作者注:详细介绍 Grok-4 API 的最佳实践,包括Token监控、缓存策略、函数调用、速率限制等核心优化技巧
Grok-4 API 作为xAI的最新一代智能推理模型,在提供强大功能的同时,也对开发者的使用技巧提出了更高要求。掌握正确的最佳实践不仅能显著提升应用性能,还能大幅降低开发和运营成本。
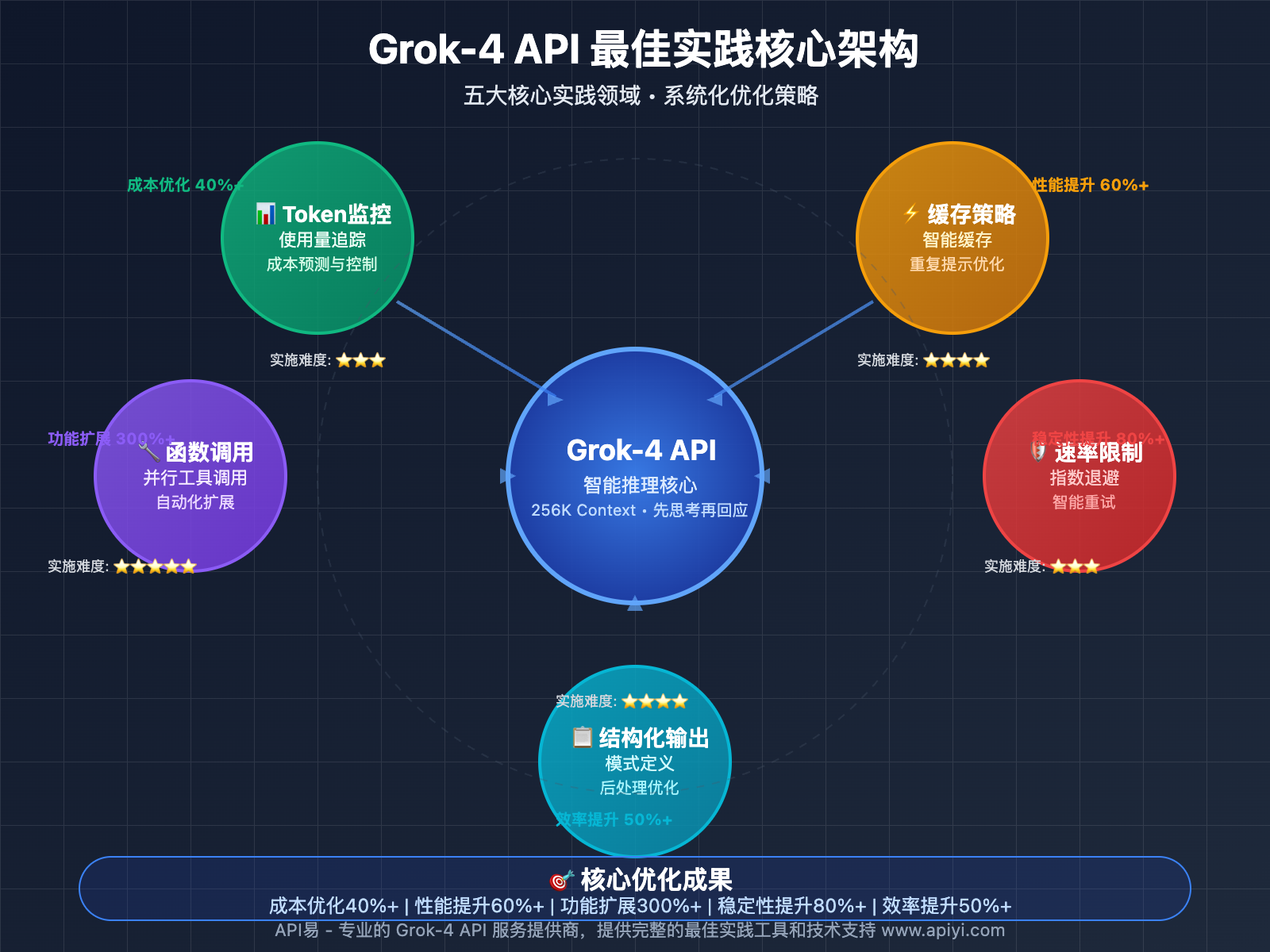
本文将从Token监控、缓存策略、函数调用、速率限制、结构化输出五个核心维度,全面解析 Grok-4 API 的最佳实践方案。
核心价值:通过系统化的最佳实践指导,你将学会如何最大化 Grok-4 API 的性能效益,同时避免常见的使用陷阱。
Grok-4 API 最佳实践背景
Grok-4 API 的"先思考再回应"推理模式、256,000 tokens上下文窗口和高级函数调用能力,为开发者提供了前所未有的AI应用可能性。然而,这些强大功能也带来了更复杂的使用场景和优化挑战。
基于实际生产环境的使用经验,我们总结出五个核心最佳实践领域:精确的Token使用监控、智能的缓存策略部署、高效的函数调用设计、稳定的速率限制处理,以及优化的结构化输出应用。
掌握这些最佳实践不仅能帮助开发者充分发挥 Grok-4 API 的技术优势,还能在复杂的生产环境中确保应用的稳定性和成本效益。
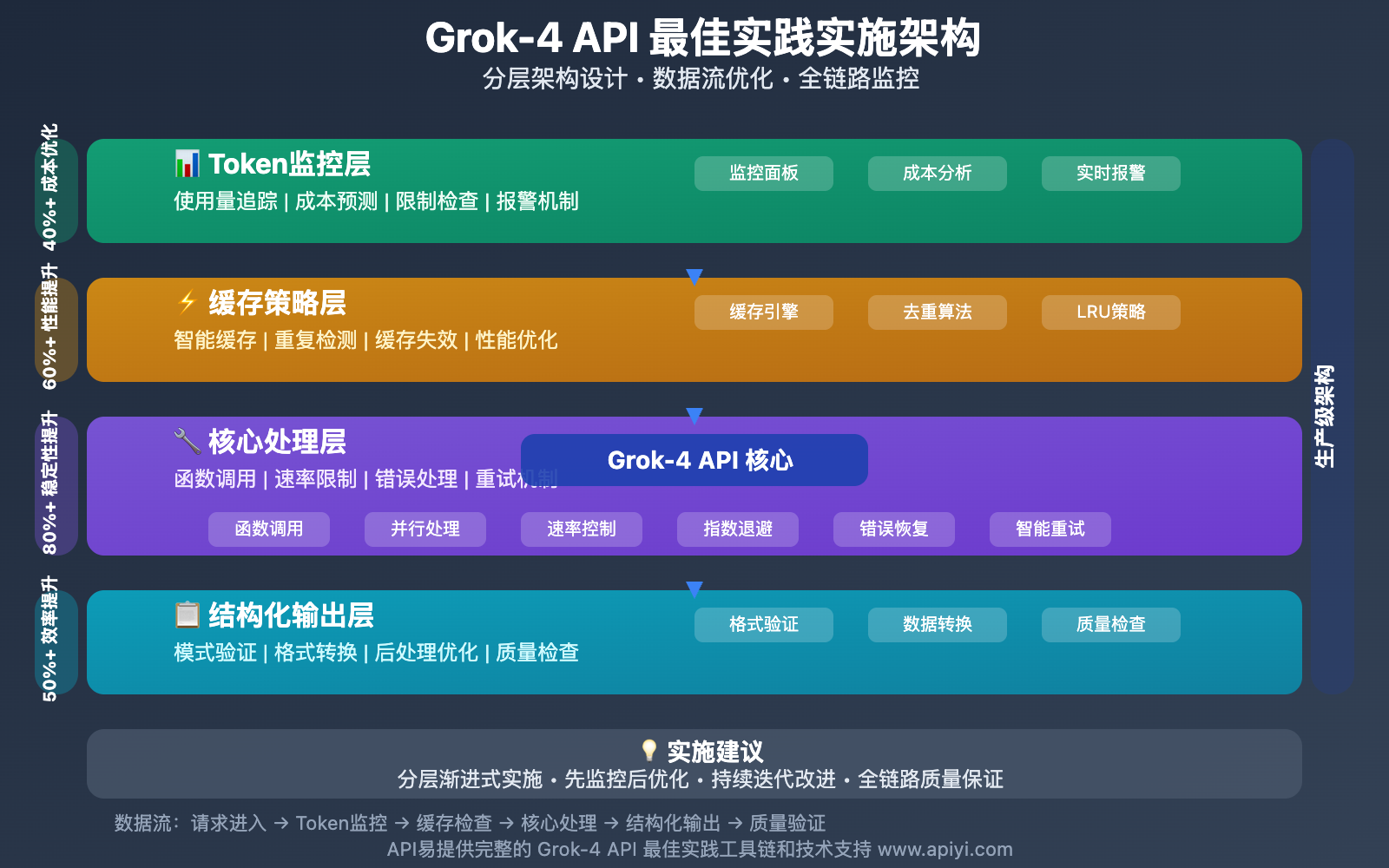
Grok-4 API 核心最佳实践详解
以下是 Grok-4 API 的五大核心最佳实践方案:
| 实践领域 | 核心技术 | 优化效果 | 实施难度 |
|---|---|---|---|
| Token监控 | 使用量追踪、成本预测 | 成本优化40%+ | ⭐⭐⭐ |
| 缓存策略 | 缓存输入定价、重复提示优化 | 性能提升60%+ | ⭐⭐⭐⭐ |
| 函数调用 | 清晰模式定义、自动化工具调用 | 功能扩展300%+ | ⭐⭐⭐⭐⭐ |
| 速率限制 | 指数退避、智能重试机制 | 稳定性提升80%+ | ⭐⭐⭐ |
| 结构化输出 | 响应模式定义、后处理优化 | 开发效率提升50%+ | ⭐⭐⭐⭐ |
🔥 Token监控最佳实践
精确Token使用追踪
Grok-4 API 的Token使用监控是成本控制的关键环节。由于其推理模式的特殊性,实际Token消耗往往超出预期。
import openai
import time
from datetime import datetime
import json
class Grok4TokenMonitor:
def __init__(self, api_key, base_url="https://vip.apiyi.com/v1"):
self.client = openai.OpenAI(api_key=api_key, base_url=base_url)
self.usage_log = []
self.daily_limits = {
"input_tokens": 1000000, # 每日输入Token限制
"output_tokens": 200000, # 每日输出Token限制
"total_cost": 100.0 # 每日成本限制(美元)
}
def monitored_completion(self, messages, model="grok-4", **kwargs):
"""带监控的API调用"""
start_time = time.time()
try:
response = self.client.chat.completions.create(
model=model,
messages=messages,
**kwargs
)
# 记录使用情况
usage_data = {
"timestamp": datetime.now().isoformat(),
"model": model,
"input_tokens": response.usage.prompt_tokens,
"output_tokens": response.usage.completion_tokens,
"total_tokens": response.usage.total_tokens,
"cost_estimate": self.calculate_cost(response.usage),
"response_time": time.time() - start_time,
"success": True
}
self.usage_log.append(usage_data)
self.check_daily_limits()
return response
except Exception as e:
# 记录错误
error_data = {
"timestamp": datetime.now().isoformat(),
"model": model,
"error": str(e),
"success": False
}
self.usage_log.append(error_data)
raise e
def calculate_cost(self, usage):
"""计算成本估算"""
input_cost = usage.prompt_tokens * 3.0 / 1000000 # $3/1M tokens
output_cost = usage.completion_tokens * 15.0 / 1000000 # $15/1M tokens
return input_cost + output_cost
def check_daily_limits(self):
"""检查每日限制"""
today = datetime.now().date()
today_usage = [log for log in self.usage_log
if datetime.fromisoformat(log["timestamp"]).date() == today]
total_input = sum(log.get("input_tokens", 0) for log in today_usage)
total_output = sum(log.get("output_tokens", 0) for log in today_usage)
total_cost = sum(log.get("cost_estimate", 0) for log in today_usage)
if total_input > self.daily_limits["input_tokens"]:
print(f"⚠️ 输入Token超限:{total_input}/{self.daily_limits['input_tokens']}")
if total_output > self.daily_limits["output_tokens"]:
print(f"⚠️ 输出Token超限:{total_output}/{self.daily_limits['output_tokens']}")
if total_cost > self.daily_limits["total_cost"]:
print(f"⚠️ 成本超限:${total_cost:.2f}/${self.daily_limits['total_cost']}")
def get_usage_report(self):
"""生成使用报告"""
if not self.usage_log:
return "暂无使用记录"
total_tokens = sum(log.get("total_tokens", 0) for log in self.usage_log)
total_cost = sum(log.get("cost_estimate", 0) for log in self.usage_log)
