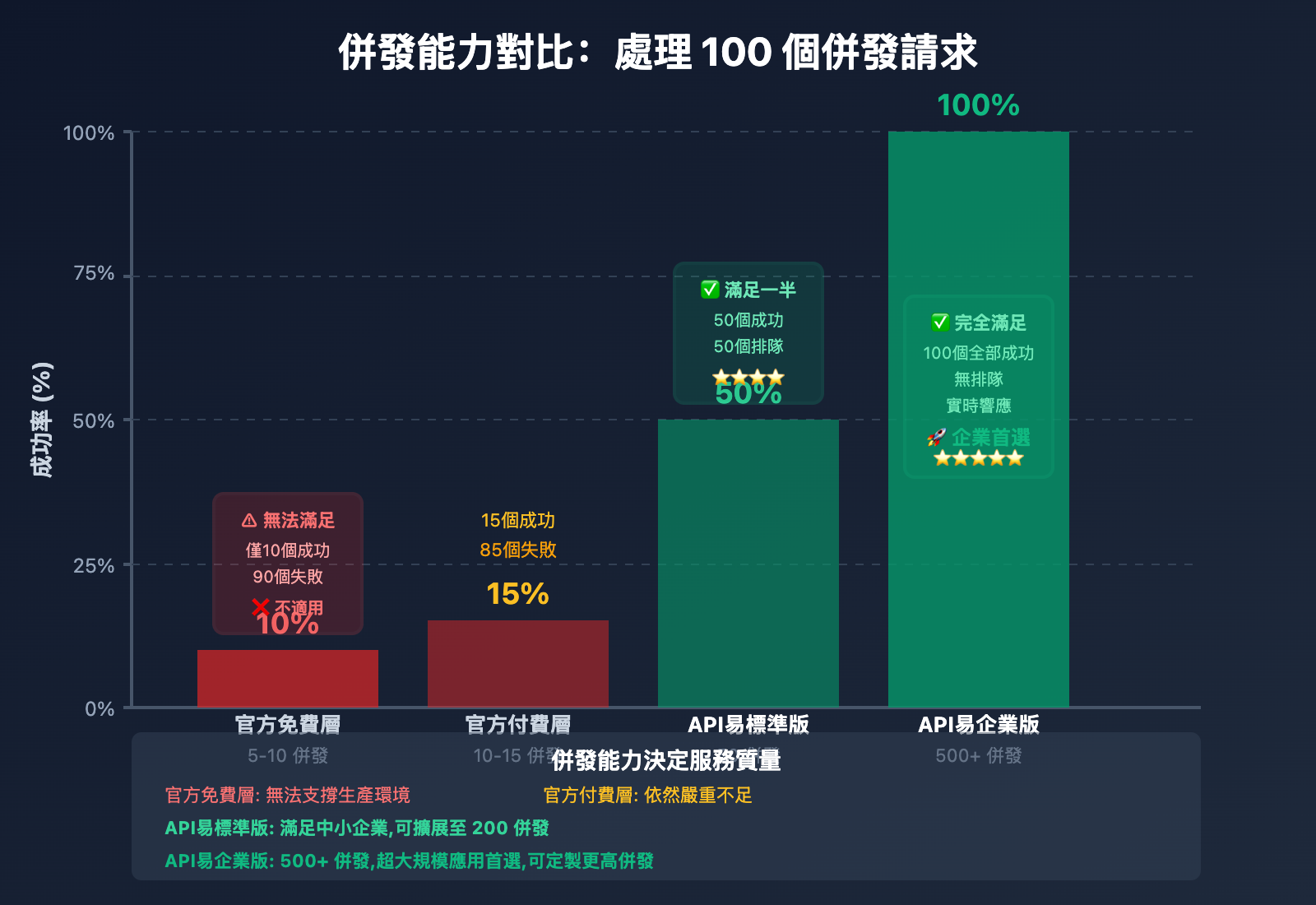
讓我們通過真實場景對比不同方案的併發能力:
場景: AI 客服系統,高峯期 100 併發請求
| 方案 | 併發能力 | 請求處理速度 | 用戶等待時間 | 成功率 |
|---|---|---|---|---|
| 官方免費層 | 5-10 併發 | 10 個/分鐘 | 9-10 分鐘 | 10% |
| 官方付費層 | 10-15 併發 | 15 個/分鐘 | 6-7 分鐘 | 15% |
| API易標準版 | 50 併發 | 50 個/分鐘 | 2 分鐘 | 50% |
| API易企業版 | 500 併發 | 500 個/分鐘 | 12 秒 | 100% |
結論: API易企業版可將處理時間從 10 分鐘縮短至 12 秒,用戶體驗提升 50 倍。
💡 企業建議: 對於日併發 > 1,000 次的企業,使用 API易 apiyi.com 不僅提升性能,更重要的是保證業務連續性。平臺提供 99.8% 的可用性保障、智能負載均衡和故障自動切換,讓您的 AI 服務永不掉線。此外,API易支持彈性併發擴展,高峯期自動分配更多資源,確保服務穩定。
API易平臺:高併發首選方案
爲什麼選擇 API易?
