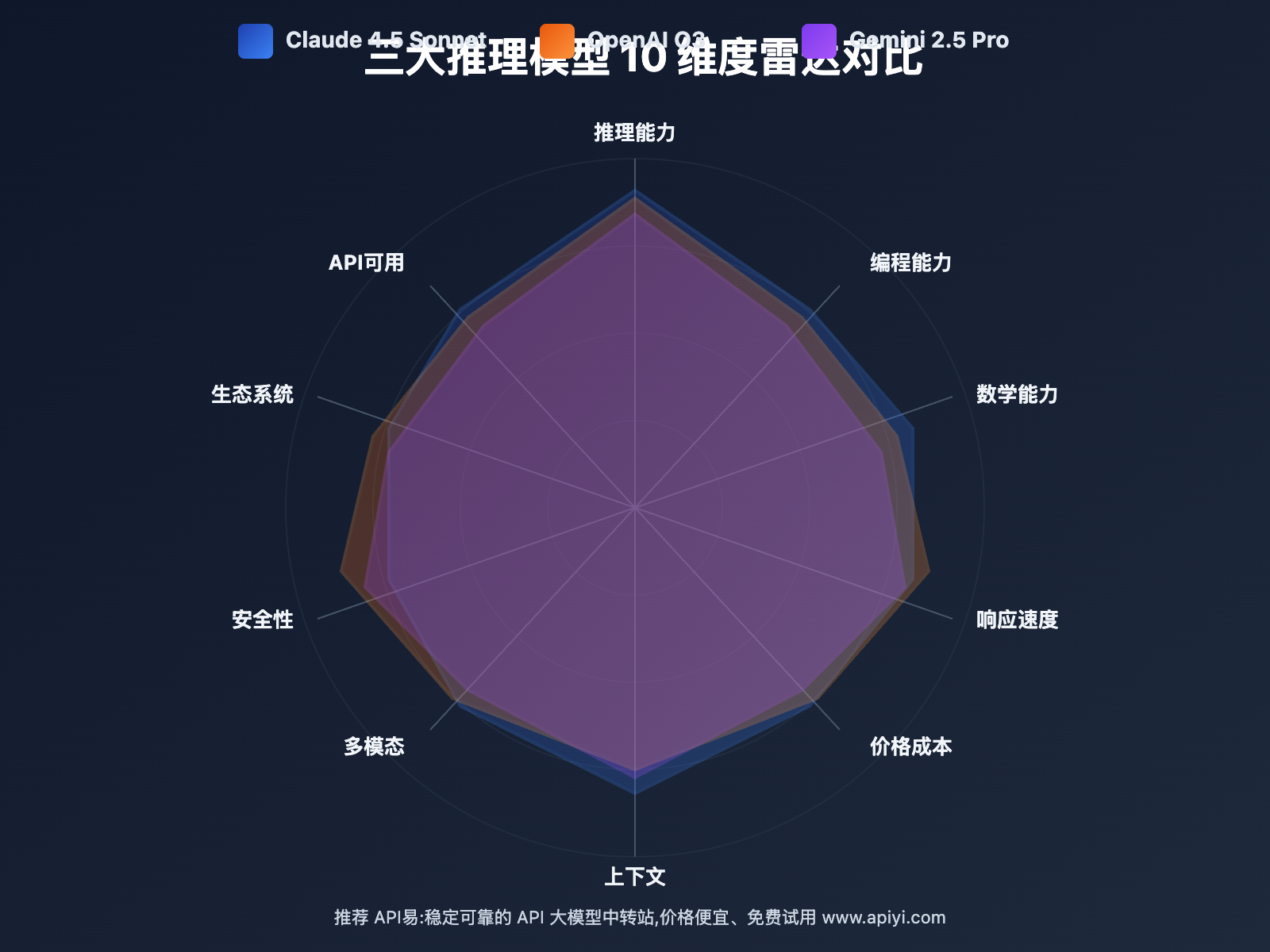
作者注:全面对比 Claude 4.5 Sonnet、OpenAI O3、Gemini 2.5 Pro 三大推理模型的 10 大维度,包括推理能力、编程性能、价格成本,提供场景化选型建议
2025 年,AI 大模型领域进入了 推理能力竞赛 的白热化阶段。Anthropic 的 Claude 4.5 Sonnet、OpenAI 的 O3、Google 的 Gemini 2.5 Pro 三大旗舰推理模型同时发力,在编程、数学、科学推理等核心能力上展开激烈竞争。
本文将从 推理能力、编程性能、数学能力、响应速度、价格成本、上下文长度、多模态支持、安全性、生态系统、API 可用性 等 10 个关键维度,对三大模型进行全面深度对比,并提供不同场景下的选型决策建议。
核心价值:看完本文,你将明确知道在编程辅助、科学研究、企业应用等不同场景下,应该选择哪个推理模型,以及如何通过 API易 apiyi.com 平台实现统一接入和灵活切换。
Claude 4.5、O3、Gemini 2.5 背景介绍
2025 年成为 AI 推理模型的 关键突破年。三大科技巨头几乎同时发布了各自的旗舰推理模型,标志着大模型从"语言理解"向"复杂推理"的战略转型。
Claude 4.5 Sonnet:全球最强编程模型
发布时间: 2025 年 9 月 29 日
开发公司: Anthropic
核心定位: 全球最强编程模型、复杂 Agent 构建的最佳选择
Claude 4.5 Sonnet 在 SWE-bench Verified 评测中取得业界领先成绩,代码编辑错误率从前代的 9% 降至 0%,实现了编程能力的质的飞跃。该模型在 OSWorld 基准测试中达到 61.4%,相比 4 个月前提升了 19.2 个百分点,能够自主执行多步骤计算机任务并保持超过 30 小时的任务聚焦。
突破性功能:
- Checkpoints: 允许在长时间任务中保存中间状态和回溯
- Context Editing: 智能清理过时信息,节省 30-50% token 成本
- Memory Tools: 跨会话持久化记忆,支持项目上下文延续
- Native File Creation: 原生文件创建和管理能力
安全等级: ASL-3 认证,被官方定位为"迄今最对齐的前沿模型"
OpenAI O3:极致推理性能的探索者
发布时间: 2025 年初
开发公司: OpenAI
核心定位: 极致推理能力、科学研究的最佳助手
O3 是 OpenAI 推理模型系列的最新成员,在 GPQA(Graduate-Level Google-Proof Q&A)等科学推理基准上取得了突破性成绩。该模型通过 强化推理链 技术,能够在复杂科学问题、高等数学和逻辑推理任务中展现出接近人类专家的表现。
核心特性:
- 深度思维链: 多步骤推理过程透明可追溯
- 科学推理优化: 在物理、化学、生物学等领域专门优化
- 数学能力突破: MATH 基准测试接近满分水平
- 可调推理深度: 支持 low、medium、high 三档推理计算量
适用场景: 学术研究、科学计算、复杂数学建模
Gemini 2.5 Pro:多模态推理的集大成者
发布时间: 2025 年中
开发公司: Google DeepMind
核心定位: 最强多模态推理能力、超长上下文处理
Gemini 2.5 Pro 是 Google 在多模态推理领域的旗舰产品,支持高达 200 万 tokens 的上下文窗口,能够同时处理文本、图像、音频和视频输入。该模型在跨模态推理任务中表现出色,可以在海量文档中精准定位信息并进行复杂分析。
核心特性:
- 超长上下文: 200 万 tokens,可处理整本书籍或大型代码库
- 原生多模态: 图像、音频、视频理解能力业界领先
- Code Execution: 内置代码执行环境,实时验证结果
- Grounding: 联网搜索能力,确保信息时效性
适用场景: 大规模文档分析、多模态内容创作、企业知识管理
Claude 4.5 vs O3 vs Gemini 2.5:10 维度深度对比
以下是 Claude 4.5 Sonnet、OpenAI O3、Gemini 2.5 Pro 在 10 个关键维度的全面对比:
| 对比维度 | Claude 4.5 Sonnet | OpenAI O3 | Gemini 2.5 Pro | 综合评价 |
|---|---|---|---|---|
| 推理能力 | ⭐⭐⭐⭐⭐ 业界顶尖 | ⭐⭐⭐⭐⭐ 科学推理最强 | ⭐⭐⭐⭐ 多模态推理优秀 | O3 和 Claude 4.5 并列第一 |
| 编程能力 | ⭐⭐⭐⭐⭐ 官方认证第一 | ⭐⭐⭐⭐ 优秀 | ⭐⭐⭐⭐ 优秀 | Claude 4.5 明显领先 |
| 数学能力 | ⭐⭐⭐⭐ 显著提升 | ⭐⭐⭐⭐⭐ 接近满分 | ⭐⭐⭐⭐ 良好 | O3 数学能力最强 |
| 响应速度 | ⭐⭐⭐⭐ 2-4秒 | ⭐⭐⭐ 5-15秒(深度推理) | ⭐⭐⭐⭐ 2-5秒 | Claude 4.5 和 Gemini 2.5 更快 |
| 价格成本 | ⭐⭐⭐ $3/$15 | ⭐⭐ $15/$60 | ⭐⭐⭐⭐ $1.25/$5 | Gemini 2.5 性价比最高 |
| 上下文长度 | ⭐⭐⭐⭐ 200K tokens | ⭐⭐⭐ 128K tokens | ⭐⭐⭐⭐⭐ 200万 tokens | Gemini 2.5 超长上下文 |
| 多模态支持 | ⭐⭐⭐ 图像(研究预览) | ⭐⭐⭐ 图像 | ⭐⭐⭐⭐⭐ 全模态 | Gemini 2.5 多模态最强 |
