站长注:深度解析LMArena排行榜各分类排名,帮你选择国际认可度高且性价比优秀的AI大模型
面对市场上众多AI大模型,如何选择国际认可度高且性价比优秀的模型成为开发者和企业的关键难题。本文将基于权威的LMArena排行榜深度分析,为你提供科学的模型选择策略。
📌 快速开始体验
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持Chatbot Arena顶级模型全系列,让AI模型选择更简单
注册可送 1.1 美金额度起,约 300万 Tokens 额度体验。立即免费注册
💬 加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。
AI大模型选择 背景介绍
随着AI技术的快速发展,市场上涌现出众多大语言模型,从OpenAI的GPT系列到Google的Gemini,从Anthropic的Claude到国产的DeepSeek等。面对如此多样的选择,企业和开发者往往陷入选择困难:哪个模型在国际上认可度最高?哪个模型性价比最优?不同场景下应该选择哪个模型?
LMArena (lmarena.ai) 作为全球最权威的AI模型评测平台,通过众包的方式收集用户真实使用反馈,采用ELO评分系统对各大模型进行排名,为我们提供了客观、权威的参考依据。

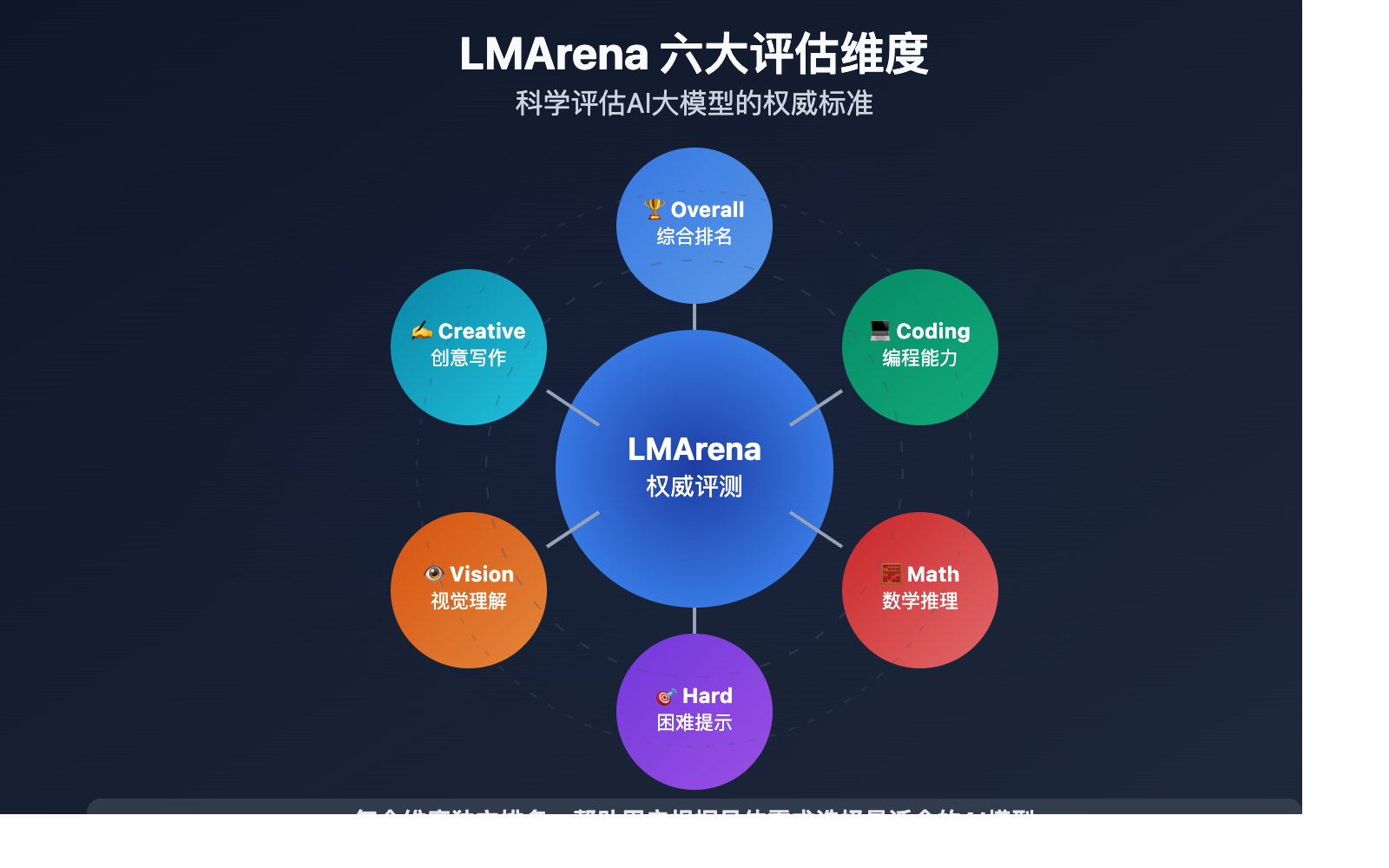
AI大模型选择 核心评估维度
基于LMArena排行榜的评估体系,我们可以从以下维度科学评估AI大模型:
| 评估维度 | 评估标准 | 重要性说明 | 权威性 |
|---|---|---|---|
| 🏆 Overall排名 | 综合表现评分 | 反映模型整体能力水平 | ⭐⭐⭐⭐⭐ |
| 💻 Coding编程 | 代码生成与调试能力 | 开发者关注的核心指标 | ⭐⭐⭐⭐⭐ |
| 🧮 Math数学 | 数学推理与计算能力 | 逻辑思维的重要体现 | ⭐⭐⭐⭐ |
| 🎯 Hard Prompts困难提示 | 复杂任务处理能力 | 模型智能程度的试金石 | ⭐⭐⭐⭐⭐ |
| 👁️ Vision视觉 | 图像理解与分析能力 | 多模态应用的基础 | ⭐⭐⭐⭐ |
| ✍️ Creative Writing创意写作 | 文本创作与语言表达 | 内容创作场景必备 | ⭐⭐⭐⭐ |