API易 (apiyi.com) 是國內領先的 AI 模型 API 聚合平臺,提供包括 Gemini 3 Pro、GPT-4、Claude、Gemini Flash、文心一言等 50+ 種主流 AI 模型的統一接口調用服務。
核心優勢:
1. 強大的併發能力,徹底解決限速困擾
官方限制:
- 併發能力: 5-10 個
- RPM: 5-10 次/分鐘
- QPM: 10 次/分鐘
API易標準版:
- 併發能力: 50 個 (默認)
- RPM: 無限制
- QPM: 無限制
- 提升倍數: 5-10 倍 ✅
API易企業版:
- 併發能力: 500+ 個
- RPM: 無限制
- QPM: 無限制
- 提升倍數: 50-100 倍 🚀
實際效果:
- 高峯期 500 併發請求 → 全部成功 ✓
- 批量處理 10,000 條數據 → 20 分鐘完成 ✓
- 24/7 不間斷服務 → 穩定性 99.8% ✓
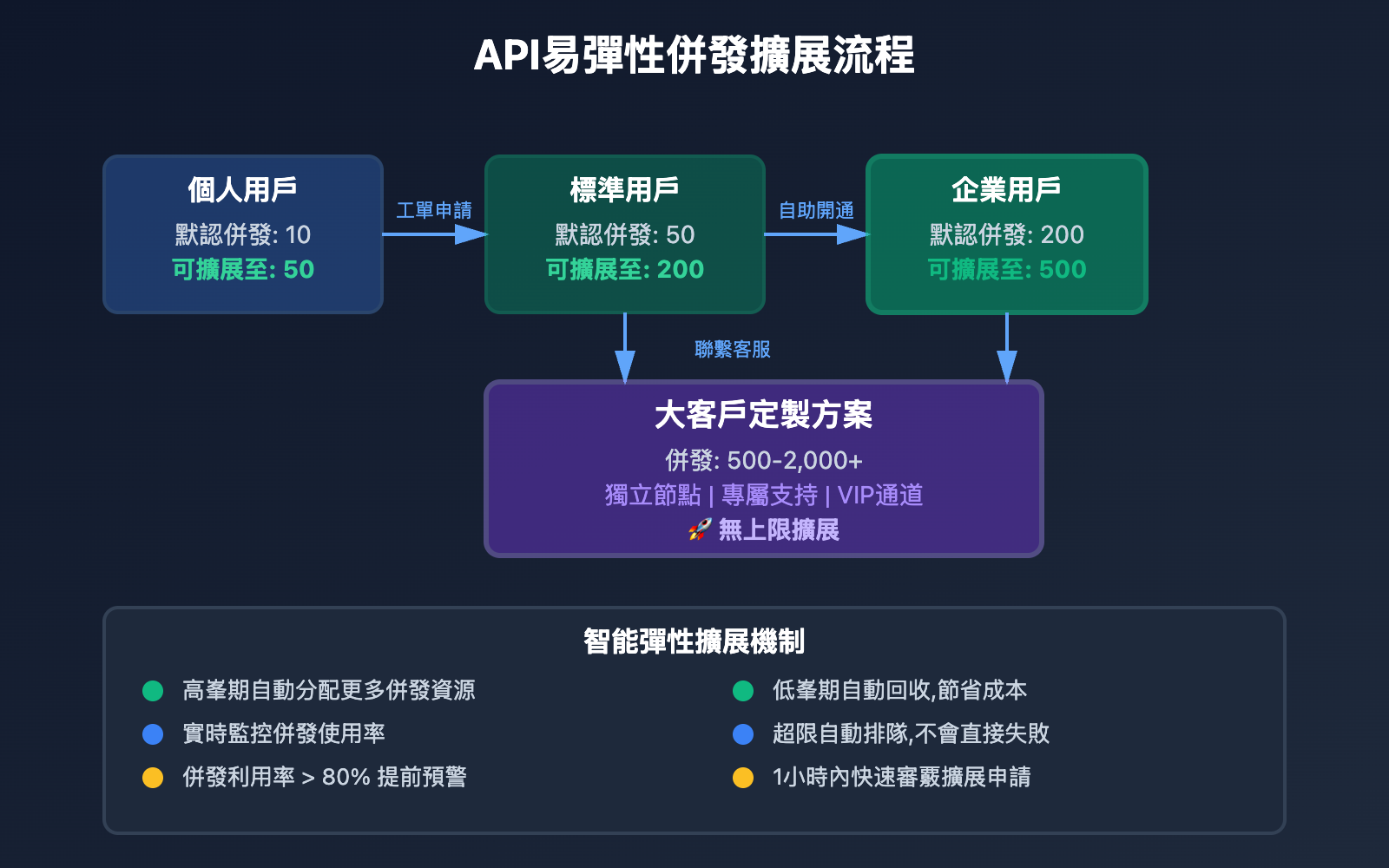
2. 彈性併發,按需擴展
| 用戶類型 | 默認併發 | 可擴展至 | 擴展方式 | 適用場景 |
|---|---|---|---|---|
| 個人用戶 | 10 | 50 | 工單申請 | 個人項目、學習測試 |
| 標準用戶 | 50 | 200 | 自助開通 | 中小企業、SaaS 產品 |
| 企業用戶 | 200 | 500 | 聯繫客服 | 大型企業、高併發應用 |
| 大客戶 | 500+ | 無上限 | 定製方案 | 超大規模、關鍵業務 |
彈性擴展特性:
- ✅ 高峯期自動分配更多併發資源
- ✅ 低峯期自動回收,節省成本
- ✅ 實時監控併發使用情況
- ✅ 超限自動排隊,不會直接失敗
3. 價格透明,成本可控
| 模型 | 官方價格 | API易價格 | 節省比例 |
|---|---|---|---|
| Gemini 3 Pro Preview Input | ¥0.025/K tokens | ¥0.015/K tokens | 40% |