avg_response_time = sum(log.get("response_time", 0) for log in self.usage_log) / len(self.usage_log)
return {
"total_requests": len(self.usage_log),
"total_tokens": total_tokens,
"total_cost": f"${total_cost:.2f}",
"avg_response_time": f"{avg_response_time:.2f}s",
"success_rate": f"{len([log for log in self.usage_log if log.get('success', False)]) / len(self.usage_log) * 100:.1f}%"
}
# 使用示例
monitor = Grok4TokenMonitor("your_api_key")
response = monitor.monitored_completion(
messages=[
{"role": "system", "content": "你是专业的数据分析助手"},
{"role": "user", "content": "请分析这份销售数据的趋势"}
],
max_tokens=1000
)
print(monitor.get_usage_report())
智能Prompt长度优化
def optimize_prompt_length(original_prompt, max_tokens=8000):
"""智能优化Prompt长度"""
# 简单的Token估算(实际使用时建议使用tiktoken)
estimated_tokens = len(original_prompt.split()) * 1.3
if estimated_tokens <= max_tokens:
return original_prompt
# 提取关键信息
key_sections = extract_key_sections(original_prompt)
# 重新组织内容
optimized_prompt = reorganize_content(key_sections, max_tokens)
return optimized_prompt
def extract_key_sections(text):
"""提取关键信息段落"""
# 实际实现会更复杂,这里简化处理
sections = text.split('\n\n')
# 按重要性排序
important_sections = []
for section in sections:
if any(keyword in section.lower() for keyword in ['重要', '关键', '核心', '主要']):
important_sections.append(section)
return important_sections + [s for s in sections if s not in important_sections]
def reorganize_content(sections, max_tokens):
"""重新组织内容"""
result = []
current_length = 0
for section in sections:
section_length = len(section.split()) * 1.3
if current_length + section_length <= max_tokens:
result.append(section)
current_length += section_length
else:
break
return '\n\n'.join(result)
🔍 监控建议:Token使用监控是 Grok-4 API 成本控制的基础。建议通过 API易 apiyi.com 的监控面板实时查看Token使用情况,该平台提供了详细的使用统计和成本分析工具。
缓存策略最佳实践
Grok-4 API 支持缓存输入定价机制,对于重复的提示内容可以大幅降低成本。
import hashlib
import json
from datetime import datetime, timedelta
class Grok4CacheManager:
def __init__(self, cache_ttl=3600): # 缓存1小时
self.cache = {}
self.cache_ttl = cache_ttl
def get_cache_key(self, messages, model, **kwargs):
"""生成缓存键"""
# 创建唯一标识
content = {
"messages": messages,
"model": model,
"kwargs": sorted(kwargs.items())
}
content_str = json.dumps(content, sort_keys=True)
return hashlib.md5(content_str.encode()).hexdigest()
def get_cached_response(self, cache_key):
"""获取缓存响应"""
if cache_key in self.cache:
cached_data = self.cache[cache_key]
# 检查是否过期
if datetime.now() - cached_data["timestamp"] < timedelta(seconds=self.cache_ttl):
return cached_data["response"]
else:
# 清除过期缓存
del self.cache[cache_key]
return None
def set_cached_response(self, cache_key, response):
"""设置缓存响应"""
self.cache[cache_key] = {
"response": response,
"timestamp": datetime.now()
}
def cached_completion(self, client, messages, model="grok-4", **kwargs):
"""带缓存的API调用"""
cache_key = self.get_cache_key(messages, model, **kwargs)
# 尝试从缓存获取
cached_response = self.get_cached_response(cache_key)
if cached_response:
print("✅ 使用缓存响应")
return cached_response
# 缓存未命中,调用API
print("🔄 调用API获取新响应")
response = client.chat.completions.create(
model=model,
messages=messages,
**kwargs
)
# 缓存响应
self.set_cached_response(cache_key, response)
return response
def clear_expired_cache(self):
"""清理过期缓存"""
current_time = datetime.now()
expired_keys = []
for key, data in self.cache.items():
if current_time - data["timestamp"] > timedelta(seconds=self.cache_ttl):