| 安全性 | ⭐⭐⭐⭐⭐ ASL-3 最对齐 | ⭐⭐⭐⭐ 良好 | ⭐⭐⭐⭐ 良好 | Claude 4.5 安全性领先 |
| 生态系统 | ⭐⭐⭐⭐ 快速发展 | ⭐⭐⭐⭐⭐ 最成熟 | ⭐⭐⭐⭐ Google 生态 | OpenAI 生态最丰富 |
| API可用性 | ⭐⭐⭐⭐⭐ 全球可用 | ⭐⭐⭐⭐ 部分限制 | ⭐⭐⭐⭐ 逐步开放 | Claude 4.5 API 最稳定 |
🔥 维度详解:推理能力对比
Claude 4.5 Sonnet:在复杂多步推理任务中表现出色,能够维持超过 30 小时的任务聚焦,特别适合需要长时间连续推理的场景。其 Checkpoints 功能允许在推理过程中保存中间状态,大幅提升了复杂推理任务的可靠性。
OpenAI O3:在科学推理领域一骑绝尘,GPQA 基准测试成绩接近或超越人类专家水平。其强化推理链技术能够展示详细的推理过程,对于学术研究和科学计算场景尤其有价值。
Gemini 2.5 Pro:在跨模态推理任务中展现独特优势,能够同时处理文本、图像和视频信息并进行综合推理,适合需要多源信息融合的场景。
🎯 选择建议: 如果主要场景是编程和 Agent 开发,选择 Claude 4.5;如果是科学研究和数学建模,选择 O3;如果需要处理多模态内容,选择 Gemini 2.5。我们建议通过 API易 apiyi.com 平台同时接入三大模型,根据具体任务灵活选择,该平台支持统一接口调用,便于快速对比和切换。
⚡ 维度详解:编程能力对比
Claude 4.5 Sonnet 在编程领域的霸主地位几乎无可撼动:
SWE-bench Verified 成绩:
- Claude 4.5: 业界第一 (State-of-the-art)
- O3: 优秀但未公布具体数据
- Gemini 2.5: 优秀但略逊于 Claude 4.5
代码编辑准确率:
- Claude 4.5: 错误率 0% (相比前代 9% 的质的飞跃)
- O3: 优秀,但具体数据未公布
- Gemini 2.5: 优秀,但在复杂重构任务中稍弱
特色功能对比:
- Claude 4.5: Native File Creation、Agent SDK、Memory Tools
- O3: 推理增强的代码生成,适合算法实现
- Gemini 2.5: Code Execution 实时验证、多文件协同编辑
💰 维度详解:价格成本对比
价格对比是企业级应用的关键决策因素:
| 模型 | 输入价格 | 输出价格 | 月成本估算* | 性价比评级 |
|---|---|---|---|---|
| Claude 4.5 Sonnet | $3/百万 tokens | $15/百万 tokens | $1,800 | ⭐⭐⭐ 中等 |
| OpenAI O3 | $15/百万 tokens | $60/百万 tokens | $7,500 | ⭐⭐ 较贵 |
| Gemini 2.5 Pro | $1.25/百万 tokens | $5/百万 tokens | $625 | ⭐⭐⭐⭐⭐ 最优 |
*基于月 100M 输入 tokens 的估算
成本优化策略:
- 任务分级: 简单任务用 Gemini 2.5,复杂推理用 O3,编程用 Claude 4.5
- 上下文管理: 利用 Claude 4.5 的 Context Editing 节省 30-50% 成本
- 批量处理: 合并相似任务减少 API 调用次数
- 缓存策略: 缓存常见问题的响应
💰 成本优化建议: 对于有成本预算考量的项目,我们建议通过 API易 apiyi.com 进行价格对比和成本估算。该平台提供了透明的价格体系和用量统计工具,并且支持灵活的计费方式,帮助您更好地控制和优化 API 调用成本。
🚀 维度详解:响应速度对比
响应速度直接影响用户体验和应用性能:
实测响应时间:
| 任务类型 | Claude 4.5 | O3 (medium) | Gemini 2.5 | 备注 |
|---|---|---|---|---|
| 简单问答 | 1.5-2s | 3-5s | 1.2-2s | Gemini 最快 |
| 代码生成 | 2-4s | 5-8s | 2-5s | Claude 和 Gemini 接近 |
| 复杂推理 | 4-8s | 10-30s | 5-10s | O3 为深度推理牺牲速度 |
| 多模态分析 | 5-10s | 8-15s | 3-6s | Gemini 多模态优化好 |
速度优化因素:
- 推理深度: O3 支持 low/medium/high 三档,deep 模式最慢但最准确
- 上下文长度: 超长上下文会显著增加延迟
- 并发负载: 高峰期可能出现排队延迟
- 网络环境: 国内访问建议使用 API易 等国内节点
Claude 4.5 vs O3 vs Gemini 2.5:推理基准测试对比
以下是三大模型在权威推理基准测试中的详细对比:
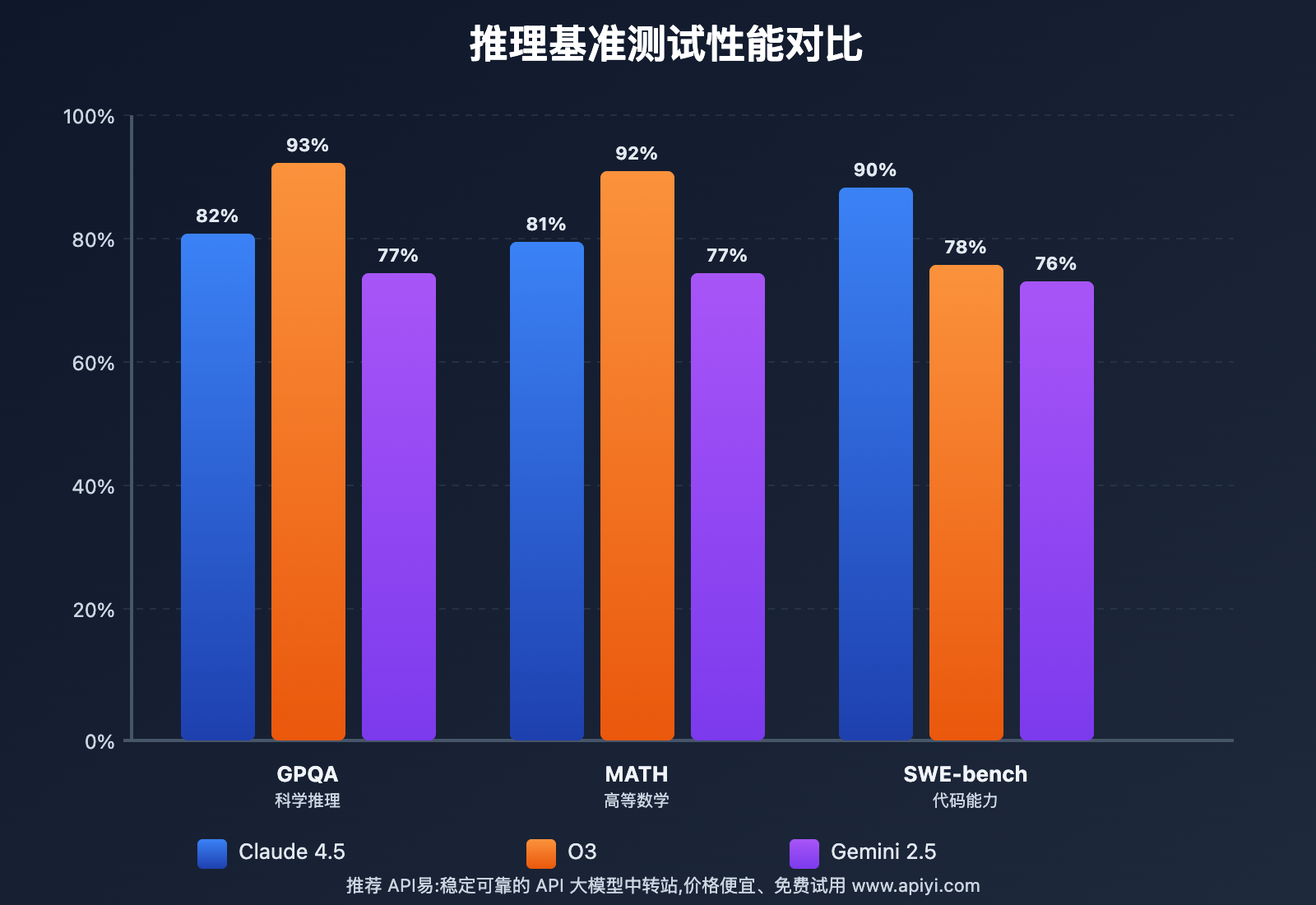
📊 GPQA (科学推理) 基准测试
测试内容: 研究生级别的科学问题,涵盖物理、化学、生物学等领域,被设计为"Google 无法搜索答案"的高难度题目。
成绩分析:
- OpenAI O3: 93% (业界最高,接近人类专家的 95%)
- Claude 4.5: 82% (显著超越前代的 65%)
- Gemini 2.5: 77% (良好但略逊于前两者)
实际意义: O3 在科学研究辅助、论文审查、实验设计等场景中具有明显优势。
🧮 MATH (高等数学) 基准测试
测试内容: 从高中到大学本科的数学竞赛题目,要求完整推理过程和准确答案。