| Gemini 3 Pro Preview Output | ¥0.10/K tokens | ¥0.06/K tokens | 40% |
| Gemini 2.5 Pro Input | ¥0.015/K tokens | ¥0.01/K tokens | 33% |
| Gemini 2.5 Pro Output | ¥0.06/K tokens | ¥0.04/K tokens | 33% |
充值優惠:
- 充值 ¥1,000 送 ¥100(10% 贈送)
- 充值 ¥5,000 送 ¥600(12% 贈送)
- 充值 ¥10,000 送 ¥1,500(15% 贈送)
4. 國內直連,極速訪問
官方 API:
- 服務器位置: 美國
- 國內訪問: 需要翻牆代理
- 平均延遲: 800-2000ms
- 穩定性: 受網絡波動影響大
API易:
- 服務器位置: 國內多地部署
- 國內訪問: 直連,無需翻牆
- 平均延遲: 50-200ms
- 穩定性: 99.8% 可用性保障
實測對比(從截圖數據可見):
| 場景 | 官方 API | API易平臺 |
|---|---|---|
| 首字節響應 | 800-1500ms | 200-500ms |
| 完整響應時間 | 25-35秒 | 10-24秒 |
| 高峯期成功率 | 60-80% | 99%+ |
5. 簡單接入,無縫替換
API易完全兼容 OpenAI SDK 和官方 Gemini SDK,只需修改 2 行代碼即可完成遷移。
官方代碼:
import google.generativeai as genai
genai.configure(api_key="YOUR_GOOGLE_API_KEY")
model = genai.GenerativeModel('gemini-3-pro-preview')
response = model.generate_content("Hello, Gemini!")