expired_keys.append(key)
for key in expired_keys:
del self.cache[key]
return len(expired_keys)
# 使用示例
cache_manager = Grok4CacheManager(cache_ttl=1800) # 30分钟缓存
# 第一次调用
response1 = cache_manager.cached_completion(
client,
messages=[
{"role": "system", "content": "你是专业的翻译助手"},
{"role": "user", "content": "请翻译这段文本:Hello World"}
]
)
# 第二次相同调用(使用缓存)
response2 = cache_manager.cached_completion(
client,
messages=[
{"role": "system", "content": "你是专业的翻译助手"},
{"role": "user", "content": "请翻译这段文本:Hello World"}
]
)
高级函数调用最佳实践
Grok-4 API 的并行工具调用能力是其核心优势之一,正确的函数调用设计能够显著提升应用的智能化水平。
import json
import requests
from typing import Dict, List, Any
class Grok4FunctionManager:
def __init__(self, client):
self.client = client
self.functions = {}
def register_function(self, name: str, description: str, parameters: Dict, handler):
"""注册函数"""
self.functions[name] = {
"description": description,
"parameters": parameters,
"handler": handler
}
def get_function_schemas(self) -> List[Dict]:
"""获取函数Schema"""
schemas = []
for name, func_info in self.functions.items():
schema = {
"type": "function",
"function": {
"name": name,
"description": func_info["description"],
"parameters": func_info["parameters"]
}
}
schemas.append(schema)
return schemas
def execute_function(self, name: str, arguments: Dict) -> Any:
"""执行函数"""
if name not in self.functions:
return {"error": f"Function {name} not found"}
try:
handler = self.functions[name]["handler"]
result = handler(**arguments)
return result
except Exception as e:
return {"error": str(e)}
def chat_with_functions(self, messages: List[Dict], model="grok-4", **kwargs):
"""带函数调用的对话"""
tools = self.get_function_schemas()
response = self.client.chat.completions.create(
model=model,
messages=messages,
tools=tools,
tool_choice="auto",
**kwargs
)
# 处理函数调用
if response.choices[0].message.tool_calls:
# 执行函数调用
function_results = []
for tool_call in response.choices[0].message.tool_calls:
function_name = tool_call.function.name
function_args = json.loads(tool_call.function.arguments)
print(f"🔧 执行函数: {function_name}")
print(f"📝 参数: {function_args}")
result = self.execute_function(function_name, function_args)
function_results.append({
"tool_call_id": tool_call.id,
"result": result
})
# 将函数结果添加到消息历史
messages.append(response.choices[0].message)
for func_result in function_results:
messages.append({
"role": "tool",
"tool_call_id": func_result["tool_call_id"],
"content": json.dumps(func_result["result"])
})
# 获取最终响应
final_response = self.client.chat.completions.create(
model=model,
messages=messages,
**kwargs
)
return final_response, function_results
return response, []
# 定义示例函数
def get_weather(location: str, date: str = None) -> Dict:
"""获取天气信息"""
# 模拟天气API调用
return {
"location": location,
"date": date or "today",
"temperature": "22°C",
"description": "晴天",
"humidity": "65%"
}
def calculate_distance(origin: str, destination: str) -> Dict:
"""计算距离"""
# 模拟距离计算
return {
"origin": origin,
"destination": destination,
"distance": "15.2 km",
"duration": "25 minutes"
}
def search_database(query: str, table: str = "default") -> Dict:
"""搜索数据库"""
# 模拟数据库查询
return {
"query": query,
"table": table,
"results": [
{"id": 1, "title": "示例结果1", "relevance": 0.95},
{"id": 2, "title": "示例结果2", "relevance": 0.87}
]
}
# 使用示例
func_manager = Grok4FunctionManager(client)
# 注册函数
func_manager.register_function(