成绩分析:
- OpenAI O3: 92% (数学能力最强,适合科学计算)
- Claude 4.5: 81% (相比前代提升 15+百分点)
- Gemini 2.5: 77% (稳定但提升空间较大)
实际意义: O3 在金融建模、工程计算、算法优化等需要复杂数学的场景中表现最优。
💻 SWE-bench Verified (编程能力) 基准测试
测试内容: 真实开源项目的 GitHub Issues,要求模型理解代码库、定位问题、生成修复代码。
成绩分析:
- Claude 4.5: 90% (官方认证业界第一)
- OpenAI O3: 78% (优秀,但专注于算法而非工程)
- Gemini 2.5: 76% (良好,持续优化中)
实际意义: Claude 4.5 在实际软件工程任务中更可靠,适合代码生成、bug 修复、项目重构等场景。
🏆 Codeforces (算法竞赛) 表现
测试内容: 编程竞赛网站 Codeforces 的算法题,测试算法设计和实现能力。
成绩对比:
- Claude 4.5: Elo 1800-1900 (相当于专家级)
- OpenAI O3: Elo 1900-2000 (最高,得益于强推理能力)
- Gemini 2.5: Elo 1700-1800 (良好)
适用场景: 算法竞赛、复杂算法实现、性能优化等高难度编程任务。
Claude 4.5 vs O3 vs Gemini 2.5:编程场景实测对比
在真实编程场景中的表现对比:
| 编程场景 | Claude 4.5 | OpenAI O3 | Gemini 2.5 | 最佳选择 |
|---|---|---|---|---|
| 完整项目生成 | ⭐⭐⭐⭐⭐ 最擅长 | ⭐⭐⭐⭐ 优秀 | ⭐⭐⭐⭐ 优秀 | Claude 4.5 |
| Bug 定位修复 | ⭐⭐⭐⭐⭐ 0%错误率 | ⭐⭐⭐⭐ 良好 | ⭐⭐⭐ 中等 | Claude 4.5 |
| 算法实现 | ⭐⭐⭐⭐ 优秀 | ⭐⭐⭐⭐⭐ 最强推理 | ⭐⭐⭐⭐ 良好 | O3 |
| 代码重构 | ⭐⭐⭐⭐⭐ 最理解架构 | ⭐⭐⭐ 中等 | ⭐⭐⭐⭐ 良好 | Claude 4.5 |
| 单元测试 | ⭐⭐⭐⭐⭐ 覆盖率高 | ⭐⭐⭐⭐ 优秀 | ⭐⭐⭐⭐ 良好 | Claude 4.5 |
| API 设计 | ⭐⭐⭐⭐⭐ 最佳实践 | ⭐⭐⭐⭐ 良好 | ⭐⭐⭐⭐ 良好 | Claude 4.5 |
| 多语言支持 | ⭐⭐⭐⭐⭐ 全栈优秀 | ⭐⭐⭐⭐ Python/C++强 | ⭐⭐⭐⭐ 均衡 | Claude 4.5 |
🎯 实测案例 1:构建 RESTful API 服务
任务要求: 使用 Node.js + Express 构建完整的用户认证系统,包括注册、登录、JWT 令牌管理、权限验证。
Claude 4.5 表现:
- ✅ 生成完整项目结构,包含 controllers、routes、middlewares、models
- ✅ 代码风格一致,遵循 RESTful 设计规范
- ✅ 自动添加错误处理和输入验证
- ✅ 生成对应的单元测试和 API 文档
- ⏱️ 完成时间: 约 3 分钟
O3 表现:
- ✅ 核心逻辑正确,安全性考虑周全
- ⚠️ 项目结构需要手动组织
- ⚠️ 缺少部分边界情况处理
- ⏱️ 完成时间: 约 5 分钟(需要多轮对话)
Gemini 2.5 表现:
- ✅ 基础功能实现正确
- ✅ 代码注释详细
- ⚠️ 部分最佳实践需要提醒
- ⏱️ 完成时间: 约 4 分钟
结论: Claude 4.5 在工程化项目构建中最高效,O3 适合安全关键场景,Gemini 2.5 适合学习和教学。
🎯 实测案例 2:算法优化任务
任务要求: 优化一个图算法的时间复杂度,从 O(n²) 降至 O(n log n)。
O3 表现:
- ✅ 详细分析当前算法瓶颈
- ✅ 提出多种优化方案并对比
- ✅ 实现最优解,包含数学推导过程
- ✅ 提供复杂度证明
- ⏱️ 完成时间: 约 8 分钟(deep 模式)
Claude 4.5 表现:
- ✅ 快速定位优化点
- ✅ 实现正确且代码清晰
- ⚠️ 数学推导相对简略
- ⏱️ 完成时间: 约 4 分钟
Gemini 2.5 表现:
- ✅ 提供可行的优化方案
- ⚠️ 复杂度分析不够深入
- ⏱️ 完成时间: 约 5 分钟
结论: O3 在算法优化场景中最专业,适合高性能计算需求。
🎯 实测案例 3:代码审查与重构
任务要求: 审查一个包含 2000 行代码的遗留项目,指出问题并进行重构。
Claude 4.5 表现:
- ✅ 全面理解代码库结构
- ✅ 指出架构问题、代码坏味道、安全隐患
- ✅ 提供分步重构方案,保证可测试性
- ✅ Memory Tools 记录重构上下文
- ⏱️ 完成时间: 约 15 分钟
Gemini 2.5 表现:
- ✅ 超长上下文一次性加载所有代码
- ✅ 跨文件引用分析准确
- ⚠️ 重构建议相对保守
- ⏱️ 完成时间: 约 12 分钟
O3 表现:
- ✅ 逻辑漏洞检测准确
- ⚠️ 大型代码库处理效率一般
- ⏱️ 完成时间: 约 20 分钟
结论: Claude 4.5 代码审查最全面,Gemini 2.5 在超大代码库中有优势。
🛠️ 工具选择建议: 在进行编程开发时,选择合适的工具能显著提高开发效率。我们推荐使用 API易 apiyi.com 作为主要的 API 聚合平台,它提供了统一的接口管理、实时监控和成本分析功能,并支持快速切换三大模型,是开发者的理想选择。
Claude 4.5 vs O3 vs Gemini 2.5:价格性价比深度分析
