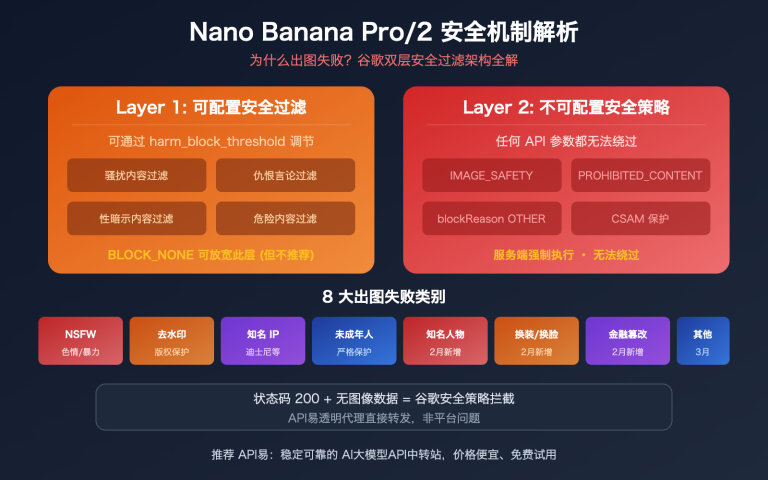
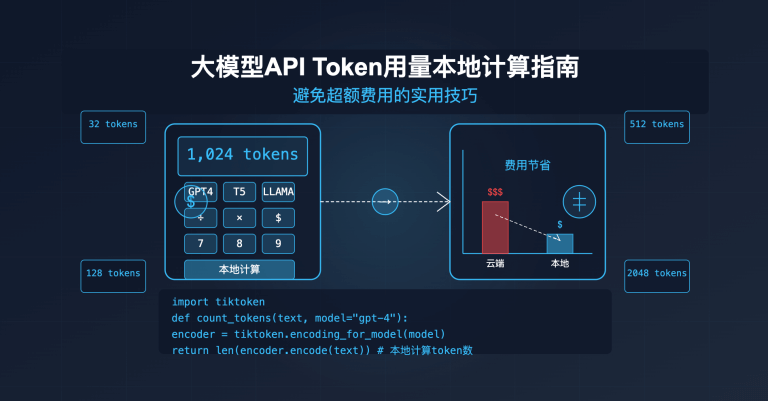
站长注:深入分析API请求超时原因,提供多种有效解决方案,包括增加超时时间、优化代码和使用专用访问通道,帮助开发者稳定调用大模型API。
在使用大模型API进行开发时,您可能会遇到以下超时错误:
WARNING:root:Request timed out: HTTPSConnectionPool(host='vip.apiyi.com', port=443): Read timed out. (read timeout=40.0)
这类错误可能会严重影响应用的稳定性和用户体验。本文将深入分析导致API调用超时的原因,并提供多种实用的解决方案,帮助您高效稳定地进行API调用。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
支持GPT-4o、Claude、Gemini等全系列顶级大语言模型,提供稳定高效的API调用服务
注册可送 1.1 美金额度起,约 300万 Tokens 额度体验。立即免费注册
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。
导致API调用超时的常见原因
当您遇到”Read timed out”错误时,可能是由以下几个因素导致的:
1. 网络连接问题
- 网络波动:网络不稳定导致连接中断或延迟
- ISP限制:部分ISP对某些域名或IP的访问有限制
- 代理配置:公司网络或VPN设置可能影响外部API的访问
- DNS解析慢:域名解析延迟导致连接建立时间过长
2. 服务器端因素
- 高负载:API服务器处于高负载状态,响应变慢
- 资源密集型请求:如生成长文本或复杂图像的请求需要更长处理时间
- 后端连接限制:API提供商对并发连接数有限制
- 跨地域访问:服务器与客户端位于不同地区,增加了网络延迟
3. 客户端配置问题
- 超时设置过短:默认超时设置不足以完成复杂请求
- 连接池配置不当:未正确配置HTTP连接池,导致连接资源耗尽
- 请求过大:发送的请求体积过大,导致上传时间过长
- 资源限制:客户端机器资源不足,影响网络I/O处理
多维度解决方案
针对上述问题,我们提供以下解决方案,从简单到复杂,您可以根据自身情况选择合适的方法:
解决方案一:增加请求超时时间
最简单的解决方法是增加客户端的超时设置。以Python为例:
import requests
# 之前的代码
# response = requests.post(url, json=payload, headers=headers, timeout=40)
# 修改后 - 增加超时时间
response = requests.post(
url,
json=payload,
headers=headers,
timeout=120 # 增加到120秒
)
对于不同的编程语言,调整方式略有不同:
JavaScript (Node.js) 示例:
const axios = require('axios');
// 创建自定义实例,设置更长的超时时间
const apiClient = axios.create({
timeout: 120000 // 120秒,单位为毫秒
});
apiClient.post(url, payload, { headers })