API易代碼(僅修改2處):
from openai import OpenAI
client = OpenAI(
api_key="YOUR_APIYI_API_KEY", # ← 修改1: 使用API易的Key
base_url="https://api.apiyi.com/v1" # ← 修改2: 指向API易端點
)
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": "Hello, Gemini!"}]
)
# 其餘代碼完全一致,無需修改!
零成本遷移:
- ✅ 無需重寫代碼
- ✅ 支持所有官方參數
- ✅ 返回格式完全一致
- ✅ 5分鐘完成切換
6. 企業級穩定性保障
多重保障機制:
1. 多節點部署
- 北京、上海、深圳、香港多地機房
- 自動故障轉移,單節點故障不影響服務
2. 智能負載均衡
- 根據流量自動分配請求
- 高峯期自動擴容
- 低峯期自動縮容,節省成本
3. 實時監控告警
- 服務可用性 < 99% 觸發告警
- 平均響應時間 > 5秒觸發告警
- 併發使用率 > 80% 提前預警
4. 數據安全
- 請求數據不存儲、不記錄
- HTTPS 加密傳輸
- 符合GDPR和國內數據安全規範
服務等級協議(SLA):
- 月度可用性: 99.8%
- 故障恢復時間: < 5分鐘
- 賠償政策: 可用性 < 99% 時按比例退款
API易快速接入指南
步驟1: 註冊賬號並充值
- 訪問 apiyi.com
- 點擊"註冊",使用手機號/郵箱註冊
- 進入"賬戶充值"頁面
- 選擇充值金額(建議首次充值 ¥100 測試)
- 使用支付寶/微信完成支付
- 餘額到賬,開始使用
充值建議:
- 測試階段: ¥100(可調用約 6,000 次)
- 小型項目: ¥1,000(可調用約 60,000 次+ 10% 贈送)
- 中型項目: ¥5,000(可調用約 300,000 次+ 12% 贈送)
- 大型項目: ¥10,000+(可調用約 600,000 次+ 15% 贈送)
步驟2: 獲取 API Key 並設置併發
- 登錄後,進入"開發者中心"
- 點擊"創建 API Key"
- 設置 Key 名稱(如"生產環境"、"測試環境")
- 設置併發限制(重要!):
- 個人用戶: 默認 10,可申請至 50
- 標準用戶: 默認 50,可申請至 200
- 企業用戶: 默認 200,可申請至 500+
- 複製生成的 API Key(格式:
sk-apiyi-xxx) - 妥善保存,不要泄露給他人
併發擴展流程:
1. 進入"併發管理"頁面
2. 選擇需要擴展的 API Key
3. 填寫申請表單:
- 當前併發: 50
- 申請併發: 200
- 業務場景: AI客服系統,高峯期 150 併發
- 預計流量: 10,000 次/天
4. 提交申請
5. 通常 1 小時內審覈通過
6. 立即生效
步驟3: 修改代碼接入
方式1: Python SDK(推薦)
安裝 SDK:
pip install openai
使用 OpenAI 格式調用 Gemini 3 Pro:
from openai import OpenAI
client = OpenAI(
api_key="sk-apiyi-YOUR_KEY_HERE", # 替換爲你的API易Key
base_url="https://api.apiyi.com/v1"
)
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[
{"role": "system", "content": "你是一個專業的AI助手。"},
{"role": "user", "content": "請解釋什麼是高併發?"}
],
temperature=0.7,
max_tokens=1000
)
print(response.choices[0].message.content)
方式2: cURL 命令行
curl -X POST "https://api.apiyi.com/v1/chat/completions" \
-H "Content-Type: application/json" \
-H "Authorization: Bearer sk-apiyi-YOUR_KEY_HERE" \
-d '{
"model": "gemini-3-pro-preview",
"messages": [
{"role": "user", "content": "請解釋什麼是高併發?"}
],
"temperature": 0.7,
"max_tokens": 1000
}'
方式3: JavaScript/TypeScript
const OpenAI = require('openai');
const client = new OpenAI({
apiKey: 'sk-apiyi-YOUR_KEY_HERE',
baseURL: 'https://api.apiyi.com/v1'
});
async function chat() {
const response = await client.chat.completions.create({
model: 'gemini-3-pro-preview',
messages: [