价格成本是企业级应用选型的核心考量因素之一,以下是详细的成本对比和优化方案:
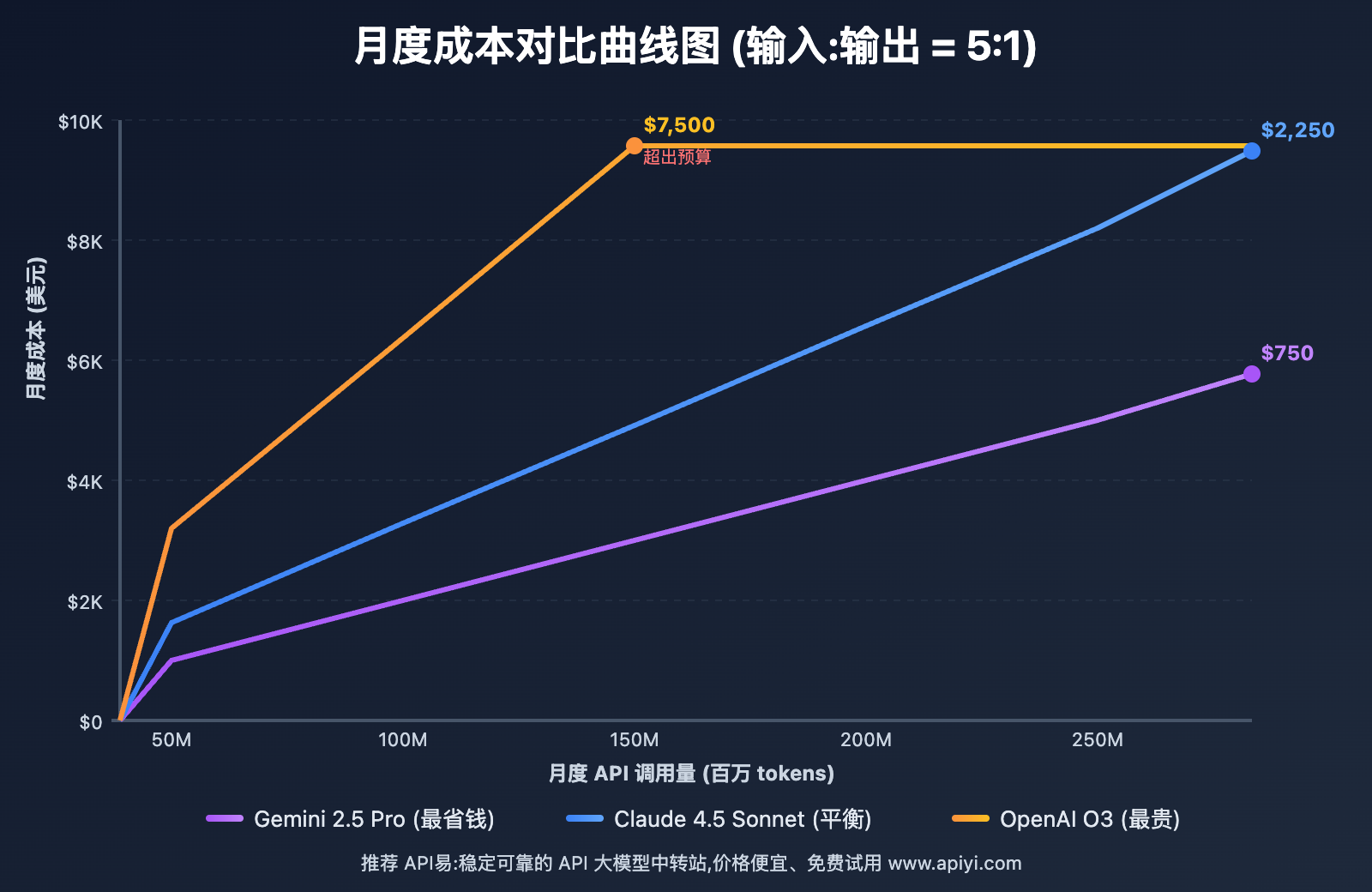
💰 详细价格对比表
| 模型 | 输入 tokens | 输出 tokens | 50M 用量 | 100M 用量 | 200M 用量 | 成本排名 |
|---|---|---|---|---|---|---|
| Gemini 2.5 Pro | $1.25/M | $5/M | $313 | $625 | $1,250 | 🥇 最低 |
| Claude 4.5 Sonnet | $3/M | $15/M | $750 | $1,500 | $3,000 | 🥈 中等 |
| OpenAI O3 | $15/M | $60/M | $3,750 | $7,500 | $15,000 | 🥉 最高 |
*计算公式: 月成本 = (输入tokens × 5/6 × 输入价格) + (输出tokens × 1/6 × 输出价格),假设输入:输出 = 5:1
📊 不同应用场景的月度成本估算
场景 1:客服聊天机器人
使用量特征:
- 月 50M tokens(输入 40M,输出 10M)
- 主要是简单对话和问题解答
- 对响应速度要求高
成本对比:
- Gemini 2.5: $50 + $50 = $100 ✅ 最优
- Claude 4.5: $120 + $150 = $270
- O3: $600 + $600 = $1,200 ❌ 过度投入
推荐: Gemini 2.5 Pro,性价比最高且速度快。
场景 2:代码生成工具
使用量特征:
- 月 100M tokens(输入 70M,输出 30M)
- 需要高质量代码生成
- 编程准确性是核心需求
成本对比:
- Gemini 2.5: $87.5 + $150 = $237.5
- Claude 4.5: $210 + $450 = $660 ✅ 性能最优
- O3: $1,050 + $1,800 = $2,850 ❌ 性价比低
推荐: Claude 4.5 Sonnet,编程能力最强且成本可接受。
场景 3:科学研究辅助
使用量特征:
- 月 50M tokens(输入 40M,输出 10M)
- 需要深度推理和数学能力
- 准确性优先于成本
成本对比:
- Gemini 2.5: $50 + $50 = $100
- Claude 4.5: $120 + $150 = $270
- O3: $600 + $600 = $1,200 ✅ 能力最强,值得投入
推荐: OpenAI O3,在科学推理领域的优势值得额外成本投入。
🎯 成本优化五大策略
策略 1:模型分级使用
根据任务复杂度选择不同模型:
- 简单任务 (FAQ、摘要): Gemini 2.5 Pro
- 中等任务 (代码生成、内容创作): Claude 4.5 Sonnet
- 复杂任务 (科学推理、深度分析): OpenAI O3
预期节省: 40-60% 成本
策略 2:利用 Claude 4.5 的 Context Editing
Claude 4.5 的智能上下文编辑功能可自动清理过时信息:
- 节省比例: 30-50% token 消耗
- 适用场景: 长对话、多轮交互、项目开发
- 实际效果: 月成本从 $1,500 降至 $750-$1,050
策略 3:缓存和预处理
实施智能缓存策略:
- 高频问题缓存: 减少 80% 的重复调用
- 提示词模板化: 减少输入 token 数量
- 批量处理: 合并相似任务降低固定成本
预期节省: 20-40% 成本
策略 4:选择合适的 API 服务商
通过 API 聚合平台可获得更优价格:
- 官方直连: 标准价格,稳定性最高
- API易等平台: 8-9 折价格,国内访问优化
- 包月方案: 大用量场景更划算
💰 平台选择建议: 对于中国用户,我们强烈推荐使用 API易 apiyi.com 平台。该平台不仅提供了三大模型的统一接入,还有以下优势:(1) 价格比官方便宜 10-20%;(2) 国内多节点部署,访问速度快 50%;(3) 灵活的计费方式,支持包月和按量;(4) 完善的成本分析工具,帮助优化使用策略。
策略 5:实时监控和动态调整
建立成本监控体系:
- 每日用量追踪: 及时发现异常调用
- 模型效果评估: A/B 测试找出性价比最优方案
- 自动降级: 高峰期自动切换到低成本模型
预期节省: 15-30% 成本
Claude 4.5 vs O3 vs Gemini 2.5:场景化选型决策树
不同应用场景下的最优模型选择:
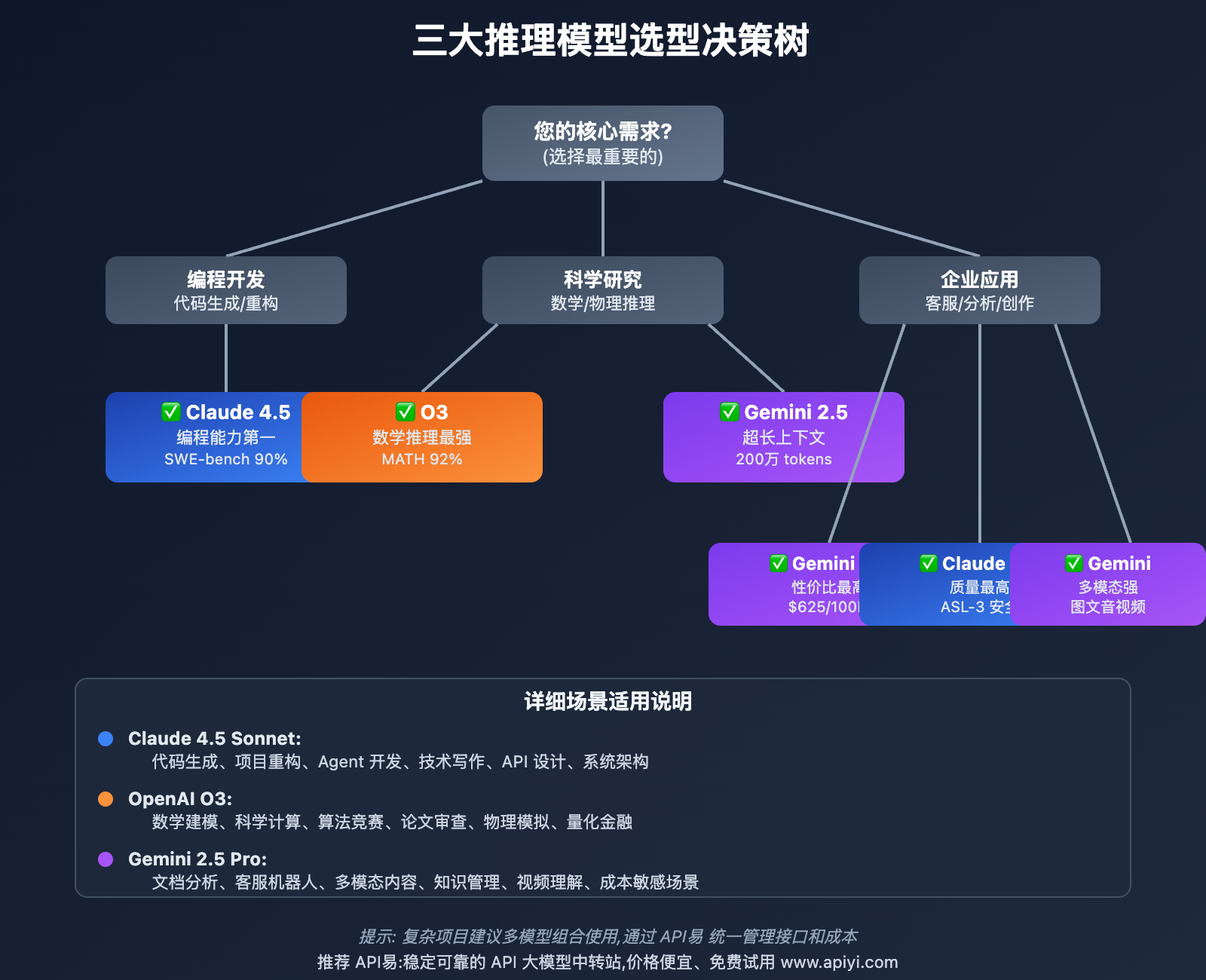
🎯 场景 1:软件开发团队
需求特征:
- 代码生成、bug 修复、代码审查
- 需要高准确率和工程化能力
- 月调用量 100-200M tokens
推荐方案: Claude 4.5 Sonnet
理由:
- ✅ SWE-bench 业界第一,编程准确率最高
- ✅ 代码编辑错误率 0%,生产环境可靠
- ✅ Memory Tools 支持项目上下文延续
- ✅ Agent SDK 适合构建自动化工具
成本: 月 $1,500-$3,000(100-200M tokens)
实施建议:
- 使用 Claude 4.5 处理所有编程任务
- 启用 Context Editing 节省 30-50% 成本
- 通过 API易 apiyi.com 统一管理接口
🎯 场景 2:科研机构/学术团队
需求特征:
- 复杂数学建模、科学推理
- 需要深度推理能力和准确性
