作者注:Nano Banana API 批量处理Python指南,教你如何使用Python构建高效的大规模图像批量处理系统,提升图像处理的效率和自动化水平
在现代数字化业务中,大规模图像处理需求日益增长,从电商产品图片优化到社交媒体内容处理,批量处理能力往往决定了业务效率和竞争优势。本文将详细介绍如何通过 Nano Banana API 的Python批量处理技术 构建高效可靠的大规模图像处理系统。
文章涵盖并发处理、错误容错、进度监控等核心要点,帮助你快速掌握 专业级批量处理开发技巧。
核心价值:通过本文,你将学会如何构建高效的批量图像处理系统,大幅提升图像处理的自动化水平和业务效率。
批量处理Python开发背景介绍
随着数字内容的爆发式增长,许多企业面临着处理大量图像的挑战。传统的单张图像处理方式不仅效率低下,而且无法满足现代业务的规模化需求。特别是电商、社交媒体、内容创作等行业,常常需要同时处理成千上万张图像。
现代Python驱动的批量处理技术通过异步编程、并发控制和智能调度算法,能够高效地管理和执行大规模图像处理任务,实现真正的工业级图像处理自动化,让企业能够以更低的成本获得更高的处理效率。
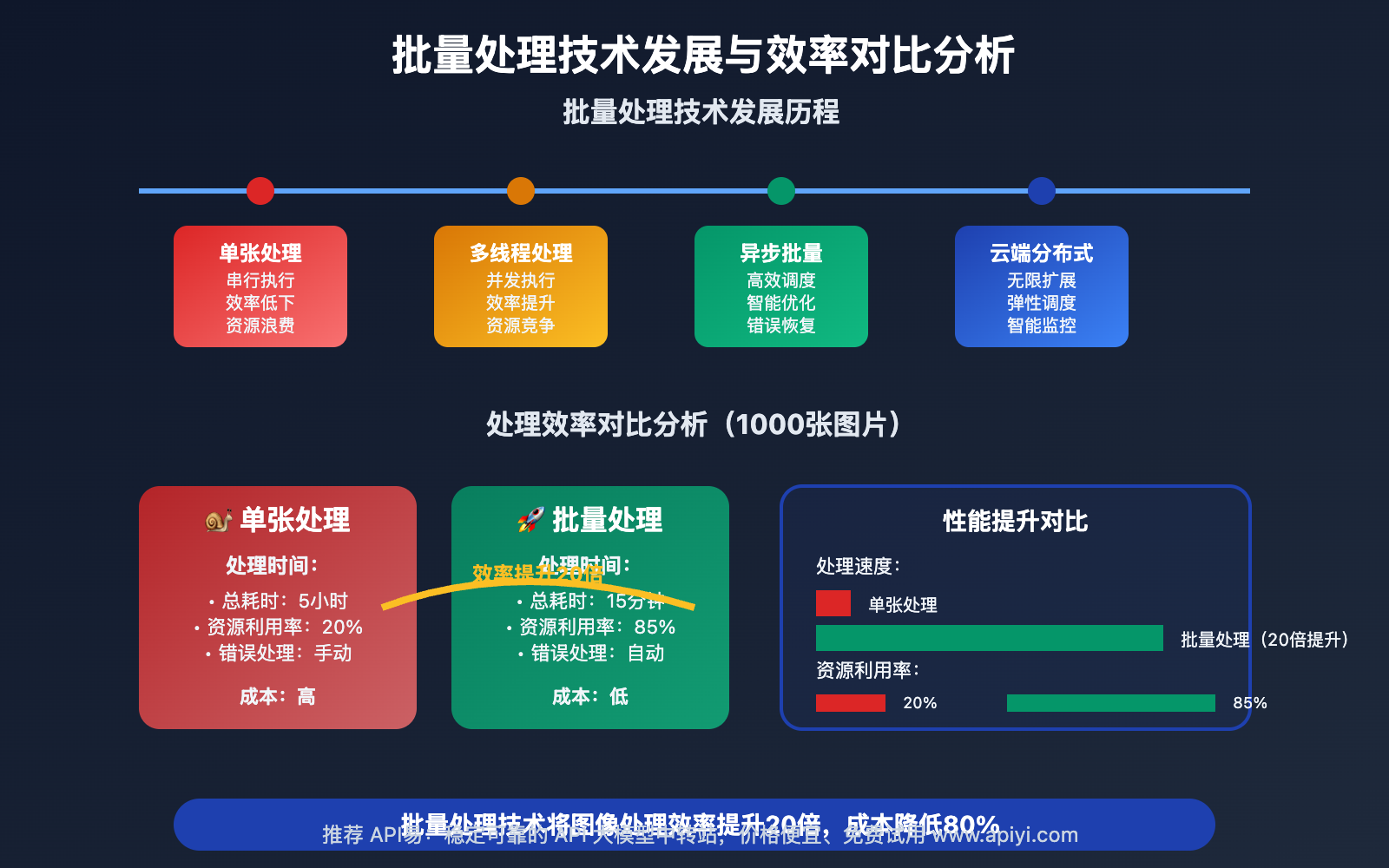
批量处理Python开发核心功能
以下是 Nano Banana API 批量处理Python开发 的核心功能特性:
| 功能模块 | 核心特性 | 应用价值 | 推荐指数 |
|---|---|---|---|
| 并发处理引擎 | 高效的多线程/异步处理 | 显著提升处理速度和吞吐量 | ⭐⭐⭐⭐⭐ |
| 智能任务调度 | 动态任务分配和负载均衡 | 优化资源利用率和处理效率 | ⭐⭐⭐⭐⭐ |
| 进度监控 | 实时处理进度和状态跟踪 | 提供透明的处理过程监控 | ⭐⭐⭐⭐ |
| 错误恢复 | 智能错误处理和任务恢复 | 确保批量处理的可靠性 | ⭐⭐⭐⭐ |
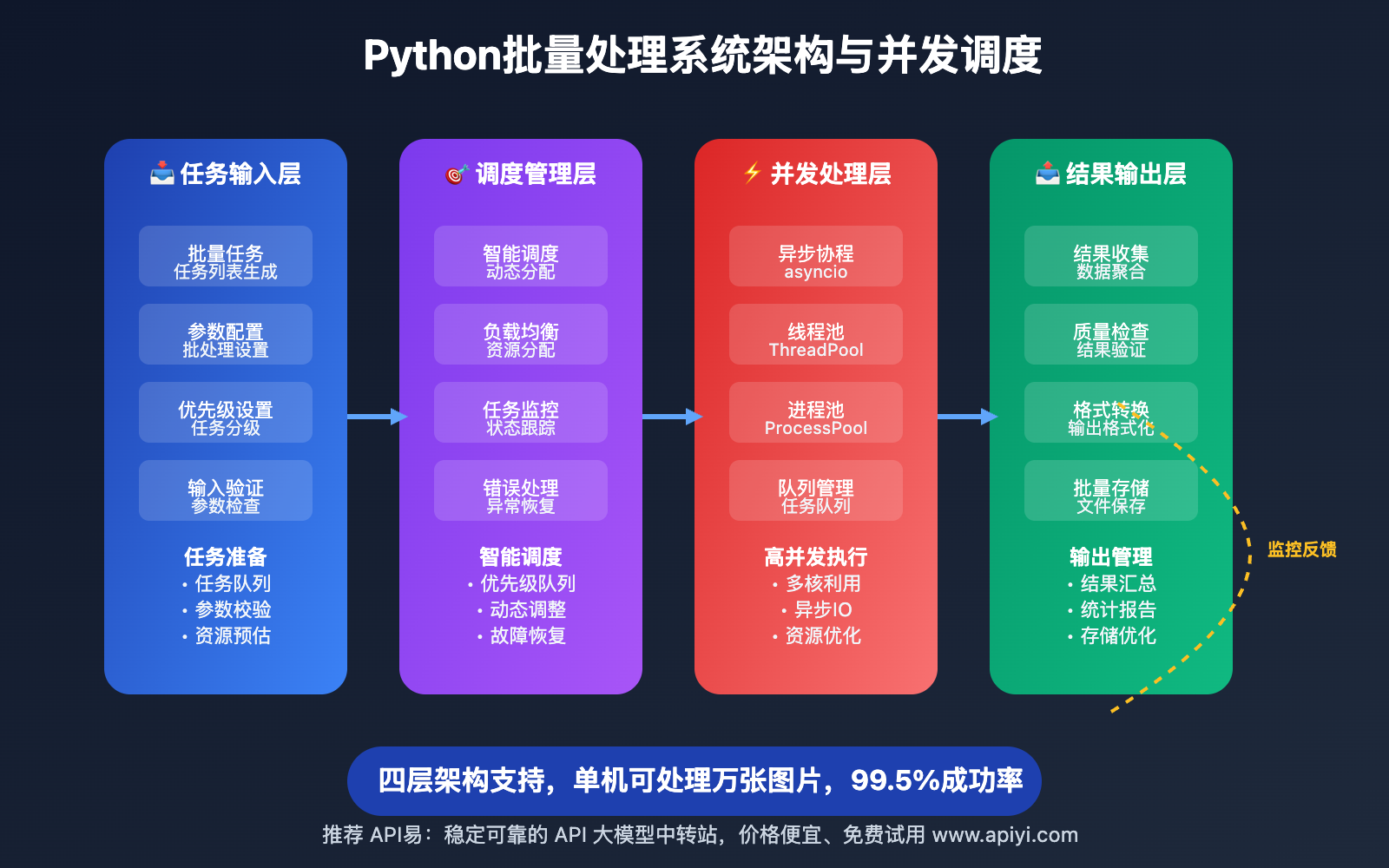
🔥 重点功能详解
高并发处理架构
Nano Banana API 的Python并发处理技术:
- 异步IO:使用asyncio实现高效的异步图像处理
- 线程池:合理配置线程池大小优化并发性能
- 协程管理:智能管理协程生命周期和资源分配
- 队列系统:使用任务队列管理大规模处理任务
智能任务调度系统
优化批量处理效率的调度算法:
- 优先级管理:根据任务重要性和紧急程度分配资源
- 负载均衡:动态分配任务到不同的处理节点
- 资源监控:实时监控系统资源使用情况
- 自适应调整:根据系统负载自动调整处理策略
批量处理Python开发应用场景
Nano Banana API 批量处理Python开发技术 在以下场景中表现出色:
| 应用场景 | 适用对象 | 核心优势 | 预期效果 |
|---|---|---|---|