.then(response => {
// 处理响应
})
.catch(error => {
console.error('请求失败:', error);
});
Java 示例:
import java.net.http.HttpClient;
import java.net.http.HttpRequest;
import java.net.http.HttpResponse;
import java.time.Duration;
// 创建带有自定义超时的HttpClient
HttpClient client = HttpClient.newBuilder()
.connectTimeout(Duration.ofSeconds(30)) // 连接超时
.timeout(Duration.ofSeconds(120)) // 读取超时
.build();
// 使用此客户端进行请求

解决方案二:实现智能重试机制
为了处理临时性网络问题,实现智能重试机制是一个有效的方法:
import requests
import time
import random
def api_request_with_retry(url, payload, headers, max_retries=3, base_delay=2):
"""
实现带有指数退避的重试机制
参数:
- url: API端点URL
- payload: 请求体
- headers: 请求头
- max_retries: 最大重试次数
- base_delay: 初始重试延迟(秒)
返回:
- 成功时返回响应对象,全部失败则返回None
"""
for attempt in range(max_retries + 1):
try:
# 增加超时设置
response = requests.post(
url,
json=payload,
headers=headers,
timeout=90 # 90秒超时
)
response.raise_for_status() # 检查HTTP状态码
return response
except (requests.exceptions.Timeout,
requests.exceptions.ConnectionError) as e:
if attempt < max_retries:
# 计算下一次重试的延迟(指数退避+抖动)
delay = base_delay * (2 ** attempt) + random.uniform(0, 1)
print(f"请求超时,{delay:.2f}秒后进行第{attempt+1}次重试...")
time.sleep(delay)
else:
print(f"达到最大重试次数({max_retries}),请求失败")
return None
except requests.exceptions.HTTPError as e:
# 对于某些HTTP错误(如429 Too Many Requests),也可以重试
if response.status_code == 429 and attempt < max_retries:
delay = base_delay * (2 ** attempt) + random.uniform(0, 1)
print(f"请求限速,{delay:.2f}秒后进行第{attempt+1}次重试...")