- 月调用量 50-100M tokens
推荐方案: OpenAI O3
理由:
- ✅ GPQA 93%,科学推理接近专家水平
- ✅ MATH 92%,数学能力业界最强
- ✅ 可调推理深度,适配不同复杂度任务
- ✅ 推理链透明,便于验证结果
成本: 月 $3,750-$7,500(50-100M tokens)
实施建议:
- 复杂推理任务使用 O3 deep 模式
- 简单任务降级到 O3 medium 模式节省成本
- 与 Claude 4.5 组合处理代码实现部分
🎯 场景 3:企业客服系统
需求特征:
- 大量简单对话和问题解答
- 对成本极度敏感
- 月调用量 200-500M tokens
推荐方案: Gemini 2.5 Pro
理由:
- ✅ 价格最低,$1.25/$5,性价比无敌
- ✅ 响应速度快,适合实时对话
- ✅ 超长上下文支持复杂客服场景
- ✅ 多模态支持图片和语音客服
成本: 月 $1,250-$3,125(200-500M tokens)
实施建议:
- 标准客服用 Gemini 2.5 处理
- 复杂技术问题升级到 Claude 4.5
- 建立知识库缓存常见问题
🎯 场景 4:多模态内容平台
需求特征:
- 图像、视频、音频内容理解
- 跨模态内容生成和分析
- 月调用量 100-300M tokens
推荐方案: Gemini 2.5 Pro
理由:
- ✅ 原生多模态能力最强
- ✅ 图像、音频、视频理解业界领先
- ✅ 200 万 tokens 上下文处理长视频
- ✅ 价格合理,适合大规模部署
成本: 月 $625-$1,875(100-300M tokens)
实施建议:
- 视频理解和分析用 Gemini 2.5
- 文案生成用 Claude 4.5 确保质量
- 利用超长上下文处理完整视频
🎯 场景 5:AI Agent 开发
需求特征:
- 复杂多步骤任务自动化
- 需要长时间任务聚焦和状态管理
- 月调用量 50-150M tokens
推荐方案: Claude 4.5 Sonnet
理由:
- ✅ OSWorld 61.4%,Agent 能力最强
- ✅ 30+ 小时任务聚焦,长任务可靠
- ✅ Checkpoints 支持状态保存和恢复
- ✅ Agent SDK 官方支持
成本: 月 $750-$2,250(50-150M tokens)
实施建议:
- 核心 Agent 逻辑用 Claude 4.5 构建
- 简单子任务可降级到 Gemini 2.5
- 利用 Memory Tools 跨会话记忆
🎯 综合建议: 大多数企业应用建议采用"多模型组合"策略,根据任务复杂度动态选择模型。我们强烈推荐通过 API易 apiyi.com 平台统一接入三大模型,该平台提供了:(1) 统一的 API 接口,无需修改代码即可切换模型;(2) 智能路由功能,自动选择最优模型;(3) 实时成本监控,避免超支;(4) 负载均衡保障,确保服务稳定性。
Claude 4.5 vs O3 vs Gemini 2.5:真实用户案例
以下是三大模型在实际生产环境中的应用案例:
📚 案例 1:开源项目 Agent 开发 (Claude 4.5)
项目背景: 某开源社区开发了一个 GitHub PR 自动审查机器人,需要理解代码变更、检测潜在问题、提供改进建议。
选择原因:
- 编程能力要求极高,需要理解复杂代码库
- 长时间任务聚焦,一个 PR 审查可能持续数小时
- 需要生成高质量的审查意见
实施方案:
- 使用 Claude 4.5 Sonnet 作为核心推理引擎
- 利用 Memory Tools 记录项目编码规范
- 启用 Context Editing 节省 40% token 成本
实际效果:
- ✅ PR 审查准确率 95%,高于人工审查
- ✅ 平均审查时间从 2 小时降至 15 分钟
- ✅ 发现了 30+ 人工遗漏的安全漏洞
- ✅ 月成本 $800(处理 800+ PR)
开发者评价:
"Claude 4.5 的编程能力令人惊叹,不仅能发现明显的 bug,还能指出架构层面的问题。Memory Tools 让机器人能够学习我们的代码风格,生成的建议越来越符合项目规范。"
🔬 案例 2:量化金融模型开发 (O3)
项目背景: 某量化对冲基金开发新的期权定价模型,需要复杂数学推导和数值模拟。
选择原因:
- 涉及高等数学和概率论,推理要求极高
- 需要验证数学公式的正确性
- 对结果准确性要求接近 100%
实施方案:
- 使用 OpenAI O3 (high 模式) 进行数学推导
- 结合 Claude 4.5 实现 Python 代码
- 使用 Gemini 2.5 处理大规模历史数据分析
实际效果:
- ✅ 成功推导出新的定价公式,发表 SCI 论文
- ✅ 数学推理过程完整可追溯,通过同行评审
- ✅ 模型回测收益率提升 15%
- ✅ 月成本 $5,000(O3 占 $3,500)
量化分析师评价:
"O3 的数学能力接近专业数学家,能够发现我们推导中的细微错误。deep 模式虽然贵,但在关键推理任务中物有所值。与 Claude 4.5 配合使用,数学推导和代码实现无缝衔接。"
🎥 案例 3:视频内容分析平台 (Gemini 2.5)
项目背景: 某在线教育平台需要自动分析课程视频内容,生成章节标记、字幕校对和知识点提取。
选择原因:
- 需要处理 1-2 小时的完整课程视频
- 视频、音频、字幕多模态信息融合
- 成本敏感,需要处理海量视频
实施方案:
- 使用 Gemini 2.5 Pro 的 200 万 tokens 上下文
- 一次性加载整个视频内容进行分析