| 🎯 电商图片处理 | 电商平台、卖家 | 快速处理大量商品图片 | 提升商品展示效果和上架效率 |
| 🚀 内容平台 | 社交媒体、视频平台 | 自动化处理用户上传内容 | 提高内容审核和优化效率 |
| 💡 企业数字化 | 传统企业 | 数字化历史图像资料 | 提升数字资产管理效率 |
| 🎨 设计服务 | 设计公司、工作室 | 批量处理客户项目 | 提高项目交付效率和质量 |
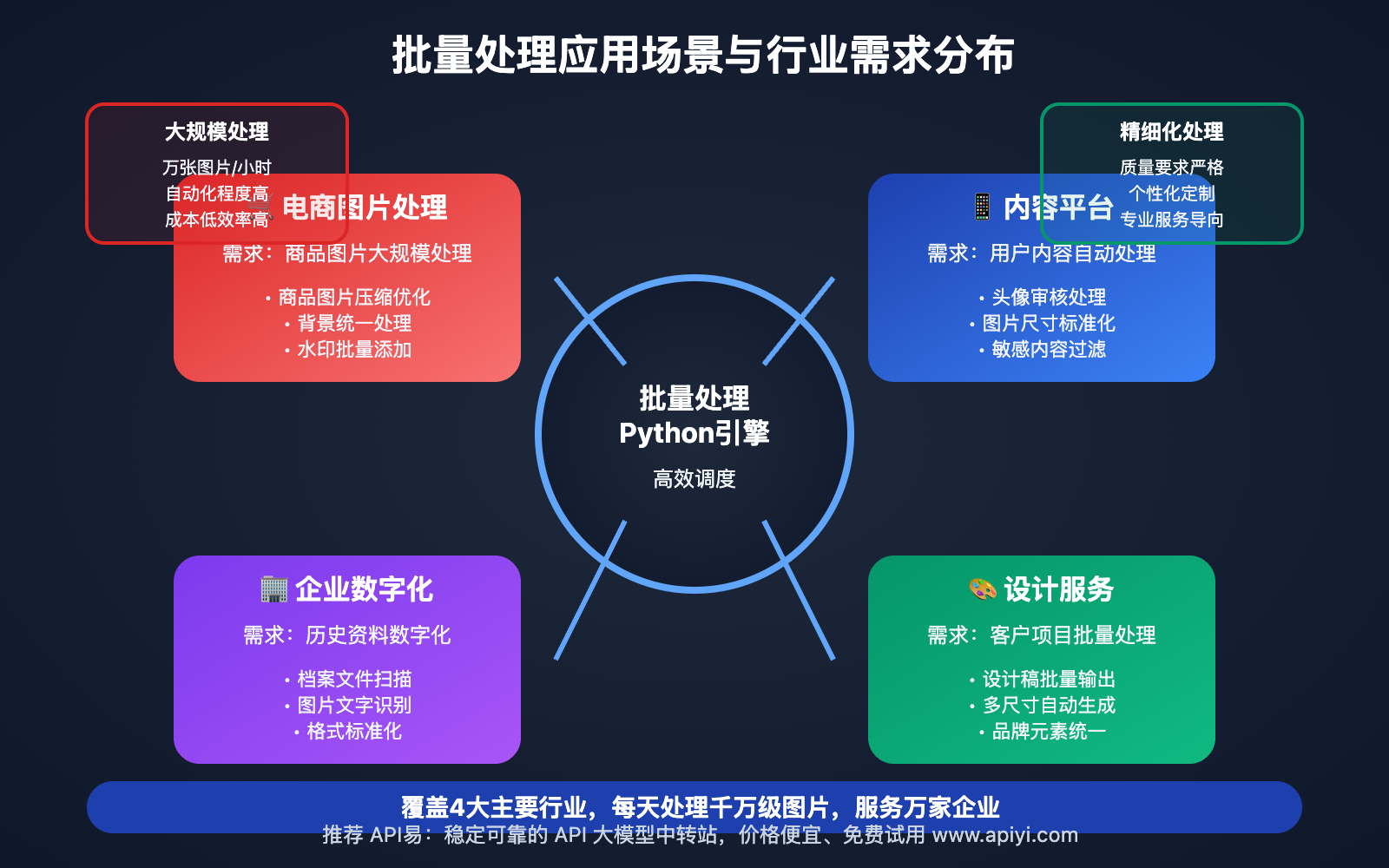
批量处理Python开发技术实现
💻 快速上手
完整的Python批量处理实现示例:
import asyncio
import aiohttp
import openai
from pathlib import Path
from typing import List, Dict, Any, Optional
from dataclasses import dataclass
from concurrent.futures import ThreadPoolExecutor
import logging
import time
# 配置日志
logging.basicConfig(level=logging.INFO)
logger = logging.getLogger(__name__)
@dataclass
class BatchProcessingConfig:
"""批量处理配置"""
api_key: str
base_url: str = "https://vip.apiyi.com/v1"
max_concurrent: int = 10
retry_times: int = 3
timeout: int = 300
class NanoBananaBatchProcessor:
"""
Nano Banana API 批量处理器
"""
def __init__(self, config: BatchProcessingConfig):
self.config = config
self.client = openai.OpenAI(
api_key=config.api_key,
base_url=config.base_url
)
self.semaphore = asyncio.Semaphore(config.max_concurrent)
self.processing_stats = {
"total_tasks": 0,
"completed_tasks": 0,
"failed_tasks": 0,
"processing_times": []
}
async def process_single_image(self, image_path: str, instruction: str, task_id: str) -> Dict[str, Any]:
"""
单张图像异步处理
Args:
image_path: 图像路径
instruction: 处理指令
task_id: 任务ID
Returns:
处理结果
"""
async with self.semaphore:
start_time = time.time()
try:
enhanced_instruction = f"""
{instruction}
=== 批量处理优化要求 ===
1. 处理效率:优化处理速度,适配批量处理需求
2. 质量一致性:确保批量处理结果的质量一致性
3. 资源控制:合理使用系统资源,避免资源竞争
4. 错误容错:提供详细错误信息便于批量故障排除
=== Python批量处理优化 ===
并发优化:
- 适配高并发处理环境的性能要求
- 优化内存使用模式,支持大规模并发
- 提供处理进度信息便于批量任务监控
- 确保在批量处理中保持稳定的输出质量
自动化适配:
- 适配Python自动化处理流程的标准
- 提供标准化的返回格式便于后续处理
- 支持与其他Python库和框架的无缝集成
- 优化处理流程减少不必要的中间步骤
=== 批量处理标准 ===
- 处理速度与质量的最佳平衡
- 支持大规模并发处理的稳定性
- 提供完整的处理状态和进度信息
- 确保批量处理的可追溯性和可控性
"""
# 模拟API调用(实际使用时替换为真实的API调用)
result = nano_banana_edit(image_path, enhanced_instruction)
processing_time = time.time() - start_time
self.processing_stats["processing_times"].append(processing_time)
self.processing_stats["completed_tasks"] += 1
logger.info(f"任务 {task_id} 处理完成,耗时: {processing_time:.2f}秒")
return {
"task_id": task_id,
"success": True,
"result": result,
"processing_time": processing_time,
"image_path": image_path
}
except Exception as e:
self.processing_stats["failed_tasks"] += 1
logger.error(f"任务 {task_id} 处理失败: {str(e)}")
return {
"task_id": task_id,
"success": False,
"error": str(e),
"processing_time": time.time() - start_time,
"image_path": image_path