time.sleep(delay)
else:
print(f"HTTP错误: {e}")
return None
except Exception as e:
print(f"未知错误: {e}")
return None
# 使用示例
response = api_request_with_retry(
"https://vip.apiyi.com/v1/chat/completions",
payload={"model": "gpt-4o", "messages": [...], "max_tokens": 500},
headers={"Authorization": "Bearer YOUR_API_KEY"}
)
解决方案三:优化连接池配置
对于高并发场景,合理配置HTTP连接池可以显著提高稳定性:
import requests
from requests.adapters import HTTPAdapter
from urllib3.util.retry import Retry
# 创建会话并配置连接池
def create_optimized_session():
session = requests.Session()
# 配置重试策略
retry_strategy = Retry(
total=3, # 总重试次数
backoff_factor=1, # 重试间隔因子
status_forcelist=[429, 500, 502, 503, 504], # 需要重试的HTTP状态码
allowed_methods=["HEAD", "GET", "POST"] # 允许重试的请求方法
)
# 配置连接池适配器
adapter = HTTPAdapter(
max_retries=retry_strategy,
pool_connections=20, # 连接池中允许的连接数
pool_maxsize=50 # 连接池中单个连接的最大请求数
)
# 挂载适配器
session.mount("http://", adapter)
session.mount("https://", adapter)
return session
# 使用优化后的会话进行请求
session = create_optimized_session()
response = session.post(
"https://vip.apiyi.com/v1/chat/completions",
json=payload,
headers=headers,
timeout=90
)
解决方案四:使用专用访问通道(推荐)
对于付费客户,API易提供了专用访问通道,可以绕过常规域名解析,直接通过内部网络访问API服务,大大提高连接稳定性和响应速度。
如何使用专用通道:
- 将您代码中的API基础URL从
https://vip.apiyi.com替换为专用通道地址 - 其他代码保持不变,如API端点、参数和认证方式
以Python代码为例,修改方式如下:
# 替换前
base_url = "https://vip.apiyi.com/v1"
# 替换后
base_url = "专用通道地址/v1" # 付费客户可联系客服获取专用地址
注意: 专用通道地址仅对付费客户开放,如需获取,请联系API易客服。免费用户可以优先考虑上述其他解决方案。
解决方案五:使用流式响应模式
对于生成大量内容的请求,使用流式响应模式可以避免超时问题:
import requests
headers = {
"Content-Type": "application/json",
"Authorization": f"Bearer {API_KEY}"
}
payload = {
"model": "gpt-4o",
"messages": [{"role": "user", "content": "写一篇长文章..."}],
"stream": True # 启用流式响应
}
# 发送流式请求
response = requests.post(
"https://vip.apiyi.com/v1/chat/completions",
json=payload,
headers=headers,
stream=True, # 客户端也需设置stream=True
timeout=30 # 连接超时可以设置较短
)
# 处理流式响应
content = ""
for line in response.iter_lines():
if line:
line_text = line.decode('utf-8')
if line_text.startswith('data: ') and not line_text.startswith('data: [DONE]'):
chunk_data = json.loads(line_text[6:])
if 'choices' in chunk_data and len(chunk_data['choices']) > 0:
delta = chunk_data['choices'][0].get('delta', {})
if 'content' in delta:
content_chunk = delta['content']
content += content_chunk
print(content_chunk, end='', flush=True)
print("\n完整内容:", content)
常见问题解答
超时时间设置多长比较合适?
根据不同请求的复杂度,建议设置:
- 简单会话请求:30-60秒
- 复杂文本生成:60-120秒
- 图像生成请求:120-180秒
- 流式响应模式:连接建立可设为30秒,读取超时可以更长
为什么有时候API调用会很慢?
大型语言模型或图像生成模型需要大量计算资源,处理复杂请求可能需要更长时间。此外,以下因素也会影响速度:
- 当前服务负载情况
- 用户请求的复杂度
- 网络条件
- 内容审核或过滤流程
专用访问通道有什么优势?
专用访问通道具有以下优势:
- 绕过常规DNS解析,直接访问API服务器
- 减少网络跳转次数,降低延迟
- 专用资源池,更稳定的服务质量
- 更高的请求处理优先级
不同模型的响应时间有区别吗?