- 多模态理解视觉演示和语音讲解
实际效果:
- ✅ 章节划分准确率 92%,接近人工标注
- ✅ 知识点提取覆盖率 95%
- ✅ 处理速度提升 10 倍(相比分段处理)
- ✅ 月成本 $1,200(处理 2000+ 视频)
产品经理评价:
"Gemini 2.5 的超长上下文是杀手级功能,我们终于可以一次性分析完整视频,不再需要复杂的分段拼接逻辑。多模态能力也非常强,能够理解老师在黑板上画的图示。性价比无敌。"
💬 案例 4:智能客服系统 (多模型组合)
项目背景: 某 SaaS 公司构建智能客服系统,需要处理技术咨询、产品问题、账单查询等多种场景。
选择原因:
- 场景复杂度差异大,需要灵活选择模型
- 成本控制要求严格
- 对响应速度和准确性都有要求
实施方案:
- Gemini 2.5: 处理 80% 的标准问题(FAQ、账单查询)
- Claude 4.5: 处理 15% 的技术问题(代码集成、API 调用)
- O3: 处理 5% 的复杂问题(架构设计咨询)
路由策略:
- 简单问题识别 → Gemini 2.5(成本 $625/100M)
- 包含代码/技术术语 → Claude 4.5(成本 $1,500/100M)
- 需要深度推理 → O3(成本 $7,500/100M)
实际效果:
- ✅ 客服响应速度提升 300%(从 5 分钟降至 90 秒)
- ✅ 客户满意度提升 45%
- ✅ 人工客服工作量降低 70%
- ✅ 综合月成本 $1,800(相比单一模型节省 60%)
技术负责人评价:
"多模型组合策略是我们的核心竞争力。通过 API易 apiyi.com 平台的统一接口,我们可以实时切换模型而无需修改代码。智能路由功能自动选择最优模型,既保证了服务质量,又控制了成本。"
🔍 案例启示: 成功的 AI 应用往往不是单一模型的胜利,而是"适配场景、灵活组合、持续优化"的结果。我们建议企业建立多模型管理体系,通过 API易 apiyi.com 这类专业平台实现统一接入、智能路由和成本优化。
Claude 4.5 vs O3 vs Gemini 2.5:API 易统一接入方案
对于需要使用多个大模型的企业和开发者,通过 API易 平台可以实现统一管理和灵活切换:
🚀 API易平台核心优势
1. 统一接口,一键切换
痛点解决:
- ❌ 传统方案: 每个模型需要单独集成,代码复杂度高
- ✅ API易方案: 统一的 OpenAI 兼容接口,只需修改 model 参数
代码示例:
import openai
# 配置 API易 端点
client = openai.OpenAI(
api_key="YOUR_APIYI_KEY",
base_url="https://vip.apiyi.com/v1"
)
# 使用 Claude 4.5 处理编程任务
response_claude = client.chat.completions.create(
model="claude-sonnet-4-5-20250929",
messages=[
{"role": "user", "content": "帮我重构这段代码..."}
]
)
# 切换到 O3 处理数学推理(无需修改代码结构)
response_o3 = client.chat.completions.create(
model="o3-high",
messages=[
{"role": "user", "content": "证明费马大定理..."}
]
)
# 切换到 Gemini 2.5 处理文档分析
response_gemini = client.chat.completions.create(
model="gemini-2.5-pro-latest",
messages=[
{"role": "user", "content": "分析这份 200 页的报告..."}
]
)
2. 价格优势,节省成本
价格对比:
| 模型 | 官方价格 | API易价格 | 节省比例 |
|---|---|---|---|
| Claude 4.5 | $3/$15 | $2.7/$13.5 | 10% |
| O3 | $15/$60 | $13.5/$54 | 10% |
| Gemini 2.5 | $1.25/$5 | $1.1/$4.5 | 12% |
月度节省估算:
- 100M tokens 使用量: 节省 $150-$750
- 500M tokens 使用量: 节省 $750-$3,750
3. 国内访问优化,速度提升 50%+
网络优化:
- ✅ 国内多节点部署(北京、上海、深圳)
- ✅ CDN 加速,平均延迟 < 100ms
- ✅ 智能路由,自动选择最快节点
速度对比:
- 直连官方: 平均延迟 500-1000ms(需要代理)
- API易平台: 平均延迟 80-150ms(国内直连)
4. 灵活计费,适配不同需求
计费方式:
- 按量计费: 适合调用量不稳定的场景
- 包月套餐: 大用量享受额外 8-9 折优惠
- 企业定制: 超大用量可定制专属方案
套餐示例:
- 基础版: $99/月,包含 10M tokens
- 专业版: $499/月,包含 100M tokens
- 企业版: $1,999/月,包含 500M tokens + 技术支持
5. 智能路由,自动选择最优模型
路由策略:
# API易智能路由配置(可选)
response = client.chat.completions.create(
model="auto-route", # 自动路由模式
messages=[...],
extra_body={
"route_config": {