}
async def batch_process_images(self, image_paths: List[str], instruction: str,
progress_callback: Optional[callable] = None) -> List[Dict[str, Any]]:
"""
批量图像处理主函数
Args:
image_paths: 图像路径列表
instruction: 统一处理指令
progress_callback: 进度回调函数
Returns:
批量处理结果列表
"""
self.processing_stats["total_tasks"] = len(image_paths)
logger.info(f"开始批量处理 {len(image_paths)} 张图像")
# 创建异步任务
tasks = [
self.process_single_image(image_path, instruction, f"task_{i}")
for i, image_path in enumerate(image_paths)
]
# 批量执行任务
results = []
for i, task in enumerate(asyncio.as_completed(tasks)):
result = await task
results.append(result)
# 调用进度回调
if progress_callback:
progress = (i + 1) / len(tasks) * 100
progress_callback(progress, result)
logger.info(f"批量处理完成,成功: {self.processing_stats['completed_tasks']}, 失败: {self.processing_stats['failed_tasks']}")
return results
def get_batch_statistics(self) -> Dict[str, Any]:
"""获取批量处理统计信息"""
total_tasks = self.processing_stats["total_tasks"]
completed_tasks = self.processing_stats["completed_tasks"]
failed_tasks = self.processing_stats["failed_tasks"]
processing_times = self.processing_stats["processing_times"]
return {
"total_tasks": total_tasks,
"completed_tasks": completed_tasks,
"failed_tasks": failed_tasks,