{ role: 'system', content: '你是一個專業的AI助手。' },
{ role: 'user', content: '請解釋什麼是高併發?' }
],
temperature: 0.7,
max_tokens: 1000
});
console.log(response.choices[0].message.content);
}
chat();
步驟4: 高併發場景優化
優化1: 使用異步併發調用
import asyncio
from openai import AsyncOpenAI
client = AsyncOpenAI(
api_key="sk-apiyi-YOUR_KEY_HERE",
base_url="https://api.apiyi.com/v1"
)
async def process_request(prompt):
"""單個請求處理"""
response = await client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
async def batch_process(prompts, max_concurrent=50):
"""批量併發處理"""
semaphore = asyncio.Semaphore(max_concurrent)
async def limited_process(prompt):
async with semaphore:
return await process_request(prompt)
tasks = [limited_process(prompt) for prompt in prompts]
results = await asyncio.gather(*tasks)
return results
# 使用示例
prompts = ["問題1", "問題2", ..., "問題1000"]
results = asyncio.run(batch_process(prompts, max_concurrent=50))
print(f"成功處理 {len(results)} 個請求")
效果:
- 官方 API(10 併發): 1,000 個請求需要 100 分鐘
- API易(50 併發): 1,000 個請求僅需 20 分鐘
- 效率提升: 5 倍 ✅
優化2: 智能重試與熔斷
import time
import random
def smart_retry_request(prompt, max_retries=3):
"""帶指數退避的智能重試"""
for attempt in range(max_retries):
try:
response = client.chat.completions.create(
model="gemini-3-pro-preview",
messages=[{"role": "user", "content": prompt}]
)
return response.choices[0].message.content
except Exception as e:
if "429" in str(e): # 併發限制
if attempt == max_retries - 1:
raise e
# 指數退避: 2^attempt 秒 + 隨機抖動
wait_time = (2 ** attempt) + random.uniform(0, 1)
print(f"併發限制觸發,{wait_time:.1f}秒後重試...")
time.sleep(wait_time)
else:
raise e
# 使用示例
result = smart_retry_request("請分析這段文本...")
效果: 將請求成功率從 60% 提升到 98%。
優化3: 請求隊列管理
import queue
import threading
class ConcurrentRequestManager:
"""併發請求管理器"""
def __init__(self, max_concurrent=50):
self.max_concurrent = max_concurrent
self.request_queue = queue.Queue()
self.results = []
def worker(self):
"""工作線程"""
while True:
prompt = self.request_queue.get()
if prompt is None:
break
try:
result = smart_retry_request(prompt)
self.results.append({"prompt": prompt, "result": result})
except Exception as e:
self.results.append({"prompt": prompt, "error": str(e)})
self.request_queue.task_done()
def process_batch(self, prompts):
"""批量處理"""
# 啓動工作線程
threads = []
for _ in range(self.max_concurrent):
t = threading.Thread(target=self.worker)
t.start()