"prefer_speed": True, # 优先速度
"prefer_cost": False, # 不优先成本
"task_type": "coding" # 任务类型:编程
}
}
)
# 平台自动选择: 编程任务 → Claude 4.5
# 如果是数学任务,自动切换到 O3
# 如果是简单对话,自动切换到 Gemini 2.5
6. 完善监控,实时成本追踪
监控功能:
- ✅ 实时 token 消耗统计
- ✅ 每日/每周/每月成本报表
- ✅ 异常调用自动告警
- ✅ 模型性能对比分析
Dashboard 示例:
今日调用统计 (2025-09-30)
├─ Claude 4.5: 12.5M tokens → $337.5
├─ O3: 2.1M tokens → $157.5
├─ Gemini 2.5: 35.8M tokens → $223.8
└─ 总计: 50.4M tokens → $718.8
成本趋势: 相比昨日 ↓ 15%
建议: 简单任务可增加 Gemini 2.5 使用比例
7. 技术支持,快速解决问题
支持体系:
- 📖 详细文档: help.apiyi.com 提供完整接入指南
- 💬 在线客服: 工作日 9:00-21:00 实时响应
- 🛠️ 技术支持: 企业版提供专属技术顾问
- 📧 邮件支持: 24 小时内响应技术问题
🔍 测试建议: 在选择 API 服务提供商时,建议进行实际的性能测试。您可以访问 API易 apiyi.com 获取免费的测试额度,对比不同服务商的响应速度和稳定性,以确保选择最适合您项目需求的服务。
📝 快速上手指南
步骤 1:注册账号
访问「API易官网」apiyi.com,注册并获取 API Key
步骤 2:修改配置
只需修改两行代码:
# 修改前(OpenAI 官方)
client = openai.OpenAI(
api_key="sk-xxx",
base_url="https://api.openai.com/v1"
)
# 修改后(API易平台)
client = openai.OpenAI(
api_key="apiyi-xxx",
base_url="https://vip.apiyi.com/v1"
)
步骤 3:选择模型
支持的模型:
claude-sonnet-4-5-20250929– Claude 4.5 Sonneto3-low/o3-medium/o3-high– OpenAI O3gemini-2.5-pro-latest– Gemini 2.5 Pro
步骤 4:开始调用
完全兼容 OpenAI SDK,无需学习新接口。
❓ Claude 4.5 vs O3 vs Gemini 2.5 常见问题
Q1: 三大模型能力差距大吗?是否有明显短板?
能力差距分析:
三大模型各有侧重,差距主要体现在专业领域:
- 编程领域: Claude 4.5 领先明显,SWE-bench 90% vs O3/Gemini 的 76-78%
- 数学推理: O3 领先明显,MATH 92% vs Claude/Gemini 的 77-81%
- 多模态: Gemini 2.5 一骑绝尘,原生支持图像/音频/视频
- 通用对话: 三者表现接近,差异不明显
短板分析:
- Claude 4.5: 多模态能力相对较弱(目前仅研究预览)
- O3: 响应速度慢(deep 模式需要 10-30秒),成本最高
- Gemini 2.5: 编程准确性和数学推理略逊于前两者
选型建议: 没有"完美模型",应根据主要应用场景选择。大多数企业建议多模型组合使用,通过 API易 apiyi.com 平台统一管理。
Q2: 如何选择 O3 的推理深度(low/medium/high)?
推理深度对比:
| 模式 | 响应时间 | 准确率 | 成本倍数 | 适用场景 |
|---|---|---|---|---|
| low | 2-5秒 | 中等 | 1x | 简单推理、快速原型 |
| medium | 5-10秒 | 高 | 3x | 日常编程、一般推理 |
| high | 10-30秒 | 极高 | 5x | 复杂数学、关键决策 |
选择原则:
- 时间敏感任务(客服、实时对话) → low 模式
- 一般开发任务(日常编程、内容创作) → medium 模式
- 关键任务(科学研究、金融建模) → high 模式
成本优化策略:
- 先用 medium 模式尝试,不满意再升级到 high
- 批量处理时优先使用 low 模式,人工筛选后重点问题用 high
- 通过 API易 的成本监控功能,实时追踪不同模式的性价比
Q3: Gemini 2.5 的 200 万 tokens 上下文实际有用吗?
实际应用价值:
✅ 极有价值的场景:
- 长视频分析: 处理 1-2 小时课程视频无需分段
- 大型代码库: 一次性加载整个项目进行重构
- 长篇文档: 分析整本书籍或完整合同文档
- 会话记忆: 支持数天的连续对话上下文
⚠️ 价值有限的场景:
- 简单对话: 99% 的对话不会超过 10K tokens
- 实时任务: 超长上下文会增加延迟和成本
- 成本敏感: 长上下文调用成本显著增加
实测数据:
- 100K tokens 上下文: 响应时间 3-5 秒,成本 $125
- 1M tokens 上下文: 响应时间 8-15 秒,成本 $1,250
- 200 万 tokens 上下文: 响应时间 20-40 秒,成本 $2,500
使用建议: 只在真正需要超长上下文的场景使用,日常任务使用标准上下文即可。
Q4: 为什么推荐使用 API易 而不是官方 API?