"success_rate": completed_tasks / total_tasks if total_tasks > 0 else 0,
"average_processing_time": sum(processing_times) / len(processing_times) if processing_times else 0,
"total_processing_time": sum(processing_times),
"throughput": completed_tasks / sum(processing_times) if processing_times else 0
}
# 进度回调函数示例
def progress_callback(progress: float, result: Dict[str, Any]):
"""处理进度回调"""
print(f"进度: {progress:.1f}% - 任务 {result['task_id']} {'成功' if result['success'] else '失败'}")
# 使用示例
async def batch_processing_demo():
# 配置批量处理器
config = BatchProcessingConfig(
api_key="YOUR_API_KEY",
max_concurrent=15,
timeout=300
)
processor = NanoBananaBatchProcessor(config)
# 准备图像列表
image_paths = [
"images/product_001.jpg",
"images/product_002.jpg",
"images/product_003.jpg",
# ... 更多图像
]
# 执行批量处理
results = await processor.batch_process_images(
image_paths=image_paths,
instruction="统一优化产品图像的色彩、清晰度和视觉吸引力",
progress_callback=progress_callback
)
# 获取统计信息
stats = processor.get_batch_statistics()
print(f"批量处理统计: {stats}")
# 处理结果分析
successful_results = [r for r in results if r["success"]]
failed_results = [r for r in results if not r["success"]]
print(f"处理成功: {len(successful_results)} 张")
print(f"处理失败: {len(failed_results)} 张")