🔥 LMArena排行榜权威性解析
什么是LMArena?
LMArena(lmarena.ai)是由加州大学伯克利分校LMSYS团队开发的全球最权威AI模型评测平台。该平台采用匿名对战的方式,让用户在不知道模型身份的情况下进行盲测投票,确保评估结果的客观性和公正性。
ELO评分系统的科学性
LMArena采用源自国际象棋的ELO评分系统,通过大量真实用户的对比投票计算模型得分。这种方法相比传统的基准测试更能反映模型在实际使用中的表现,具有以下优势:
- 真实用户反馈:基于实际使用场景的评估
- 动态更新机制:随着新数据不断调整排名
- 防作弊设计:匿名对战避免品牌偏见
- 大样本统计:每月收集数十万投票数据

AI大模型选择 应用场景分析
基于LMArena不同分类排行榜,我们来分析各场景下的最佳模型选择:
| 应用场景 | 对应LMArena分类 | 推荐模型类型 | 性价比考量 |
|---|---|---|---|
| 🎯 通用AI助手 | Overall整体排名 | GPT-4o、Claude-4、Gemini-Pro | 综合能力与成本平衡 |
| 🚀 代码开发 | Coding编程分类 | o3、Claude-4、DeepSeek-Coder | 编程专精度优先 |
| 💡 数据分析 | Math数学分类 | o3-mini、Claude-4、Gemini-Pro | 推理准确性关键 |
| 🧠 复杂任务处理 | Hard Prompts分类 | o3、Claude-4-Opus | 能力天花板重要 |
| 📸 图像理解 | Vision视觉分类 | GPT-4o、Gemini-Pro、Claude-4 | 多模态能力必需 |
| ✍️ 内容创作 | Creative Writing分类 | Claude-4、GPT-4o | 创意表达力优先 |
AI大模型选择 开发指南
🎯 基于LMArena的模型选择策略
💡 服务介绍
API易,AI行业领先的API中转站,均为官方源头转发,价格有优势,聚合各种优秀大模型,使用方便:一个令牌,无限模型。企业级专业稳定的 OpenAI o3/Claude 4/Gemini 2.5 Pro/Deepseek R1/Grok 等全模型官方同源接口的中转分发。优势很多:不限速,不过期,不惧封号,按量计费,长期可靠服务;让技术助力科研、让 AI 加速公司业务发展!