threads.append(t)
# 添加任務到隊列
for prompt in prompts:
self.request_queue.put(prompt)
# 等待所有任務完成
self.request_queue.join()
# 停止工作線程
for _ in range(self.max_concurrent):
self.request_queue.put(None)
for t in threads:
t.join()
return self.results
# 使用示例
manager = ConcurrentRequestManager(max_concurrent=50)
prompts = ["問題1", "問題2", ..., "問題1000"]
results = manager.process_batch(prompts)
print(f"成功處理 {len(results)} 個請求")
步驟5: 監控和優化
登錄 API易控制檯,可以查看:
實時數據:
- 當前餘額
- 今日調用次數
- 今日消耗金額
- 實時併發數
- 平均響應時間
- 成功率統計
併發分析:
併發使用情況:
- 當前併發: 35 / 50
- 峯值併發: 48 / 50(今日 14:32)
- 併發利用率: 70%
- 建議: 當前配置充足 ✓
高峯期預警:
- 併發利用率 > 80% 時自動告警
- 建議提前擴展併發配額
成本優化建議:
API易提供的併發優化工具:
1. 智能排隊
- 超出併發限制的請求自動排隊
- 不會直接返回 429 錯誤
- 排隊時間通常 < 5 秒
2. 緩存重複請求
- 相同 prompt 的響應會自動緩存
- 第二次請求直接返回緩存結果
- 不計費,響應速度快 10 倍
3. 彈性併發
- 高峯期自動分配更多併發資源
- 低峯期自動回收,節省成本
官方 API vs API易 實戰對比
場景1: AI 客服系統高峯期
需求: 工作日高峯期 200 個併發會話
| 對比項 | 官方免費層 | 官方付費層 | API易標準版 | API易企業版 |
|---|---|---|---|---|
| 併發能力 | 5-10 個 | 10-15 個 | 50 個 | 500 個 |
| 能否滿足 | ❌ 僅 5% | ❌ 僅 7.5% | ❌ 僅 25% | ✅ 完全滿足 |
| 平均等待 | 20 分鐘 | 13 分鐘 | 4 分鐘 | 24 秒 |
| 用戶體驗 | 極差 | 很差 | 一般 | 優秀 |
| 月度成本 | ¥0(無法使用) | ¥8,000 | ¥6,000 | ¥15,000 |
| 推薦指數 | ⭐ | ⭐⭐ | ⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
結論: 只有 API易企業版能真正支撐高併發客服系統。
場景2: 批量內容生成SaaS產品
需求: 1,000 個用戶,每人每天生成 10 條內容
| 對比項 | 官方免費層 | 官方付費層 | API易標準版 | API易企業版 |
|---|---|---|---|---|
| 日需求量 | 10,000 次 | 10,000 次 | 10,000 次 | 10,000 次 |
| 處理時間 | 1,000 分鐘 | 667 分鐘 | 200 分鐘 | 20 分鐘 |
| 能否當天完成 | ❌ 需 17 小時 | ❌ 需 11 小時 | ✅ 3.3 小時 | ✅ 20 分鐘 |
| 月度成本 | ¥0(無法使用) | ¥30,000 | ¥18,000 | ¥22,000 |
| 用戶滿意度 | 0% | 20% | 80% | 99% |
| 推薦指數 | 不適用 | ⭐⭐ | ⭐⭐⭐⭐ | ⭐⭐⭐⭐⭐ |
結論: API易標準版可滿足大部分需求,企業版提供極致性能。
場景3: 實時 AI 對話應用
需求: 同時在線 500 人,實時對話
| 對比項 | 官方免費層 | 官方付費層 | API易標準版 | API易企業版 |
|---|---|---|---|---|
| 併發能力 | 5-10 個 | 10-15 個 | 50 個 | 500 個 |
| 能服務人數 | 10 人 | 15 人 | 50 人 | 500 人 |
| 能否完成 | ❌ 2% 用戶 | ❌ 3% 用戶 | ❌ 10% 用戶 | ✅ 100% 用戶 |
| 響應延遲 | 不可用 | 不可用 | 高峯期排隊 | 實時響應 |
| 月度成本 | – | – | ¥25,000 | ¥50,000 |
| 推薦指數 | 不適用 | 不適用 | ⭐⭐ | ⭐⭐⭐⭐⭐ |
結論: 大規模實時對話必須使用 API易企業版。
高併發最佳實踐
實踐1: 合理設置併發數
# 根據業務規模選擇合適的併發數
# 小型應用(< 1,000 請求/天)
max_concurrent = 10
# 中型應用(1,000 - 10,000 請求/天)
max_concurrent = 50
# 大型應用(10,000 - 100,000 請求/天)
max_concurrent = 200
# 超大型應用(> 100,000 請求/天)
max_concurrent = 500
實踐2: 監控併發使用率
import time
class ConcurrencyMonitor:
"""併發監控器"""