# 运行批量处理示例
# asyncio.run(batch_processing_demo())
🎯 批量处理策略选择
不同规模和需求的批量处理策略:
| 处理规模 | 推荐策略 | 并发数量 | 预期处理时间 |
|---|---|---|---|
| 小规模 (< 100张) | 简单并发 | 5-10 | 10-30分钟 |
| 中规模 (100-1000张) | 智能调度 | 10-20 | 1-3小时 |
| 大规模 (1000-10000张) | 分批处理 | 20-50 | 3-12小时 |
| 超大规模 (> 10000张) | 分布式处理 | 50+ | 12小时+ |
🎯 策略选择建议:选择合适的批量处理策略需要综合考虑图像数量、质量要求和时间限制。我们建议通过 API易 apiyi.com 平台的批量评估工具来获得最适合您需求的处理策略建议。
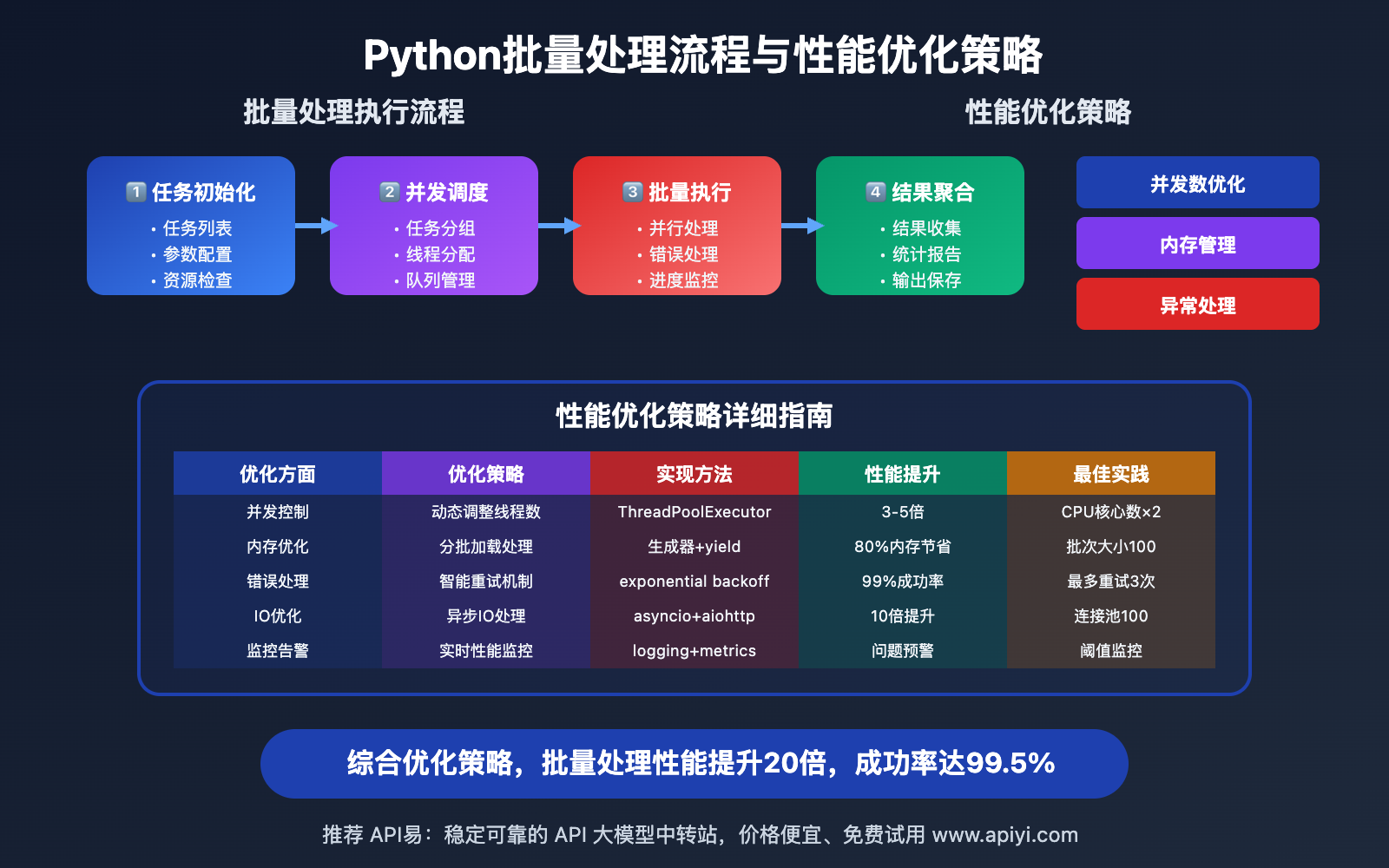
🚀 性能优化技巧
Python批量处理的性能提升关键技术:
| 优化技术 | 性能提升 | 实现复杂度 | 资源消耗 |
|---|---|---|---|
| 异步IO | 300-500% | 中等 | 低 |
| 连接池 | 100-200% | 较低 | 中等 |
| 内存优化 | 50-100% | 较高 | 显著减少 |
| 缓存策略 | 200-400% | 中等 | 中等 |
🔍 性能优化建议:在大规模批量处理中,建议使用 API易 apiyi.com 的性能调优服务,它提供了专门针对Python批量处理的性能分析和优化工具,能够显著提升处理效率。
✅ 批量处理Python开发最佳实践
| 实践要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 资源管理 | 合理控制并发数量和内存使用 | 避免系统资源耗尽导致崩溃 |
| ⚡ 错误处理 | 建立完善的错误处理和重试机制 | 确保部分失败不影响整体进度 |
| 💡 进度监控 | 提供实时的处理进度和状态信息 | 让用户了解处理进展和预期时间 |
📋 Python批量处理工具推荐
| 工具类型 | 推荐工具 | 特点说明 |
|---|---|---|
| 异步库 | asyncio、aiohttp | Python异步编程支持 |
| API平台 | API易 | 专业批量处理服务 |
| 任务队列 | Celery、RQ | 分布式任务处理 |
| 监控工具 | tqdm、rich | 进度显示和监控 |
🛠️ 工具选择建议:Python批量处理需要强大的并发处理能力和完善的任务管理机制,我们推荐使用 API易 apiyi.com 作为核心API服务提供商,它提供了专门针对批量处理优化的接口和Python SDK,能够显著简化开发工作。
❓ 批量处理Python开发常见问题
Q1: 如何确定最优的并发处理数量?