🔥 LMArena顶级模型推荐(均为稳定供给)
基于最新LMArena排行榜数据,全部模型和价格请看网站后台 https://www.apiyi.com/account/pricing
| 模型系列 | LMArena排名 | 特色说明 | 推荐指数 |
|---|---|---|---|
| OpenAI o3系列 | Overall #1 | 推理能力王者,硬提示表现卓越 | ⭐⭐⭐⭐⭐ |
| Claude 4系列 | Overall Top3 | 编程和创意写作双优,安全性高 | ⭐⭐⭐⭐⭐ |
| Gemini 2.5 Pro | Vision #1 | 多模态能力突出,谷歌生态优势 | ⭐⭐⭐⭐⭐ |
| GPT-4o | 均衡表现 | 综合能力强,API调用稳定 | ⭐⭐⭐⭐ |
| DeepSeek R1 | 性价比王者 | 推理能力强,价格极具优势 | ⭐⭐⭐⭐⭐ |
📋 完整LMArena对应模型列表(点击展开)
🔹 顶级推理模型
o3:LMArena Hard Prompts排名第一,推理能力最强(推荐指数:⭐⭐⭐⭐⭐)o3-mini:性价比推理选择,适合复杂逻辑任务deepseek-r1:国产推理模型代表,价格优势明显
🔹 编程专家模型
claude-sonnet-4-20250514:LMArena Coding分类顶级表现(推荐指数:⭐⭐⭐⭐⭐)claude-opus-4-20250514:超大杯模型,编程能力天花板deepseek-v3:开源编程模型领导者
🔹 多模态视觉模型
gemini-2.5-pro-preview-05-06:LMArena Vision分类领先(推荐指数:⭐⭐⭐⭐⭐)gpt-4o:视觉理解均衡选择claude-sonnet-4-20250514:视觉+推理组合优势
🔹 创意写作模型
claude-opus-4-20250514:Creative Writing分类顶级gpt-4o:内容创作均衡选择gemini-2.5-pro-preview-05-06:多语言创作能力
🔹 经济型选择
gpt-4o-mini:基础任务性价比选择deepseek-v3:国产高质量经济选择gemini-2.5-flash-preview:谷歌经济型选择
⚡ 重要提示
建议对话场景,使用 流式输出。
🎯 基于LMArena分类的场景推荐表
| LMArena分类 | 首选模型 | 备选模型 | 经济型选择 | 特点说明 |
|---|---|---|---|---|
| 🔥 Overall综合 | o3 |
claude-opus-4 |
gpt-4o-mini |
全能型任务的最佳选择 |
| 💻 Coding编程 | claude-sonnet-4 |
o3 |
deepseek-v3 |
代码生成和调试专家 |
| 🧮 Math数学 | o3 |
o3-mini |
deepseek-r1 |
逻辑推理和计算精准 |
| 🎯 Hard Prompts困难 | o3 |
claude-opus-4 |
deepseek-r1 |
复杂任务处理能力 |
| 👁️ Vision视觉 | gemini-2.5-pro |
gpt-4o |
claude-sonnet-4 |
图像理解和分析 |
| ✍️ Creative创意 | claude-opus-4 |
gpt-4o |
gemini-2.5-pro |
文本创作和语言表达 |
💰 价格参考:具体价格请参考 API易价格页面
💻 基于LMArena排名的实践示例
# 🚀 LMArena顶级模型调用示例
curl https://vip.apiyi.com/v1/chat/completions \
-H "Content-Type: application/json" \
-H "Authorization: Bearer $替换你的API易后台的Key$" \
-d '{
"model": "o3",
"stream": true,
"messages": [
{"role": "system", "content": "你是一个基于LMArena排行榜选择的顶级AI助手。"},
{"role": "user", "content": "请帮我分析这段代码的时间复杂度"}
]
}'
✅ AI大模型选择 最佳实践
| 实践要点 | 具体建议 | 注意事项 |
|---|---|---|
| 🎯 场景优先 | 根据LMArena分类选择对应强项模型 | 避免用Overall排名套用所有场景 |
| ⚡ 性价比平衡 | 结合任务复杂度选择合适级别模型 | 简单任务无需使用顶级模型 |
| 💡 动态调整 | 关注LMArena排名变化,及时切换 | 排行榜每周更新,保持敏感度 |
| 🔄 A/B测试 | 对比不同模型在实际业务中表现 | LMArena数据需结合业务验证 |
❓ AI大模型选择 常见问题
Q1: LMArena排名是否完全可信?如何理性看待?