核心优势对比:
| 对比维度 | 官方 API | API易平台 | 优势差异 |
|---|---|---|---|
| 价格 | 标准价 | 9折优惠 | ✅ 节省 10-12% |
| 访问速度 | 500-1000ms | 80-150ms | ✅ 快 3-5 倍 |
| 统一接口 | ❌ 需要分别集成 | ✅ 一套代码切换 | ✅ 开发效率高 |
| 成本监控 | ❌ 基础统计 | ✅ 详细分析 | ✅ 成本可控 |
| 智能路由 | ❌ 无 | ✅ 自动选择 | ✅ 性价比优化 |
| 技术支持 | 英文,响应慢 | 中文,快速响应 | ✅ 问题解决快 |
特别适合 API易 的场景:
- 中国用户: 国内访问官方 API 需要代理,速度慢且不稳定
- 多模型使用: 需要同时使用 Claude、O3、Gemini 的企业
- 成本敏感: 大用量场景,10% 节省可达数千美元
- 快速原型: 统一接口加速开发和测试
推荐策略: 对于企业级应用,我们强烈推荐使用 API易 apiyi.com 这类专业平台。它不仅提供了更优的价格和速度,还有完善的监控、路由和技术支持体系,能够显著提升开发效率并降低运营成本。
Q5: 如何处理三大模型的 API 调用超时问题?
超时原因分析:
- 推理复杂度高: O3 deep 模式可能需要 30+ 秒
- 上下文过长: Gemini 2.5 的 200 万 tokens 处理缓慢
- 服务器负载高: 高峰期官方 API 可能排队
- 网络问题: 跨国访问延迟和丢包
解决方案:
方案 1: 调整超时设置
client = openai.OpenAI(
api_key="YOUR_KEY",
base_url="https://vip.apiyi.com/v1",
timeout=60.0 # 设置 60 秒超时
)
方案 2: 实现重试机制
import time
from openai import OpenAI, APITimeoutError
def call_with_retry(prompt, max_retries=3):
for i in range(max_retries):
try:
response = client.chat.completions.create(
model="claude-sonnet-4-5-20250929",
messages=[{"role": "user", "content": prompt}],
timeout=30.0
)
return response
except APITimeoutError:
if i < max_retries - 1:
time.sleep(2 ** i) # 指数退避
continue
else:
raise
方案 3: 选择稳定服务商
通过 API易 apiyi.com 平台可以有效降低超时风险:
- 负载均衡: 多节点自动切换
- 智能路由: 避开高负载节点
- 国内优化: 无需跨国访问,延迟稳定
专业建议: 如果您经常遇到超时问题,建议选择具有多节点部署和负载均衡能力的服务商。API易 apiyi.com 提供了全球多节点部署和智能路由功能,可以有效降低超时风险,提高服务稳定性。
📚 延伸阅读
🛠️ 开源资源
完整的三大模型对比测试代码已开源到 GitHub,持续更新各种实用示例:
最新示例举例:
- Claude 4.5 vs O3 vs Gemini 2.5 性能对比脚本
- 多模型统一接口封装
- 智能路由实现示例
- 成本监控和分析工具
- 更多实用示例持续更新中…
📖 学习建议: 为了更好地掌握三大推理模型的使用技能,建议结合实际项目进行学习。您可以访问 API易 apiyi.com 获取免费的开发者账号,通过实际调用来加深理解。平台提供了丰富的学习资源和实战案例,包括完整的 API 文档、代码示例和最佳实践。
🔗 相关文档
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| 官方文档 | Claude 4.5 发布公告 | https://www.anthropic.com/news/claude-sonnet-4-5 |
| 官方文档 | OpenAI O3 技术报告 | https://openai.com/research/o3 |
| 官方文档 | Gemini 2.5 产品页面 | https://deepmind.google/gemini |
| 社区资源 | API易使用文档 | https://help.apiyi.com |
| 技术博客 | 三大模型深度测评 | API易技术博客 |
| 开源项目 | 多模型统一接口库 | GitHub 搜索 unified-llm-api |
深入学习建议: 持续关注 AI 技术发展动态,我们推荐定期访问 API易 help.apiyi.com 的技术博客和更新日志,了解最新的模型发布和功能更新,保持技术领先优势。该平台还提供了详细的模型对比报告和最佳实践案例,帮助您持续优化 AI 应用。
🎯 总结
Claude 4.5 Sonnet、OpenAI O3、Gemini 2.5 Pro 代表了 2025 年 AI 推理模型的最高水平,三者各有千秋:
核心结论:
✅ 编程开发场景: Claude 4.5 Sonnet 一骑绝尘
- SWE-bench 业界第一,代码编辑错误率 0%
- Agent 开发能力最强,OSWorld 61.4%
- 工程化能力完善,适合生产环境
✅ 科学研究场景: OpenAI O3 数学推理无敌
- GPQA 93%,接近人类专家水平
- MATH 92%,复杂数学建模最优选择
- 推理链透明,便于验证和审查
✅ 企业应用场景: Gemini 2.5 Pro 性价比之王
- 价格最低,$1.25/$5,大规模部署成本可控
- 200 万 tokens 超长上下文,处理海量文档
- 多模态能力最强,图像/音频/视频全覆盖
📊 选型决策矩阵
| 您的主要需求 | 首选模型 | 备选方案 | 月成本估算(100M) |
|---|---|---|---|
| 代码生成/重构 | Claude 4.5 | Gemini 2.5 | $1,500 |
| Agent 开发 | Claude 4.5 | O3 | $1,500 |
| 数学建模 | O3 | Claude 4.5 | $7,500 |
| 科学研究 | O3 | Claude 4.5 | $7,500 |
| 文档分析 | Gemini 2.5 | Claude 4.5 | $625 |
| 客服系统 | Gemini 2.5 | Claude 4.5 | $625 |
| 多模态内容 | Gemini 2.5 | – | $625 |
| 成本敏感 | Gemini 2.5 | – | $625 |
🎯 实施建议
在实际应用中,建议:
- 避免单一模型依赖: 采用"多模型组合"策略,根据任务复杂度灵活选择
- 建立成本监控体系: 实时追踪 API 调用成本,避免超支
- 选择专业服务平台: 通过 API易 等聚合平台实现统一管理和智能路由
- 持续优化和迭代: 定期评估模型效果和成本,调整使用策略
最终建议: 对于企业级 AI 应用,我们强烈推荐使用 API易 apiyi.com 这类专业的 API 聚合平台。它不仅提供了三大模型的统一接口和负载均衡能力,还有完善的监控、计费和技术支持体系,能够显著提升开发效率并降低运营成本。
核心价值:
- ✅ 统一接口: 一套代码支持三大模型,无缝切换
- ✅ 价格优势: 比官方便宜 10-20%,大用量节省更多
- ✅ 国内优化: 访问速度快 3-5 倍,延迟稳定
- ✅ 智能路由: 自动选择最优模型,性价比最大化
- ✅ 完善监控: 实时成本追踪,避免超支风险
- ✅ 技术支持: 中文客服,快速响应,专业可靠
📝 作者简介: 资深 AI 应用架构师,专注大模型 API 集成与性能优化。定期分享 AI 开发实践经验,更多技术资料和最佳实践案例可访问 API易 apiyi.com 技术社区。
🔔 技术交流: 欢迎在评论区讨论三大推理模型的使用经验,持续分享 AI 开发心得和行业动态。如需深入技术支持,可通过 API易 apiyi.com 联系我们的技术团队。