是的,不同模型的响应时间会有显著差异:
- 轻量级模型(如Gemini-1.5-flash)通常响应更快
- 大型模型(如GPT-4o、Claude-3-Opus)可能需要更长处理时间
- 图像生成模型通常比纯文本模型需要更多时间
高级开发者调用建议
对于需要在生产环境中大规模使用API的开发者,我们提供以下高级建议:
1. 实现分层超时策略
def tiered_timeout_request(url, payload, headers, complexity='medium'):
"""根据请求复杂度调整超时时间"""
# 基于请求复杂度定义超时
timeouts = {
'simple': 45, # 简单请求
'medium': 90, # 中等复杂度
'complex': 180 # 复杂请求
}
# 判断复杂度的逻辑(可自定义)
if 'complexity' not in locals():
# 例如:长提示词、生成图像等复杂请求
if len(str(payload.get('messages', []))) > 1000 or 'image' in str(payload):
complexity = 'complex'
# 简单问答
elif len(str(payload.get('messages', []))) < 200:
complexity = 'simple'
timeout = timeouts.get(complexity, 90)
print(f"使用{complexity}级别超时: {timeout}秒")
return requests.post(url, json=payload, headers=headers, timeout=timeout)
2. 使用异步请求框架
对于高并发场景,考虑使用异步框架如asyncio和aiohttp:
import asyncio
import aiohttp
async def async_api_request(url, payload, headers, timeout=90):
"""异步API请求处理器"""
async with aiohttp.ClientSession() as session:
try:
async with session.post(
url,
json=payload,
headers=headers,
timeout=aiohttp.ClientTimeout(total=timeout)
) as response:
if response.status == 200:
return await response.json()
else:
print(f"请求失败: HTTP {response.status}")
return None
except asyncio.TimeoutError:
print(f"请求超时 (>{timeout}秒)")
return None
except Exception as e:
print(f"请求异常: {e}")
return None
# 批量异步请求示例
async def process_multiple_requests(requests_data):
tasks = []
for i, data in enumerate(requests_data):
task = async_api_request(
"https://vip.apiyi.com/v1/chat/completions",
data["payload"],
data["headers"]
)
tasks.append(task)
return await asyncio.gather(*tasks)
# 运行异步批处理
results = asyncio.run(process_multiple_requests(batch_data))
3. 自动切换备用端点
对于关键业务应用,可以实现端点自动切换逻辑:
def resilient_api_request(payload, headers, max_attempts=3):
"""在多个端点间自动切换的韧性请求处理器"""
# 主端点和备用端点列表
endpoints = [
"https://vip.apiyi.com/v1/chat/completions",
# 备用端点 - 付费客户可联系客服获取
"备用端点1",
"备用端点2"
]
# 尝试所有端点
for endpoint in endpoints:
try:
print(f"尝试端点: {endpoint}")
response = requests.post(
endpoint,
json=payload,
headers=headers,
timeout=90
)
if response.status_code == 200:
print(f"请求成功 (端点: {endpoint})")
return response.json()
except Exception as e:
print(f"端点 {endpoint} 请求失败: {e}")
continue
print("所有端点均请求失败")
return None
为什么选择API易平台
API易平台在提供大模型API服务方面有以下优势:
1. 更强的网络稳定性
- 多区域部署:全球多个区域的服务节点
- 智能路由:自动选择最佳连接路径
- 专用带宽:付费用户享有优先带宽分配
- 自动容灾:节点故障自动切换
2. 完善的开发者支持
- 专业技术支持:快速响应开发者遇到的问题
- 调试工具:提供在线API调试工具
- 详细文档:全面的API文档和最佳实践指南
- 示例代码:多种编程语言的集成示例
3. 性价比优势
- 按量计费:精确到token的计费方式
- 多模型支持:一个API密钥访问多家顶级模型
- 灵活套餐:根据需求选择不同的使用计划
- 初始免费额度:注册即送试用额度
总结:打造稳定可靠的API调用环境
在使用大模型API开发应用过程中,连接稳定性和超时处理是关键挑战。通过本文提供的多种解决方案,您可以显著提高API调用的成功率和应用的用户体验。
从简单的增加超时时间,到实现智能重试机制,再到使用专用访问通道,这些方法可以根据您的具体需求和技术能力灵活选择。对于企业级应用,我们特别推荐联系客服获取专用访问通道,以获得最佳的连接稳定性。
API易平台将持续优化服务,提供更稳定、更高效的API调用体验。如有任何问题,欢迎随时联系我们的技术支持团队。
欢迎免费试用 API易,3 分钟跑通 API 调用 www.apiyi.com
解决API调用超时问题,实现稳定高效的大模型应用
加站长个人微信:8765058,发送你《大模型使用指南》等资料包,并加赠 1 美金额度。

本文作者:API易团队
欢迎关注我们的更新,持续分享 AI 开发经验和最新动态。