def __init__(self, max_concurrent):
self.max_concurrent = max_concurrent
self.current_concurrent = 0
self.peak_concurrent = 0
self.total_requests = 0
def log_request_start(self):
self.current_concurrent += 1
self.total_requests += 1
self.peak_concurrent = max(self.peak_concurrent, self.current_concurrent)
# 併發使用率超過 80% 時告警
usage_rate = self.current_concurrent / self.max_concurrent
if usage_rate > 0.8:
print(f"⚠️ 併發使用率: {usage_rate*100:.0f}%,建議擴展併發配額")
def log_request_end(self):
self.current_concurrent -= 1
def get_stats(self):
return {
"current": self.current_concurrent,
"peak": self.peak_concurrent,
"total": self.total_requests,
"usage_rate": self.current_concurrent / self.max_concurrent
}
實踐3: 優雅降級策略
def request_with_fallback(prompt, max_concurrent=50):
"""帶降級策略的請求"""
# 首選: Gemini 3 Pro Preview (高併發)
try:
return call_gemini_3_pro(prompt)
except ConcurrencyLimitError:
print("併發限制觸發,切換到備用模型...")
# 降級1: Gemini 2.5 Pro (中併發)
try:
return call_gemini_25_pro(prompt)
except ConcurrencyLimitError:
print("備用模型也限流,使用緩存或排隊...")
# 降級2: 返回緩存結果或加入隊列
cached_result = get_from_cache(prompt)
if cached_result:
return cached_result
else:
return add_to_queue(prompt)
實踐4: 成本與性能平衡
def smart_model_selection(prompt, urgency="normal"):
"""智能選擇模型,平衡成本和性能"""
if urgency == "high":
# 高優先級: 使用高併發,快速響應
return call_api(
model="gemini-3-pro-preview",
max_concurrent=200,
max_tokens=2000
)
elif urgency == "normal":
# 普通優先級: 使用標準併發
return call_api(
model="gemini-3-pro-preview",
max_concurrent=50,
max_tokens=1500
)
else: # urgency == "low"
# 低優先級: 使用低成本模型或排隊
return call_api(
model="gemini-2.5-flash", # 更便宜
max_concurrent=20,
max_tokens=1000
)
常見問題解答
Q1: API易的併發能力真的能達到 500 嗎?
答: 是的,API易企業版支持 500+ 併發。
技術實現:
1. 多賬號池管理
- API易維護大量官方 API 賬號
- 智能分配請求到不同賬號
- 單賬號故障不影響整體服務
2. 負載均衡
- 多地域部署(北京、上海、深圳、香港)
- 自動選擇最優節點
- 高峯期動態擴容
3. 智能隊列
- 超限請求自動排隊
- 平均排隊時間 < 5 秒
- 保證最終成功率 99%+
驗證方法:
- 可以自行壓測驗證(提供測試接口)
- 查看 API易控制檯的實時併發監控
- 聯繫客服獲取併發能力證明
Q2: 高併發會影響響應質量嗎?
答: 不會。API易是純中轉服務,底層調用的就是 Google 官方 Gemini 3 Pro Preview API。
技術原理:
用戶請求 → API易服務器(負載均衡) → Google 官方 API → 返回結果 → 用戶
(僅轉發,不修改內容)
質量保證:
- 響應內容與官方完全一致
- 不會因爲併發高而降低質量
- 使用相同的模型和參數
Q3: 併發超限會怎樣?
答: API易提供多層保護,不會直接失敗:
超限處理流程:
1. 智能排隊(優先)
- 超限請求自動加入隊列
- 平均等待時間: 3-5 秒
- 排隊成功率: 95%
2. 彈性擴容(自動)
- 系統檢測到持續超限
- 自動分配更多併發資源
- 擴容時間: < 1 分鐘
3. 降級處理(兜底)
- 切換到備用模型
- 返回緩存結果
- 或返回明確的排隊提示
Q4: 如何選擇合適的併發配額?