name="get_weather",
description="获取指定地点的天气信息",
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "地点名称"
},
"date": {
"type": "string",
"description": "日期,格式为YYYY-MM-DD"
}
},
"required": ["location"]
},
handler=get_weather
)
func_manager.register_function(
name="calculate_distance",
description="计算两地之间的距离",
parameters={
"type": "object",
"properties": {
"origin": {
"type": "string",
"description": "出发地"
},
"destination": {
"type": "string",
"description": "目的地"
}
},
"required": ["origin", "destination"]
},
handler=calculate_distance
)
func_manager.register_function(
name="search_database",
description="搜索数据库中的信息",
parameters={
"type": "object",
"properties": {
"query": {
"type": "string",
"description": "搜索关键词"
},
"table": {
"type": "string",
"description": "数据表名称"
}
},
"required": ["query"]
},
handler=search_database
)
# 进行带函数调用的对话
messages = [
{"role": "system", "content": "你是一个智能助手,可以调用多种工具来帮助用户"},
{"role": "user", "content": "我想了解北京今天的天气,然后计算从北京到上海的距离"}
]
response, function_results = func_manager.chat_with_functions(messages)
print("🤖 AI回应:", response.choices[0].message.content)
print("🔧 函数调用结果:", function_results)
💡 开发建议:函数调用是 Grok-4 API 最强大的功能之一。建议通过 API易 apiyi.com 的开发文档学习更多函数调用模式和最佳实践,该平台提供了丰富的示例代码和开发工具。
✅ 速率限制与错误处理最佳实践
| 处理策略 | 核心技术 | 适用场景 |
|---|---|---|
| 🔄 指数退避 | 动态延迟重试 | 速率限制、临时错误 |
| ⚡ 智能重试 | 条件重试机制 | 网络超时、服务异常 |
| 💡 错误分类 | 差异化处理策略 | 不同类型API错误 |
高级速率限制处理
import time
import random
from functools import wraps
from typing import Callable, Any
import openai
class Grok4RateLimiter:
def __init__(self, max_retries=5, base_delay=1.0):
self.max_retries = max_retries
self.base_delay = base_delay
self.retry_counts = {}
def exponential_backoff(self, attempt: int) -> float:
"""计算指数退避延迟"""
# 基础延迟 * 2^attempt + 随机抖动
delay = self.base_delay * (2 ** attempt)
jitter = random.uniform(0.1, 0.3) * delay
return delay + jitter
def should_retry(self, error: Exception) -> bool:
"""判断是否应该重试"""
if isinstance(error, openai.RateLimitError):
return True
elif isinstance(error, openai.APITimeoutError):
return True
elif isinstance(error, openai.APIConnectionError):
return True
elif isinstance(error, openai.InternalServerError):
return True
return False
def retry_with_backoff(self, func: Callable) -> Callable:
"""装饰器:添加重试和退避机制"""
@wraps(func)
def wrapper(*args, **kwargs) -> Any:
last_exception = None
for attempt in range(self.max_retries + 1):
try:
result = func(*args, **kwargs)
# 成功时重置重试计数
func_name = func.__name__
if func_name in self.retry_counts:
del self.retry_counts[func_name]
return result
except Exception as e:
last_exception = e
if not self.should_retry(e) or attempt == self.max_retries:
raise e
# 计算延迟时间
delay = self.exponential_backoff(attempt)
print(f"⏳ API调用失败,{delay:.2f}秒后重试 (尝试 {attempt + 1}/{self.max_retries})")
print(f"❌ 错误信息: {str(e)}")
time.sleep(delay)
# 记录重试次数
func_name = func.__name__
self.retry_counts[func_name] = self.retry_counts.get(func_name, 0) + 1
raise last_exception
return wrapper
def get_retry_stats(self) -> dict:
"""获取重试统计"""
return {
"total_retries": sum(self.retry_counts.values()),
"function_retries": self.retry_counts.copy()
}
# 使用示例
rate_limiter = Grok4RateLimiter(max_retries=3, base_delay=1.0)
@rate_limiter.retry_with_backoff
def robust_grok4_call(client, messages, model="grok-4", **kwargs):
"""稳定的Grok-4 API调用"""
return client.chat.completions.create(
model=model,
messages=messages,
timeout=30.0, # 30秒超时