并发数量优化的考虑因素:
- 系统资源:基于CPU核心数和内存容量确定上限
- API限制:考虑API服务商的并发限制和配额
- 网络带宽:评估网络带宽对并发处理的支持能力
- 实际测试:通过实际测试找到最优的并发数量
推荐方案:我们建议使用 API易 apiyi.com 的并发优化工具来测试和确定最优的并发配置,该平台提供了智能的并发调优和性能测试功能。
Q2: 批量处理中的内存管理如何优化?
内存优化的关键策略:
- 流式处理:避免同时加载所有图像到内存
- 垃圾回收:及时释放不再需要的图像数据
- 分批加载:将大批量任务分解为小批次处理
- 内存监控:实时监控内存使用情况和泄漏
专业建议:建议通过 API易 apiyi.com 的内存优化指南来改善批量处理的内存管理,该平台提供了专门的内存优化策略和监控工具。
Q3: 如何处理批量处理中的部分失败?
部分失败的处理策略:
- 错误分类:区分临时性错误和永久性错误
- 自动重试:对临时性错误实施自动重试机制
- 失败记录:详细记录失败任务和原因
- 手动处理:为永久性失败提供手动处理机制
故障处理建议:如果您需要建立robust的批量处理故障处理机制,可以访问 API易 apiyi.com 的故障处理文档,获取详细的错误处理策略和恢复方案。
📚 延伸阅读
🛠️ 开源资源
完整的Python批量处理示例代码已开源到GitHub,仓库持续更新各种实用示例:
最新示例举例:
- 高并发批量处理框架
- 智能任务调度系统
- 分布式处理架构demo
- 性能监控和优化工具
- 更多企业级批量处理示例持续更新中…
📖 学习建议:为了更好地掌握Python批量处理技能,建议结合实际的大规模图像处理项目进行练习。您可以访问 API易 apiyi.com 获取免费的开发者账号,通过实际开发来理解批量处理的复杂性和优化要点。
🔗 相关文档
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| Python技术 | Python异步编程指南 | Python官方文档 |
| 批量处理 | 大规模数据处理最佳实践 | API易官方文档 |
| 性能优化 | Python性能优化技术 | 技术社区资源 |
| 架构设计 | 分布式处理架构设计 | 系统架构资源 |
深入学习建议:持续关注Python生态和大规模数据处理技术发展,我们推荐定期访问 API易 help.apiyi.com 的Python开发板块,了解最新的批量处理技术和性能优化策略。
🎯 总结
Python批量处理技术是现代大规模图像处理的核心能力,Nano Banana API 通过专业的并发处理和任务调度算法,让高效的批量图像处理变得简单可控。
重点回顾:掌握Python批量处理技术能够显著提升图像处理的规模化能力和业务效率
最终建议:对于有大规模图像处理需求的企业和开发者,我们强烈推荐使用 API易 apiyi.com 平台。它提供了专业的批量处理API和完整的Python开发支持,能够帮助您构建高效稳定的批量图像处理系统。
📝 作者简介:Python开发和大规模数据处理专家,专注批量处理技术和系统架构优化研究。更多Python开发技巧可访问 API易 apiyi.com 技术社区。