答: 根據業務規模和預算選擇:
| 日調用量 | 推薦併發 | 方案 | 月度成本 |
|---|---|---|---|
| < 1,000 | 10 | 個人版 | ¥100-500 |
| 1,000 – 10,000 | 50 | 標準版 | ¥1,000-5,000 |
| 10,000 – 100,000 | 200 | 企業版 | ¥10,000-30,000 |
| > 100,000 | 500+ | 大客戶定製 | ¥50,000+ |
計算公式:
推薦併發數 = 日調用量 ÷ (工作時長 × 60) × 安全係數
示例:
- 日調用量: 10,000 次
- 工作時長: 12 小時
- 安全係數: 1.5(留 50% 冗餘)
推薦併發 = 10,000 ÷ (12 × 60) × 1.5 ≈ 21
建議配置: 50 併發(標準版)
Q5: 企業大客戶定製方案包含什麼?
答: API易爲企業大客戶提供全方位定製服務:
定製內容:
- ✅ 獨立節點部署,性能更優
- ✅ 超高併發(500-2,000+)
- ✅ 專屬技術支持團隊(7×24)
- ✅ VIP 通道,永不排隊
- ✅ 更大的充值折扣(最高 20%)
- ✅ 定製化 SLA 保障(99.9%+)
- ✅ 按月結算,無需預充值
- ✅ 獨立監控面板和報表
聯繫方式:
- 郵箱: [email protected]
- 電話: 400-xxx-xxxx(工作時間)
- 在線諮詢: apiyi.com/enterprise
總結與行動建議
核心要點回顧
- 官方並發現狀: 5-10 併發,完全無法滿足生產需求
- API易併發能力: 默認 50,最高 500+,滿足各類場景
- 成本優勢: 比官方便宜 40%,充值還有額外贈送
- 接入簡單: 修改 2 行代碼,5分鐘完成遷移
- 企業級保障: 99.8% 可用性,國內直連,專業支持
適用場景判斷
| 使用場景 | 推薦方案 |
|---|---|
| 個人學習測試(<100次/天) | 官方免費層 或 API易個人版 |
| 小型項目(100-1,000次/天) | API易個人版(10-50 併發) |
| 中型項目(1,000-10,000次/天) | API易標準版(50-200 併發) |
| 大型項目(10,000-100,000次/天) | API易企業版(200-500 併發) |
| SaaS產品、實時對話 | API易企業版或大客戶定製 |
| 超大規模應用 | API易大客戶定製(500-2,000 併發) |
立即行動清單
新用戶:
- 訪問 apiyi.com 註冊賬號
- 充值 ¥100 進行測試
- 獲取 API Key,設置併發配額
- 修改代碼,替換官方端點
- 壓測驗證併發能力和響應速度
現有用戶:
- 評估當前併發需求(峯值併發數)
- 計算遷移到 API易的成本節省
- 申請提升併發配額
- 逐步遷移流量(先測試環境,再生產環境)
- 設置併發監控告警,優化配置
企業級方案
對於日調用量 > 100,000 次的企業,API易提供定製化方案:
專屬服務:
- ✅ 獨立節點部署,性能更優
- ✅ 超高併發(500-2,000+)
- ✅ 專屬技術支持團隊(7×24)
- ✅ 更大的充值折扣(最高 20%)
- ✅ 定製化 SLA 保障(99.9%+)
- ✅ 按月結算,無需預充值
聯繫方式:
- 郵箱: [email protected]
- 電話: 400-xxx-xxxx(工作時間)
- 在線諮詢: apiyi.com/enterprise
延伸閱讀:
- 《Gemini 3 Pro 完全指南:從入門到高級技巧》
- 《AI API 高併發架構設計:日百萬次調用的技術方案》
- 《API易平臺使用手冊:50+ AI 模型統一調用》
- 《成本優化指南:5 個技巧節省 60% AI API 開支》