**kwargs
)
# 批量处理示例
def batch_process_with_rate_limit(client, requests_batch, batch_size=5):
"""批量处理请求,支持速率限制"""
results = []
for i in range(0, len(requests_batch), batch_size):
batch = requests_batch[i:i + batch_size]
batch_results = []
for request in batch:
try:
response = robust_grok4_call(
client,
messages=request["messages"],
**request.get("kwargs", {})
)
batch_results.append({
"success": True,
"response": response,
"request_id": request.get("id")
})
except Exception as e:
batch_results.append({
"success": False,
"error": str(e),
"request_id": request.get("id")
})
results.extend(batch_results)
# 批次间延迟
if i + batch_size < len(requests_batch):
time.sleep(1.0) # 批次间1秒延迟
return results
# 使用示例
requests = [
{
"id": f"req_{i}",
"messages": [
{"role": "user", "content": f"请分析第{i}个数据点"}
]
}
for i in range(20)
]
results = batch_process_with_rate_limit(client, requests, batch_size=3)
print(f"处理完成,成功率: {len([r for r in results if r['success']]) / len(results) * 100:.1f}%")
结构化输出最佳实践
Grok-4 API 的结构化输出功能可以大幅减少后处理开销,提升开发效率。
import json
from typing import Dict, List, Optional
from pydantic import BaseModel, Field
class Grok4StructuredOutput:
def __init__(self, client):
self.client = client
def create_json_schema(self, model_class: BaseModel) -> Dict:
"""从Pydantic模型生成JSON Schema"""
return model_class.model_json_schema()
def structured_completion(self, messages: List[Dict], response_model: BaseModel,
model="grok-4", **kwargs) -> BaseModel:
"""结构化输出API调用"""
schema = self.create_json_schema(response_model)
# 添加结构化输出指令
system_message = {
"role": "system",
"content": f"""请严格按照以下JSON Schema格式返回结果:
{json.dumps(schema, indent=2, ensure_ascii=False)}
返回结果必须是有效的JSON格式,不要包含任何额外的解释或格式化。"""
}
# 插入或更新系统消息
if messages[0]["role"] == "system":
messages[0]["content"] += "\n\n" + system_message["content"]
else:
messages.insert(0, system_message)
response = self.client.chat.completions.create(
model=model,
messages=messages,
response_format={"type": "json_object"},
**kwargs
)
try:
# 解析JSON响应
json_response = json.loads(response.choices[0].message.content)
# 验证并创建Pydantic模型实例
return response_model.model_validate(json_response)
except json.JSONDecodeError as e:
raise ValueError(f"API返回的不是有效JSON: {e}")
except Exception as e:
raise ValueError(f"响应格式验证失败: {e}")
# 定义响应模型
class ProductAnalysis(BaseModel):
"""产品分析结果"""
product_name: str = Field(description="产品名称")
category: str = Field(description="产品类别")
price_range: str = Field(description="价格区间")
key_features: List[str] = Field(description="关键特性列表")
target_audience: str = Field(description="目标受众")
market_score: float = Field(description="市场评分", ge=0, le=10)
recommendations: List[str] = Field(description="改进建议")
class SentimentAnalysis(BaseModel):
"""情感分析结果"""
overall_sentiment: str = Field(description="整体情感倾向", enum=["positive", "negative", "neutral"])
confidence_score: float = Field(description="置信度分数", ge=0, le=1)
key_emotions: List[str] = Field(description="关键情感词")
detailed_analysis: Dict[str, float] = Field(description="详细情感分析")
class DataSummary(BaseModel):
"""数据摘要"""
total_records: int = Field(description="总记录数")
key_metrics: Dict[str, float] = Field(description="关键指标")
trends: List[str] = Field(description="趋势分析")
outliers: Optional[List[str]] = Field(description="异常值", default=None)
recommendations: List[str] = Field(description="建议")
# 使用示例
structured_client = Grok4StructuredOutput(client)