LMArena排名具有很高的参考价值,但需要理性看待:
权威性优势:
- 基于真实用户投票,避免刷榜
- 采用ELO评分系统,科学性较强
- 样本量大,统计意义显著
局限性考量:
- 用户群体可能存在偏好
- 不同地区用户习惯差异
- 某些专业领域可能样本不足
建议策略:参考LMArena排名 + 结合业务实测 + 关注多个评测维度
Q2: 如何在性能和成本之间找到最佳平衡点?
基于LMArena排名的性价比优化策略:
分层使用策略:
- 核心业务:使用Overall前3模型
- 常规任务:选择LMArena前10模型
- 批量处理:优先考虑经济型选择
成本控制技巧:
- 根据LMArena分类排名选择专项模型
- 利用API易的按量计费优势
- 通过prompt优化减少token消耗
Q3: 国产模型在LMArena上表现如何?值得选择吗?
国产模型在LMArena上表现越来越亮眼:
突出表现:
- DeepSeek系列在推理任务上表现优异
- 价格优势明显,API易提供稳定服务
- 在特定中文任务上有独特优势
选择建议:
- 成本敏感场景优先考虑国产模型
- 结合LMArena排名和实际测试
- 关注模型更新频率和社区活跃度
🏆 为什么选择「API易」AI大模型API聚合平台
| 核心优势 | 具体说明 | LMArena相关优势 |
|---|---|---|
| 🛡️ LMArena顶级模型全覆盖 | • 涵盖LMArena排行榜前20模型 • 实时同步最新排名模型 • 确保访问权威评测认可的模型 |
跟随国际最权威评测标准 |
| 🎨 多分类优势模型支持 | • Coding、Math、Vision全分类覆盖 • 专项任务可选择对应强项模型 • 一个API密钥访问所有分类冠军 |
基于LMArena科学选择 |
| ⚡ 国际认可的性能保障 | • LMArena排名前列模型稳定供给 • 不限速调用国际认可模型 • 7×24 技术支持保障服务质量 |
性能获得国际用户验证 |
| 🔧 开发者友好接入 | • OpenAI兼容接口标准 • 支持LMArena所有评测模型 • 完善的API文档和示例 |
快速验证LMArena推荐模型 |
| 💰 透明的性价比优势 | • 基于LMArena排名的模型定价 • 按量计费,无隐藏成本 • 免费额度支持模型对比测试 |
让高排名模型更经济实用 |
💡 LMArena优势应用示例
当你需要选择编程助手时,可以:
- 查看LMArena Coding分类排名
- 通过API易直接调用排名前列的模型
- 无需多平台注册,一键体验顶级编程模型
- 基于真实使用效果做出最终选择
🎯 总结
选择合适的AI大模型不再是盲目试错,而应该基于科学的评估体系。LMArena排行榜为我们提供了国际认可的权威参考,结合不同分类排名,我们可以精准选择最适合特定场景的模型。
重点回顾:
- 参考权威排名:LMArena基于真实用户投票,具有强参考价值
- 分类精准选择:根据Overall、Coding、Math等分类选择专项优势模型
- 性价比平衡:结合业务需求和成本考量,选择最适合的模型级别
- 动态优化调整:关注排名变化,及时切换到表现更优的模型
📞 立即开始体验
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持LMArena排行榜全系列顶级模型,让科学选择更简单
💬 加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。

📝 本文作者:API易团队
🔔 关注更新:欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。