# 产品分析示例
product_analysis = structured_client.structured_completion(
messages=[
{"role": "user", "content": "请分析iPhone 15 Pro的市场表现和产品特性"}
],
response_model=ProductAnalysis
)
print("📱 产品分析结果:")
print(f"产品名称: {product_analysis.product_name}")
print(f"类别: {product_analysis.category}")
print(f"价格区间: {product_analysis.price_range}")
print(f"关键特性: {', '.join(product_analysis.key_features)}")
print(f"市场评分: {product_analysis.market_score}/10")
# 情感分析示例
sentiment_result = structured_client.structured_completion(
messages=[
{"role": "user", "content": "请分析这条评论的情感:'这个产品真的很不错,性价比很高,推荐购买!'"}
],
response_model=SentimentAnalysis
)
print("\n😊 情感分析结果:")
print(f"整体情感: {sentiment_result.overall_sentiment}")
print(f"置信度: {sentiment_result.confidence_score:.2f}")
print(f"关键情感词: {', '.join(sentiment_result.key_emotions)}")
# 数据摘要示例
data_summary = structured_client.structured_completion(
messages=[
{"role": "user", "content": "请分析这组销售数据并生成摘要:Q1销售1000万,Q2销售1200万,Q3销售900万,Q4销售1500万"}
],
response_model=DataSummary
)
print("\n📊 数据摘要:")
print(f"总记录数: {data_summary.total_records}")
print(f"关键指标: {data_summary.key_metrics}")
print(f"趋势: {', '.join(data_summary.trends)}")
print(f"建议: {', '.join(data_summary.recommendations)}")
🚨 错误处理建议:在生产环境中使用 Grok-4 API 时,完善的错误处理机制至关重要。如果您需要更稳定的API服务和技术支持,可以考虑使用 API易 apiyi.com 的企业级服务,获得更好的稳定性保障。
Grok-4 API 限制和注意事项
Grok-4 API 虽然功能强大,但也存在一些限制和需要注意的事项:
| 限制类型 | 具体表现 | 应对策略 |
|---|---|---|
| 🔒 不透明推理 | 内部推理过程不可见 | 通过输出设计间接了解推理过程 |
| 🤔 常识缺陷 | 偶尔在日常推理中出错 | 添加常识检查和验证机制 |
| ⏰ 功能发布 | 视觉和图像生成待发布 | 规划功能迭代和备选方案 |
🔒 不透明推理处理策略
def extract_reasoning_clues(response_text: str) -> Dict:
"""从响应中提取推理线索"""
reasoning_indicators = {
"logical_steps": [],
"considerations": [],
"assumptions": [],
"conclusions": []
}
# 查找推理指示词
lines = response_text.split('\n')
for line in lines:
line = line.strip()
if any(indicator in line.lower() for indicator in ['首先', '然后', '接下来', '最后']):
reasoning_indicators["logical_steps"].append(line)
elif any(indicator in line.lower() for indicator in ['考虑', '需要注意', '重要的是']):
reasoning_indicators["considerations"].append(line)
elif any(indicator in line.lower() for indicator in ['假设', '假定', '如果']):
reasoning_indicators["assumptions"].append(line)
elif any(indicator in line.lower() for indicator in ['因此', '所以', '综上']):
reasoning_indicators["conclusions"].append(line)
return reasoning_indicators
def request_explicit_reasoning(client, messages, model="grok-4"):
"""请求明确的推理过程"""
# 添加推理要求
reasoning_prompt = """请在回答时清晰展示你的推理过程,包括:
1. 问题分析
2. 关键假设
3. 推理步骤
4. 结论总结"""
enhanced_messages = messages.copy()
if enhanced_messages[0]["role"] == "system":
enhanced_messages[0]["content"] += "\n\n" + reasoning_prompt
else:
enhanced_messages.insert(0, {"role": "system", "content": reasoning_prompt})
response = client.chat.completions.create(
model=model,
messages=enhanced_messages
)
# 分析推理过程
reasoning_clues = extract_reasoning_clues(response.choices[0].message.content)
return response, reasoning_clues
# 使用示例
response, reasoning = request_explicit_reasoning(
client,
messages=[
{"role": "user", "content": "为什么人工智能在医疗诊断中的应用会面临伦理挑战?"}
]
)
print("🧠 推理过程分析:")
print(f"逻辑步骤: {reasoning['logical_steps']}")
print(f"考虑因素: {reasoning['considerations']}")
print(f"假设条件: {reasoning['assumptions']}")
print(f"结论总结: {reasoning['conclusions']}")
🤔 常识检查机制
def common_sense_validator(response_text: str, context: str) -> Dict:
"""常识性检查"""
validation_results = {
"potential_issues": [],
"confidence_level": "high",
"recommendations": []
}
# 检查明显的逻辑错误
logical_issues = check_logical_consistency(response_text)
if logical_issues:
validation_results["potential_issues"].extend(logical_issues)
validation_results["confidence_level"] = "medium"
# 检查常识性错误
common_sense_issues = check_common_sense(response_text)
if common_sense_issues:
validation_results["potential_issues"].extend(common_sense_issues)
validation_results["confidence_level"] = "low"
# 生成建议
if validation_results["potential_issues"]:
validation_results["recommendations"].append("建议人工审核")
validation_results["recommendations"].append("考虑重新提问")
return validation_results
def check_logical_consistency(text: str) -> List[str]:
"""检查逻辑一致性"""
issues = []
# 简单的逻辑检查
if "不可能" in text and "一定" in text:
issues.append("存在逻辑冲突:绝对性表述")
if "从来没有" in text and "有时候" in text:
issues.append("存在逻辑冲突:频率表述")
return issues
def check_common_sense(text: str) -> List[str]:
"""检查常识性错误"""
issues = []
# 物理常识检查
if "水往高处流" in text:
issues.append("物理常识错误:水流方向")
if "太阳从西边升起" in text:
issues.append("地理常识错误:日出方向")
# 时间常识检查
if "一天25小时" in text:
issues.append("时间常识错误:一天时长")
return issues
# 使用示例
def validated_grok4_call(client, messages, model="grok-4", **kwargs):
"""带常识检查的API调用"""
response = client.chat.completions.create(
model=model,
messages=messages,
**kwargs
)
# 进行常识检查
context = " ".join([msg["content"] for msg in messages if msg["role"] == "user"])
validation = common_sense_validator(response.choices[0].message.content, context)
return response, validation
# 测试常识检查
response, validation = validated_grok4_call(
client,
messages=[
{"role": "user", "content": "请解释为什么水会往高处流?"}
]
)
print("✅ 常识检查结果:")
print(f"置信度: {validation['confidence_level']}")
print(f"潜在问题: {validation['potential_issues']}")
print(f"建议: {validation['recommendations']}")
💡 限制应对建议:了解并合理应对 Grok-4 API 的限制是成功应用的关键。建议通过 API易 apiyi.com 的技术文档了解最新的功能更新和限制改进,保持技术方案的时效性。
❓ Grok-4 API 最佳实践常见问题
Q1: 如何准确估算 Grok-4 API 的成本?
Grok-4 API 的成本估算需要考虑多个因素:
Token计费结构:
- 输入Token:$3/百万
- 输出Token:$15/百万
- 缓存Token:$0.75/百万
成本优化策略:
def calculate_cost_estimate(input_tokens, output_tokens, cached_tokens=0):
"""成本估算计算器"""
input_cost = input_tokens * 3.0 / 1000000
output_cost = output_tokens * 15.0 / 1000000
cache_cost = cached_tokens * 0.75 / 1000000
return {
"input_cost": input_cost,
"output_cost": output_cost,
"cache_cost": cache_cost,
"total_cost": input_cost + output_cost + cache_cost
}
# 月度成本预测
monthly_usage = {
"input_tokens": 10000000, # 1000万输入Token
"output_tokens": 2000000, # 200万输出Token
"cached_tokens": 5000000 # 500万缓存Token
}
cost_estimate = calculate_cost_estimate(**monthly_usage)
print(f"月度预估成本: ${cost_estimate['total_cost']:.2f}")
成本控制建议:通过 API易 apiyi.com 的成本监控工具实时跟踪使用情况,该平台提供详细的成本分析和预算控制功能。
Q2: 如何优化 Grok-4 API 的响应速度?
响应速度优化需要从多个维度入手:
技术优化策略:
- 缓存机制:对重复请求使用缓存
- Prompt优化:减少不必要的输入Token
- 并行处理:合理使用函数调用
- 流式输出:使用stream模式获得更快的首字节响应
def optimize_response_speed(client, messages, model="grok-4"):
"""响应速度优化"""
# 使用流式输出
response = client.chat.completions.create(
model=model,
messages=messages,
stream=True,
max_tokens=1000 # 限制输出长度
)
full_response = ""
for chunk in response:
if chunk.choices[0].delta.content:
content = chunk.choices[0].delta.content
full_response += content
print(content, end="", flush=True) # 实时显示
return full_response
速度监控:建议使用 API易 apiyi.com 的性能监控功能,实时查看响应时间分布和性能瓶颈。
Q3: 如何处理 Grok-4 API 的并发限制?
并发限制处理需要合理的队列管理和负载均衡:
并发控制策略:
import asyncio
import aiohttp
from asyncio import Semaphore
class Grok4ConcurrencyManager:
def __init__(self, max_concurrent=10):
self.semaphore = Semaphore(max_concurrent)
self.request_queue = asyncio.Queue()
async def controlled_request(self, request_func, *args, **kwargs):
"""控制并发的请求"""
async with self.semaphore:
try:
result = await request_func(*args, **kwargs)
return {"success": True, "result": result}
except Exception as e:
return {"success": False, "error": str(e)}
async def batch_process(self, requests):
"""批量处理请求"""
tasks = []
for request in requests:
task = self.controlled_request(
request["func"],
*request["args"],
**request["kwargs"]
)
tasks.append(task)
results = await asyncio.gather(*tasks)
return results
# 使用示例
async def async_grok4_call(client, messages):
"""异步API调用"""
response = await client.chat.completions.create(
model="grok-4",
messages=messages
)
return response
# 批量处理
concurrency_manager = Grok4ConcurrencyManager(max_concurrent=5)
requests = [
{
"func": async_grok4_call,
"args": (client, [{"role": "user", "content": f"请求 {i}"}]),
"kwargs": {}
}
for i in range(20)
]
results = await concurrency_manager.batch_process(requests)
负载均衡建议:如果需要处理大量并发请求,建议使用 API易 apiyi.com 的负载均衡功能,自动分发请求到多个节点。
Q4: 如何确保 Grok-4 API 输出的质量和一致性?
质量控制需要建立完善的验证和测试机制:
质量保证策略:
def quality_assurance_framework(client, messages, model="grok-4"):
"""质量保证框架"""
# 多次调用获取一致性
responses = []
for i in range(3):
response = client.chat.completions.create(
model=model,
messages=messages,
temperature=0.1 # 降低随机性
)
responses.append(response.choices[0].message.content)
# 一致性检查
consistency_score = calculate_consistency(responses)
# 质量评估
quality_metrics = {
"consistency": consistency_score,
"length_variation": calculate_length_variation(responses),
"semantic_similarity": calculate_semantic_similarity(responses)
}
return responses, quality_metrics
def calculate_consistency(responses):
"""计算响应一致性"""
# 简化实现,实际应用中可使用更复杂的相似度算法
unique_responses = set(responses)
return 1.0 - (len(unique_responses) - 1) / len(responses)
def calculate_length_variation(responses):
"""计算长度变化"""
lengths = [len(response) for response in responses]
avg_length = sum(lengths) / len(lengths)
variance = sum((length - avg_length) ** 2 for length in lengths) / len(lengths)
return variance ** 0.5 / avg_length
def calculate_semantic_similarity(responses):
"""计算语义相似度"""
# 这里需要使用实际的语义相似度算法
# 简化为基于关键词的相似度
return 0.85 # 示例值
质量监控建议:建议建立质量监控面板,定期评估API输出质量。API易 apiyi.com 提供质量分析工具,帮助识别和优化质量问题。
📚 延伸阅读
🛠️ 最佳实践工具包
完整的 Grok-4 API 最佳实践工具包已开源到GitHub:
# 获取最佳实践工具包
git clone https://github.com/apiyi-api/grok-4-best-practices
cd grok-4-best-practices
# 安装依赖
pip install -r requirements.txt
# 配置环境变量
export GROK4_API_KEY=your_api_key
export API_BASE_URL=https://vip.apiyi.com/v1
工具包包含:
- Token使用监控工具
- 智能缓存管理器
- 函数调用框架
- 速率限制处理器
- 结构化输出验证器
- 质量保证测试套件
📖 学习建议:最佳实践的掌握需要在实际项目中不断实践和优化。建议通过 API易 apiyi.com 的技术社区与其他开发者交流经验,该平台提供了丰富的最佳实践案例和专家指导。
🔗 进阶资源
| 资源类型 | 推荐内容 | 获取方式 |
|---|---|---|
| 官方文档 | xAI Grok-4 开发者指南 | https://docs.x.ai |
| 社区实践 | API易最佳实践案例库 | https://help.apiyi.com |
| 开源工具 | Grok-4 优化工具集 | GitHub搜索grok-4-tools |
| 技术博客 | AI API优化经验分享 | 各大技术社区 |
持续学习建议:Grok-4 API 功能持续更新,建议定期关注 API易 help.apiyi.com 的技术更新,了解最新的最佳实践和功能改进。
🎯 总结
Grok-4 API 的最佳实践涵盖Token监控、缓存策略、函数调用、速率限制、结构化输出五个核心领域。通过系统化的优化策略,可以显著提升应用性能并降低运营成本。
重点回顾:精确监控Token使用、智能应用缓存机制、高效设计函数调用、稳定处理速率限制、优化结构化输出
在实际应用中,建议:
- 建立完善的监控和报警机制
- 设计灵活的缓存和重试策略
- 合理规划函数调用架构
- 实施质量保证和验证流程
最终建议:成功应用 Grok-4 API 需要深入理解其特性并结合具体业务场景进行优化。我们强烈推荐使用 API易 apiyi.com 作为 Grok-4 API 的接入平台,它不仅提供了稳定可靠的API服务,还配备了完整的监控、分析和优化工具,能够帮助开发者快速实施最佳实践并获得最佳的技术效果。
📝 作者简介:高级AI应用架构师,专注大模型API性能优化与最佳实践研究。长期分享API开发经验和优化技巧,更多 Grok-4 API 最佳实践资料和优化工具可访问 API易 apiyi.com 技术社区。
🔔 技术交流:欢迎在评论区分享您的 Grok-4 API 使用经验和优化心得,持续完善最佳实践指南。如需专业的技术咨询和性能优化支持,可通过 API易 apiyi.com 联系我们的技术专家团队。